-> 23년 5월 리뷰, 23년 11월 추가 리뷰.
https://diffusion-planning.github.io/
Diffuser: Reinforcement Learning with Diffusion Models
Planning with Diffusion for Flexible Behavior Synthesis *equal contribution Variable-length planning Diffuser's planning horizon is determined by the size of the random noise used to initialize the denoising process. Flexible behavior synthesis Diffuser ac
diffusion-planning.github.io
0. Abstract
모델 기반 강화 학습 방법은 종종 대략적인 동적 모델을 추정하기 위한 목적으로만 학습된다.
의사 결정 작업의 나머지를 classical trajectory optimizer에게 맡긴다.
-> 개념적으로는 간단, but 경험적인 단점 多. standard trajectory optimization에 맞지 않다.
본 논문의 핵심 : 반복적으로 trajectory(궤적)을 noise 제거하여 계획하는 확산 확률 모델.
diffusion based planning 방법의 유용한 특성을 탐구 및 효과를 입증할 것이다.
1. Introduction
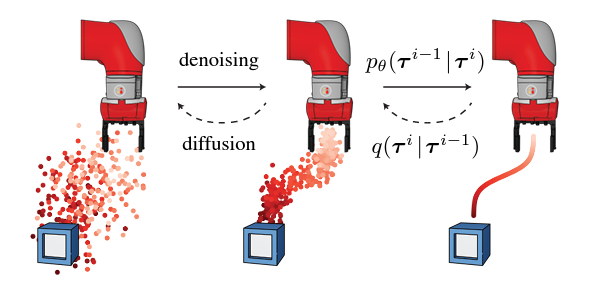
(1) 학습된 모델로 Planning하는 것은 강화 학습, 데이터 중심 의사-결정을 위한 간단한 프레임 워크이다.
supervised learning problem에 해당하는, unknown environment dynamics를 위해 학습 기술을 사용한다.
이후, 학습된 모델은 기존의 궤적 최적화 루틴에 plug-in될 수 있다.
(2) But, 이 조합은 설명된 대로 작동하지 않는다.
powerful trajectory optimizers는 learned model를 이용한다.
-> 이에 대한 결과는 [optimal 궤적]이라기 보다는 [adversarial 궤적]으로 보인다.
(3) 현재 모델 기반 강화 학습 알고리즘
[궤적 최적화 toolbox]보다는 [model-free methods]에서 더 많이 상속된다.
(4) 본 연구는 (데이터 구동 궤적 최적화를 위한) alternative approach를 제안한다.
core idea : 바로 궤적 최적화가 가능한 model을 훈련하는 것.
-> 모델의 샘플링과 모델의 planning이 거의 동일해진다는 점에서 ~
-> 이 모델은 궁극적으로 planning에 사용될 것이다. 단기 오류보다, 장기 정확도가 더 중요하다.
-> 또한 모델은 여러 작업에 사용될 수 있도록, reward function에 대한 불응성을 유지해야 한다.
-> 표준 모델 기반 planning은 시간의 미래를 자동적, 역행적으로 예측한다.
-> 그에 비해 Diffuser는 계획의 모든 시간 단계(all timesteps)를 동시에 예측한다.
[확산 모델의 반복적인 sampling process]는 [flexible conditioning]으로 이어진다. 샘플링 절차 수정 가능
(5) data-driven trajectory oprimization의 몇 가지 특성
Long-horizon scalability : [single step error]가 아닌, [궤적의 정확성]을 위해 훈련된다. 확장되는 훈련
Task compositionality : 보상 함수는 [plan을 sampling하는 동안] 보조 gradient를 제공한다.
gradient를 함께 추가, 여러 보상을 동일하게 구성함으로써 계획이 더 간단해진다.
Temporal compositionality : 지역 일관성을 개선 -> 전역 일관성을 지닌 궤적을 생성. 연결 -> 궤적 일반화
Effective non-greedy planning : model, planner사이의 경계를 모호히
-> model 예측을 향상시키는 훈련 과정이 planning 능력도 동시에 향상시킬 수 있다.
-> long-horizon, sparse-reward 문제를 해결할 수 있다.
(6) 연구의 핵심 기여
궤적 데이터에 맞게 설계된 확산 모델 + 행동 합성을 위한 관련 확률론적 프레임워크
심층 모델 기반 강화 학습에 일반적으로 사용되는 모델들보다 Diffuser는 더 유용한 특성을 가진다.
-> 특히 long-horizon추론, test-time 유연성이 필요한 제어 설정에 효과적이다.
23년 11월 : 이 모델은 궤적 최적화에 (직접적으로 적합한) 모델을 훈련시키는 것으로, 'sampling from the model'과 'planning with the model'이 거의 동일해져야 한다. 즉, 모델이 planning에 최종적으로 사용되기 때문에 action distribution(행동 분포)가 state dynamics(상태 동적)과 동등한 중요성을 갖는다. 또한 장기간 정확성이 single step 오차보다 더 중요하다. 또한 모델은 plan(계획)과 prediction(예측) 모두가 experience(경험)과 함께 개선되어야 한다.
standard model-based planning 기술이 시간에 따라 자기 회귀적으로 forward를 에측하는 반면 Diffuser는 plan의 모든 timesteps를 동시에 예측한다. 확산 모델이 반복 샘플링을 하면, flexible conditioning(유연한 조건 설정)을 이끌어 낸다.
-> 유연한 조건 설정이 뭐냐? 보조 가이드가 샘플링 과정을 수정하여 고수익(high return) 궤적을 복구하거나 일련의 제약 조건을 충족시킬 수 있도록 하는 것.
아무튼 이것은 '데이터 기반 궤적 최적화'이다. Denoising diffusion model(궤적 데이터에 대한 모델) + probabilistic framework(행동 합성을 위한 확률적 프레임워크). Diffuser가 유용한 특성을 가지며, 특히 장기적 추론(long-horizon reasoning)과 test-time flexibility(테스트 시간의 유연성)이 필요한 offline 제어 환경에서 효과적이다.
-> 오프라인 제어 환경 : 시스템이 실제로 실행되기 전에 훈련된 데이터를 사용하여 모델을 개발, 테스트하는 것. 실시간으로 데이터를 수집하지 않는다. 즉, 이미 수집된 데이터를 사용하여 모델 훈련, 평가하는 것. 이 훈련 데이터는 시스템이 오랜 시간 동안 어떻게 행동해야 하는지 정보가 있으므로, 장기적 추론 능력이 중요하다. 또한 오프라인에서 훈련된 모델이 예측할 수 없는 실제 환경에 적응하여야 하므로, 유연성 있는 모델이 필요하다. 다양한 환경에서 안정적으로 동작하게끔.
2. Background
궤적 최적화가 고려하는 문제 설정과 해당 문제에 사용하는 생성 모델의 클래스에 대한 간략한 배경을 제공.
(1) 문제 설정
system은 이산 시간 역학 st+1=f(st,at) 에 의해 지배된다고 가정하자.
궤적 최적화란? 단계별 보상(rewards or costs)을 최대화(Max or Min)하는 함수의 시퀀스를 찾는 것이다.
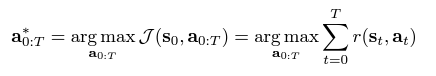
-> T : 계획 지평선
-> τ=(s0,a0,s1,a1,...,sT,aT) : interleaved(끼워진) 상태와 작용의 궤적
-> J(τ) : 해당 궤적의 목표값
23년 11월 : 궤적 최적화 공식은 위와 같다. 궤적 최적화란 목적 함수 J를 최대화(또는 최소화)하는 행동 시퀀스 a*0:T를 찾는 것이다. T는 계획 범위(planning horizon)이며, J(s0, a0, s1, a1, ..., sT, aT)는 해당 궤적의 목적 함수 값이다.
(2) DDPM
여기를 클릭하면 더 상세한 Diffusion Probabilistic Models 내용이 나와요.

23년 11월 : 아래의 공식은 점진적으로 노이즈를 걷어내는 denoising 절차이다. p(τN)는 표준 가우시안 사전 확률이고, τ0는 노이즈가 없는 데이터다. 매개변수 θ는 arg minθ−Eτ0logpθ(τ0)를 최소화하여 최적화된다.
-> 이 작업에는 2가지 'time' 이 사용된다. 하나는 diffusion process의 시간이고, 하나는 planning problem의 시간이다. 전자를 나타내기 위해 위첨자를 사용하고, 후자를 나타내기 위해 하위 첨자를 사용하자. 예를 들어 St0는 무잡음 궤적에서 t번째 상태를 나타낸다.

3. Planning with Diffusion
궤적 최적화 기법의 가장 큰 장애물 : 환경 역학에 대한 지식이 필요하다.
대부분의 학습 기반 방법은 [근사 역학 모델]을 학습하고, 이를 [기존의 계획 루틴]에 연결하여 장애물을 극복.
-> But, 학습된 모델은 [실측 모델에 적합한 알고리즘]에 적합하지 않은 경우가 多
-> planner는 [반대되는 사례를 찾아 학습된 모델을 악용하는 것]을 싫어한다.
따라서 우리는 [고적적인 planner의 학습 모델을 사용]하는 대신, [generative 모델링 프레임워크]에서 가정
-> planning이 sampling과 거의 동일해지도록 한다.
이를 위해, 궤적의 확산 모델인 pθ(τ)를 사용한다.
확산 모델의 반복적인 denoising 과정은 (형태의 교란된 분포에서) sampling을 통해 유연하게 조정 가능.

-> h(τ) : 사전 증거(관찰기록), 원하는 결과(목표도달거리), 최적화할 일반 함수(보상함수)에 대한 정보 포함
-> [물리적으로 현실적인 궤적]과 [높은 보상 궤적]을 모두 찾아야 한다.
-> 동역학 정보는 교란 분포 h(τ)와 분리되어 있음 -> pθ(τ)는 동일 환경에서 여러 작업에 사용될 수 있다.
23년 11월 : 궤적 최적화를 할 시 환경 동역학에 대한 지식이 필요하다. 대신 우리는 modeling과 planning을 더 강하게 결합한다. 가능한 많은 planning process를 생성 모델링 프레임워크로 통합하는 것이다. 궤적의 확산 모델 pθ(τ)를 사용하여 수행한다.
-> h(τ)는 사전 증거(관측 이력), 원하는 목표, 최적화할 일반적인 보상함수나 비용함수에 대한 정보를 포함한다. pθ(τ)에 따라 물리적으로 현실적인 궤적을 찾는 동시에 h(τ)에 따라 high 보상(또는 제약 조건을 충족하는) 궤적을 찾는다. 동적 정보가 왜곡 분포 h(τ)에서 분리되어 있기 때문에 단일 확산 모델 pθ(τ)은 동일한 환경에서 여러 작업에 재사용될 수 있다.
(1) A generative model for Trajectory planning
Temporal ordering : 궤적 모델에서 sampling과 planning 사이의 경계를 흐리게 하면 -> 비정상적 제약 발생. 즉, 시간순대로 자동 회귀적으로 상태를 예측할 수 있다.
p(s1|s0,sT) : 다음 상태 s1은 이전 상태뿐만 아니라, 미래 상태에도 의존한다.
동적 예측 : 현재가 과거에 의해 결정됨(비인과적), 현재가 미래의 조건부(반인과적)이다.
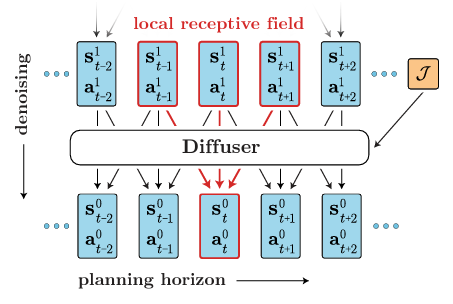
Temporal locality : 회귀적이거나 Markovian적이지 않음에도 -> Diffuser는 시간적 위치의 형태로 완화됨.
-> 이 그림은 single temporal convolution(단계적 시간 컨볼루션)으로 구성된다.
-> 주어진 예측의 수용 영역은 [과거와 미래의 가까운 time step]으로만 구성된다.
denoising precoess의 각 단계는 지역 일관성 기반으로 예측 가능. 많은 단계 -> 전역 일관성 유도 가능
Trajectory representation : Diffuser는 계획을 위해 설계된 궤적 모델, 모델 controller의 효율이 중요하다.
궤적의 상태, 동작은 공동으로 예측된다. 예측을 위한 동작 : 단순히 상태의 추가적인 dimension(차원)

Architecture : 디퓨저 아키텍처를 지정하는 데 필요한 요소 3가지
[1] 전체 궤적이 비회귀적으로 예측되어야 한다.
[2] denoising process의 각 단계가 시간적으로 local(국소적, 지역성 띰)이어야 한다.
[3] 궤적 표현이 one dimension(한 차원) 에서만 동일해야 한다. 다른 차원에서는 허용되지 X
Training : 확산 매개변수를 사용하여 궤적 노이즈 프로세스의 학습된 기울기 θ(τi,i)를 구한다.
이로부터 평균 µθ을 닫힌 형태로 해결할 수 있다.
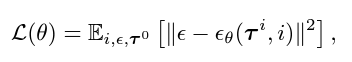
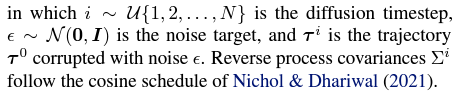
23년 11월 : Figure 사진 설명을 참고하자. 그리고 τ는 궤적의 모델로, 보다시피 궤적은 상태와 행동이 함께 예측된다. Diffuser의 입력 및 출력을 2차원 배열로 나타낼 수 있다.
(2) Reinforcement Learning as Guided Sampling
Ot가 time step 최적성을 나타내는 이항 랜덤 변수라고 가정한다.
아래 방정식에서 h(τ)=p(O1:T|τ) 를 설정하여 -> 최적 궤적 집합에서 샘플을 추출할 수 있다.
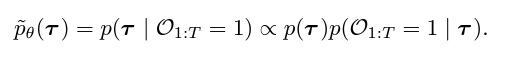
-> 즉, 강화 학습 problem을 조건부 샘플링 중 하나로 대체하였다.
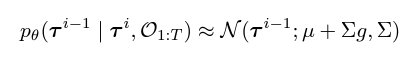
-> 수많은 논문에서 확산 모델을 사용한 조건부 샘플링 방법은 (정확한 표본 추출은 불가능하나)
p(O1:T|τi)가 매끄럽지 않다면, [reverse diffusion process transitions]를 [가우시안]으로 근사화 가능
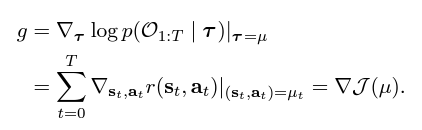
-> 이 관계는 [class-conditional(클래스 조건부) 이미지를 생성하는 데 사용되는 분류기 안내 샘플링]과
[강화 학습 문제 설정] 간의 간단한 변환을 제공한다.
[1] 모든 궤적 데이터의 상태, 동작에 대한 확산 모델 pθ(τ) 를 훈련한다.
[2] 궤적 샘플 τi의 누적을 예측하기 위해 별도의 모델 Jφ를 훈련한다.
-> Jφ 의 기울기 : reverse process의 평균값(µ)을 수정하여 궤도 샘플링 절차를 guide한다.
[3] 샘플링된 궤적 τ∼p(τ|O1:T=1) 의 첫 번째 동작은 환경에서 실행될 수 있다.
[4] 그 후 planning 절차는 [표준 선행 지평선 control loop]에서 다시 시작된다.

23년 11월 : Diffuser를 사용하여 RL 문제를 해결하기 위해 '보상'의 개념을 도입하자. Ot는 궤적의 특정 time step의 최적성을 나타내는 이진 랜덤 변수이고, p(Ot=1)는 상태행동 보상 함수값들의 평균이다. h(τ) = p(O1:T | τ)으로 설정함으로써 최적 궤적 집합에서 샘플링을 할 것이다. 이러면 강화 학습 문제를 조건부 샘플링 문제로 교환 가능하다. (두번째식) 또한 정확한 샘플링은 불가능하지만, p(O1:T | τi)가 충분히 부드러울 때 역확산 프로세스 전이를 가우시안으로 근사화할 수 있다. (세번째식)
먼저, 모든 사용 가능한 궤적 데이터의 상태와 행동에 대한 확산 모델 pθ(τ)를 훈련한다. 다음으로 별도의 모델인 Jφ를 훈련하여 궤적 샘플 τi의 누적 보상을 예측한다. Jφ의 그래디언트는 세번째 식에 따라 역프로세스의 평균 µ를 수정하여 궤적 샘플링 과정을 안내하는 데 사용된다. 샘플된 궤적 τ∼p(τ | O1:T=1)의 첫 번째 동작은 환경에서 실행될 수 있으며, 그 후 planning procedure는 standard receding-horizon control loop에서 다시 시작된다. 위의 알고리즘을 참고하라.
(3) Goal-Conditioned RL as Inpainting
우리 목표 : [보상 극대화]보다 [만족도에 대한 제약 조건]을 기준으로 궤적을 생성한다.
[상태, 동작 제약 조건]이 [이미지에서 관찰된 픽셀에 유하사게 작용하는 -> 그림 문제]로 변환될 수 있다.
array에서 관찰된 모든 location은 [관찰된 제약 조건과 일치하는 방식]으로 확산 모델에 의해 채워져야 함
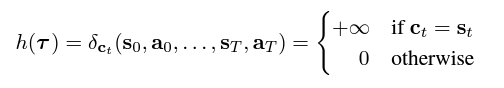
-> 모든 확산 시간 단계 si∈{0,1,...,N} 후에 샘플링된 값을 조건부 값 ct로 대체하여 구현 가능하다.
-> 짝수 보상 최대화 문제 : 모든 샘플링된 궤적은 현재 상태에서 시작해야 함 -> 조건화 (by 인페인팅) 필요
23년 11월 : 보상 최적화보다는 제약 조건을 만족시키는, 더 실행 가능한 궤적을 생성하자. 모든 샘플된 궤적이 현재 상태에서 시작해야하므로 모든 보상 최적화 문제도 인페인팅에 의한 조건부가 필요하다.
-> '인페인팅'은 일종의 그림 채우기 작업이다. 시간에 따라 상태와 행동이 나란히 나열된 이차원 배열인 궤적, 궤적의 일부 위치가 관측되었다고 가정하자. 그러면 나머지 위치는 '인페인트'하여 관측된 부분과 일관성을 유지하도록 채워져야 한다. 궤적을 디노이징하는 모델이 시간에 따라 유연하게 확산하면서 미래의 상태와 행동을 예측할 수 있기 때문이다. 다시 말해 '인페인팅'은 관측된 부분을 기반으로 나머지 부분을 추론하여 완전한 궤적을 만들어내는 과정을 의미한다.
4. Properties of Diffusion Planners
우리는 [표준 동역학 모델과 구별되거나] [자동 회귀 궤적 예측에 특이한 점]을 중심으로 디퓨저 속성 공부 중!!
(1) Learned long-horizon planning
Single-step(단일 단계) 모델은 모든 planning 알고리즘과 관련이 없다.
대조적으로 알고리즘1의 planning routine은 확산 모델의 특정 비용과 밀접하게 연관되어 있다.
논문 속 단어 : ground-truth의 의미가 궁금하다면? https://mac-user-guide.tistory.com/14
우리의 계획 방법은 샘플링과 거의 동일 -> effetive long-horizon planning이 이루어지면 된다.
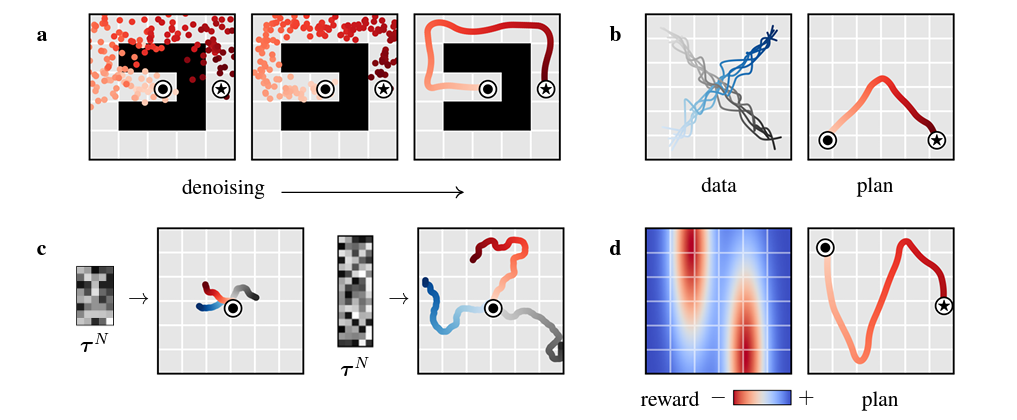
그림 3a : 목표 도달 설정에서 학습된 계획의 이점, 접근이 어려운 유형에서 디퓨저를 사용 -> 실현 가능.
(2) Temporal compositionality
Single-step(단일 단계) 모델은 Markov property를 사용, 동기를 부여, 분포 외 궤적 구성 가능하다.
Diffuser는 지역 일관성을 반복적으로 improve하여 전역 일관성을 지닌 궤적을 생성한다.
-> 익숙한 sussequances(후행)들을 새로운 방식으로 연결 가능
그림 3b : 직선으로만 이동하는 궤적에 Diffuser 적용, 교차점에서 궤적을 구성 -> 도형 궤적 일반화 가능
(3) Variable-length plans
prediction(적합도 예측) 영역에서 매우 convolutional하다.
planning(계획) 영역은 아키텍처 선택에 의해 지정되지 않는다.
대신 planning(계획) 영역은 [denoising process를 초기화하는] 입력 노이즈의 크기 τN∼N(0,I)에 의해
결정되므로 Variable-length plans가 가능하다.
(4) Task compositionality
확산 모델은 환경 역학 및 행동에 대한 정보를 포함, But 보상 함수와는 독립적이다.
확산 모델은 미래에 대해 선행적(prior)으로 작용 -> 다른 보상에 비해 가벼운 h(τ)에 의해 planning을 유도.
-> 확산 모델의 지속적인 학습을 통해, 새로운 보상 함수에 대한 계획을 수립함으로써 이를 입증 가능하다.
23년 11월 : Diffuser의 특성들. [1] 학습된 Long-horizon planning : 샘플링과 거의 동일한 planning 방법, 어려운 희소 보상 설정에서 실행 가능한 궤적을 생성할 수 있음을 보여준다. [2] 시간적 조립성 : 모델이 마르코프적이지 않더라도 지역 일관성을 반복적으로 개선함으로써 궤적을 생성하므로 일반적인 마르코프 모델과 관련된 일반화 유형을 보인다. 즉 훈련 데이터의 궤적 조각을 새로운 방식으로 조합하여 새로운 plan을 생성할 수 있다. [3] Variable-length plans : Diffuser의 planning horizon은 아키텍처에 의해 결정되지 않고, 입력 노이즈의 차원성을 변경함으로써 훈련 후에 동적으로 업데이트될 수 있다. [4] Task Compositionality : Diffuser는 새로운 보상 함수와 결합하여 훈련 중에 본 적이 없는 작업을 위해 plan할 수 있다.
5. Experimental Evaluation
실험의 초점은 데이터 기반 planner에서 원하는 기능에 대해 Diffuser의 다음 세 가지를 평가하는 것이다.
[1] 수동 보상 형성 없이 long horizon을 넓힐 수 있는 능력
[2] 훈련 중에 보지 못한 새로운 목표 구성을 일반화할 수 있는 능력
[3] 다양한 품질의 이질적인 데이터에서 effective controller를 복원할 수 있는 능력
(1) Long Horizon Multi-Task Planning
샘플된 궤적을 open-loop plan으로 사용한다. 다중 작업 유연성을 테스트하려면 각 에피소드의 시작 시 목표 위치를 무작위로 변화시키는 환경을 수정하면 된다. 결과적으로 Diffuser는 다중 작업 설정에서도 단일 작업 설정과 동일한 성능을 발휘한다.
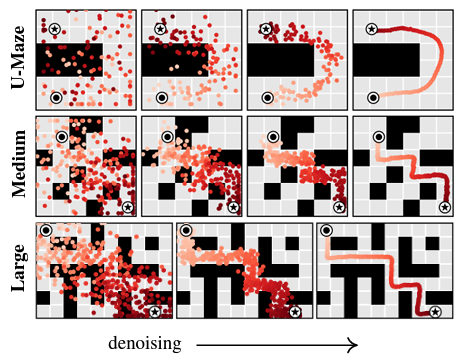

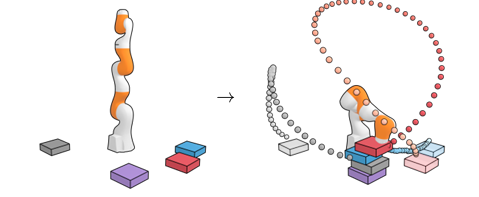
(2) Test-time Flexibility
블록 쌓기 작업을 수행하자. (1) Unconditional Stacking에서 작업은 가능한 한 큰 블록 탑을 구축하는 것이다. (2) Conditional Stacking에서 작업은 특정한 블록 순서로 블록 탑을 만드는 것이고 (3) Rearrangement에서 작업은 새로운 배열에서 참조 블록의 위치와 일치시키는 것이다. 보상은 성공적인 블록 배치에 대해서만 1이고 그렇지 않으면 0이다.
(3) Offline Reinforcement Learning
D4RL을 사용한다. Diffuser에 의해 생성된 궤적을 높은 보상 지역으로 유도하기 위해, 앞서 말한 샘플링 절차와 inpainting 절차를 사용하여 현재 상태에서 궤적을 조건부로 만든다. Reward predictor Jφ는 확산 모델과 동일한 궤적에서 훈련된다.
(4) Warm-StartingDiffusionforFasterPlanning
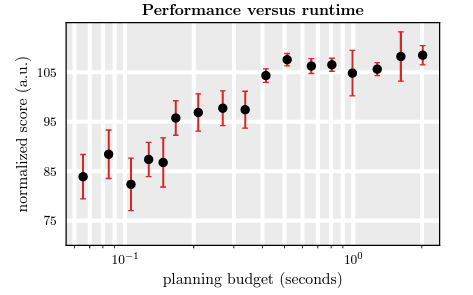
Diffuser의 한계는 반복적인 생성 때문에, 개별 계획을 생성하는 데 시간이 오래 걸린다는 것이다. 우리는 계획을 오픈 루프로 실행하는 동안 각 실행 단계마다 새로운 계획을 생성해야 한다. Diffuser의 실행 속도를 향상시키기 위해 이전에 생성된 계획을 재사용하여 이후 계획의 생성을 초기화할 수 있다. 계획을 초기화하려면 이전에 생성된 계획에서 일부 forward diffusion 단계를 실행한 다음 (부분적으로 노이즈가 추가된 궤적에서) 동일한 수의 denoising 단계를 실행하여 업데이트된 계획을 재생성할 수 있다. 아래 그림은 각 새로운 계획을 2에서 100까지의 denoising 단계를 사용하여 재생성한다. 사용되는 기본 수를 변화시키면서 성능과 실행 시간 예산 사이의 트레이드 오프를 설명한다.
6. Conclusion
Diffuser는 궤적 데이터를 위한 노이즈 제거 확산 모델이다. Diffuser를 사용한 계획은 샘플링과 거의 동일하며, 샘플을 안내하는 보조 노이즈 함수의 추가만 다르다. 학습된 diffusion-based planning 절차에는 sparse rewards(희소 보상)을 우아하게 처리하고 다시 교육하지 않고도 새로운 보상에 대한 계획을 세우는 능력 및 in-분포 서브 시퀀스를 이어 붙여 out-of-분포 궤적을 생성할 수 있는 시간적 조합성 등의 유용한 특성이 있다. 결과는 딥 모델 기반 강화 학습을 위한 새로운 클래스의 diffusion-based planning procedures를 가리킨다.
state(상태), action(동작),


