728x90
반응형
논문 코드 : https://github.com/Jonas-Nicodemus/PINNs-based-MPC
1. Initial settings
가상 환경에 접속한다. 아래 코드를 수행.
git clone git@github.com:Jonas-Nicodemus/PINNs-based-MPC
cd PINNs-based-MPC
pip install -r requirements.txt
(1) first error
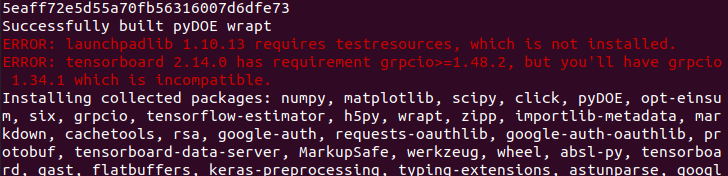
https://gist.github.com/y56/0540d22a1db40dacc7fbbb93c866821e
(2) second error

my mistake ! hahaha
pip install tensorflow
pip install matplotlib
pip install pyDOE
python main.py
2. Simulation result
(1) 코드 실행 결과
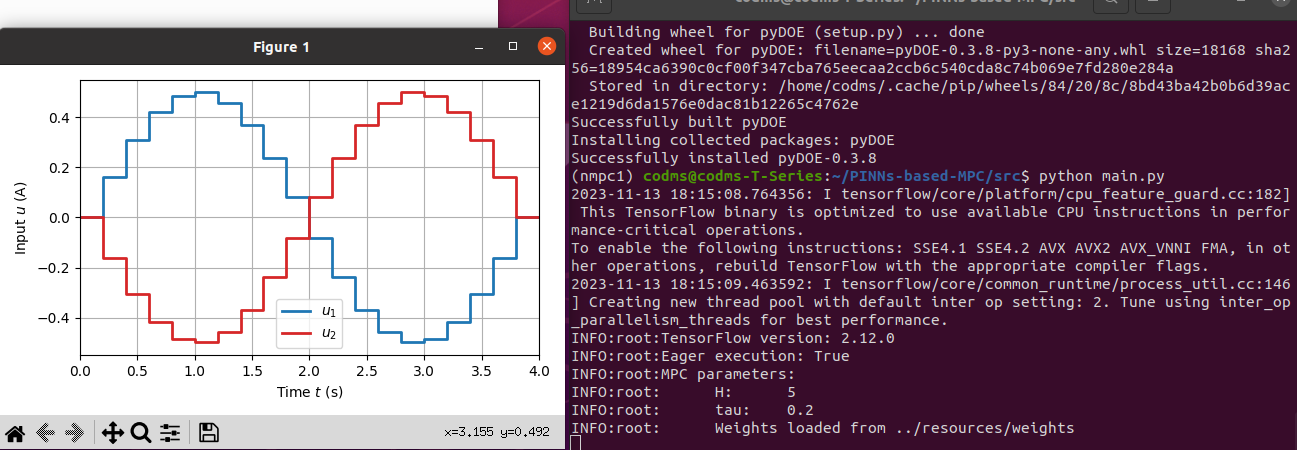
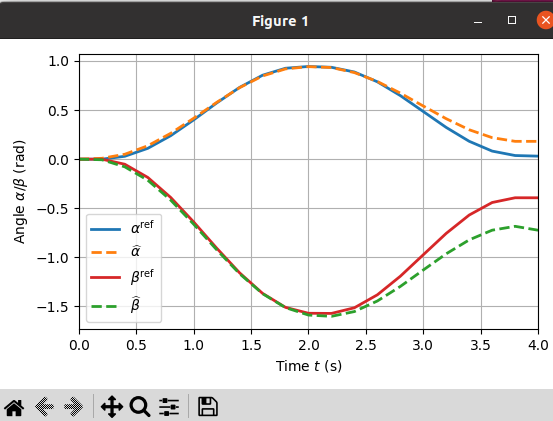


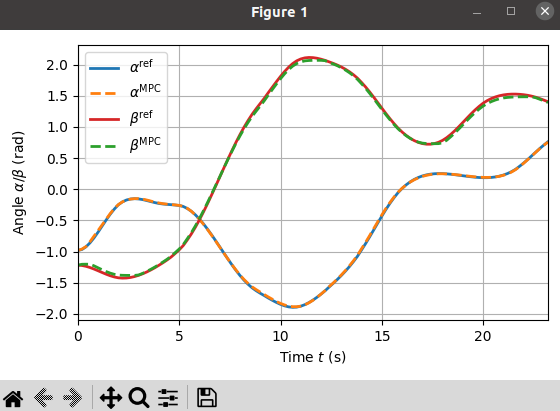

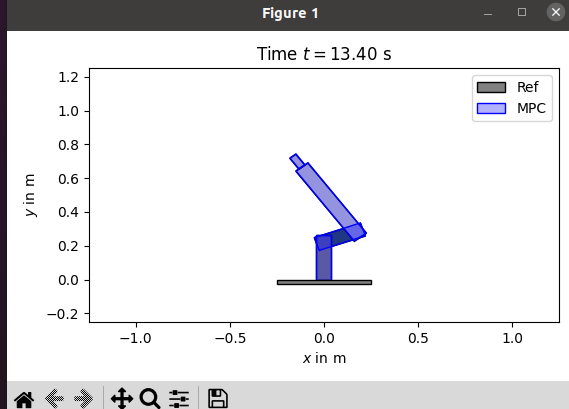
(2) 코드 분석
중요한 3개의 파일 위주로 분석할 것이다.
<train_pinn.py>
import os
import click
import logging
import time
import numpy as np
import tensorflow as tf
from model.pinn import PINN
from utils.data import generate_data_points, generate_collocation_points, load_data
from utils.plotting import animate, plot_states, plot_input_sequence, plot_absolute_error
from utils.system import M_tensor, k_tensor, q_tensor, B_tensor
# (로봇 메니퓰레이터의 동역학을 근사화하는) PINN 모델.
class ManipulatorInformedNN(PINN):
# 신경망의 레이어 크기, 입력 데이터의 하한 및 상한을 초기화.
def __init__(self, layers, lb, ub, X_f=None):
# layers : 뉴런 개수(신경망의 각 레이어 너비), 리스트.
# lb : 훈련 데이터의 입력 변수의 하한, ub : 상한.
# X_f : collocation points 나타내는 Numpy 배열.
super().__init__(layers, lb, ub)
self.t = None
self.x0 = None
self.u = None
if X_f is not None:
self.set_collocation_points(X_f)
# collocation points 설정, 주어진 X_f에서 시간, 초기상태, 입력을 설정.
def set_collocation_points(self, X_f):
self.t = self.tensor(X_f[:, 0:1])
self.x0 = self.tensor(X_f[:, 1:5])
self.u = self.tensor(X_f[:, 5:7])
@tf.function
# PINN의 모델, 로봇의 운동 방정식을 근사화.
def f_model(self, X_f=None):
# M : 관성 텐서, k : 감쇠 및 탄성 관성, q : 위치, u : 외부 입력, y : 로봇의 상태
# M*D2q + k = q + B*u
# y = [q1; q2; dq1_dt; dq2_dt]
if X_f is None:
t = self.t
x0 = self.x0
u = self.u
else:
t = self.tensor(X_f[:, 0:1])
x0 = self.tensor(X_f[:, 1:5])
u = self.tensor(X_f[:, 5:7])
i_PR90 = tf.ones(len(t), dtype=tf.float64) * 161
with tf.GradientTape(persistent=True) as tape: # 그래디언트 계산 범위 설정.
tape.watch(t)
y_pred = self.model(tf.concat([t, x0, u], axis=1))
q1 = y_pred[:, 0:1]
q2 = y_pred[:, 1:2]
dq1_dt = y_pred[:, 2:3]
dq2_dt = y_pred[:, 3:4]
dq_dt = tf.stack([dq1_dt, dq2_dt], axis=1)
# 상태변수 및 시간 미분 추출.
dq1_dt_tf = tape.gradient(q1, t)[:, 0]
dq2_dt_tf = tape.gradient(q2, t)[:, 0]
dq_dt_tf = tf.stack([dq1_dt_tf, dq2_dt_tf], axis=1)
d2q1_dt_tf = tape.gradient(dq1_dt, t)[:, 0]
d2q2_dt_tf = tape.gradient(dq2_dt, t)[:, 0]
d2q_dt_tf = tf.stack([d2q1_dt_tf, d2q2_dt_tf], axis=1)
# 각 변수에 대한 시간 미분 계산.
M_tf = M_tensor(q2[:, 0], i_PR90)
k_tf = k_tensor(dq1_dt_tf, q2[:, 0], dq2_dt_tf)
q_tf = q_tensor(q1[:, 0], dq1_dt_tf, q2[:, 0], dq2_dt_tf)
B_tf = B_tensor(i_PR90)
# 텐서 계산.
# 최종 예측, 운동 방정식의 오차.
# PINN 모델이 학습해야 하는 물리적인 근사치.
f_pred = tf.concat([dq_dt_tf - dq_dt[:, :, 0],
tf.linalg.matvec(M_tf, d2q_dt_tf) + k_tf - q_tf - tf.linalg.matvec(B_tf, u)], axis=1)
return f_pred #PINN의 예측을 반환.
# 가중치를 로드할 것인지, or 네트워크를 훈련할 것인지 설정.
if __name__ == "__main__":
LOAD_WEIGHTS = True # 가중치 로드 여부.
TRAIN_NET = False # 네트워크 훈련 여부.
logging.getLogger().setLevel(logging.INFO)
logging.getLogger('matplotlib').setLevel(logging.WARNING)
logging.info("TensorFlow version: {}".format(tf.version.VERSION))
logging.info("Eager execution: {}".format(tf.executing_eagerly()))
# 하이퍼파라미터 설정, 로그에 출력.
N_train = 2
epochs = 500000
N_phys = 20000
N_data = 100
logging.info(f'Epochs: {epochs}')
logging.info(f'N_data: {N_data}')
logging.info(f'N_phys: {N_phys}')
# 데이터 경로, 가중치 저장 경로.
data_path = os.path.join('../resources/data.npz')
weights_path = os.path.join('../resources/weights')
lb, ub, input_dim, output_dim, X_test, Y_test, X_star, Y_star = load_data(data_path)
# 신경망 레이어 구조 설정 및 PINN 모델 초기화.
N_layer = 4
N_neurons = 64
layers = [input_dim, *N_layer * [N_neurons], output_dim]
pinn = ManipulatorInformedNN(layers, lb, ub)
if LOAD_WEIGHTS:
pinn.load_weights(weights_path)
# PINN training (가중치 로드)
if TRAIN_NET:
for i in range(N_train):
# 각 에포크에서 LHS(Latin Hypercube Sampling) 사용하여 훈련데이터 생성.
# collocation points 설정하여 PINN 훈련.
X_data, Y_data = generate_data_points(N_data, lb, ub)
X_phys = generate_collocation_points(N_phys, lb, ub)
pinn.set_collocation_points(X_phys)
logging.info(f'\t{i + 1}/{N_train} Start training of the PINN')
start_time = time.time()
pinn.fit(X_data, Y_data, epochs, X_star, Y_star, optimizer='lbfgs', learning_rate=1,
val_freq=1000, log_freq=1000)
# PINN Evaluation (네트워크 훈련)
# 테스트 데이터에 대한 예측 수행.
Y_pred, F_pred = pinn.predict(X_test)
t_step = X_test[1, 0] - X_test[0, 0]
tau = 0.2
T = np.arange(t_step, 20 * tau + t_step, t_step)
plot_input_sequence(T, X_test[:, 5:])
plot_states(T, Y_test, Y_pred)
plot_absolute_error(T, Y_test, Y_pred)
animate(Y_test[::10], [Y_pred[::10]], ['PINN'], fps=1 / (10 * t_step))
if click.confirm('Do you want to save (overwrite) the models weights?'):
pinn.save_weights(os.path.join(weights_path, 'easy_checkpoint'))
<main.py>
import logging
import os
import numpy as np
import tensorflow as tf
from controller.mpc import MPC
from train_pinn import ManipulatorInformedNN
from utils.data import load_ref_trajectory, load_data
from utils.plotting import plot_input_sequence, plot_states, plot_absolute_error, animate
from utils.system import f
if __name__ == "__main__":
logging.getLogger().setLevel(logging.INFO)
logging.getLogger('matplotlib').setLevel(logging.WARNING)
logging.info("TensorFlow version: {}".format(tf.version.VERSION))
logging.info("Eager execution: {}".format(tf.executing_eagerly()))
# 데이터 경로, 가중치 경로 설정 및 데이터 로드.
resources_path = os.path.join('../resources')
data_path = os.path.join(resources_path, 'data.npz')
weights_path = os.path.join('../resources/weights')
lb, ub, input_dim, output_dim, _, _, _, _ = load_data(data_path)
# 하이퍼파라미터 설정 및 로깅.
# MPC에 필요한 초기 상태 및 제어 입력을 설정.
N_l = 4
N_n = 64
layers = [input_dim, *N_l * [N_n], output_dim]
logging.info('MPC parameters:')
H = 5
logging.info(f'\tH:\t{H}')
u_ub = np.array([0.5, 0.5])
u_lb = - u_ub
X_ref, T_ref = load_ref_trajectory(resources_path)
x0 = X_ref[0]
T_ref = T_ref[:-H, 0]
tau = T_ref[1] - T_ref[0]
logging.info(f'\ttau:\t{tau}')
# PINN 및 MPC 객체를 초기화.
pinn = ManipulatorInformedNN(layers, lb, ub)
# 미리 학습된 PINN 가중치 로드.
pinn.load_weights(weights_path)
controller = MPC(f, pinn.model, u_ub=u_ub, u_lb=u_lb,
t_sample=tau, H=H,
Q=tf.linalg.tensor_diag(tf.constant([1, 1, 0, 0], dtype=tf.float64)),
R=1e-6 * tf.eye(2, dtype=tf.float64))
# 자체 루프 예측(self loop prediction) 테스트.
H_sl = 20
# 입력 시퀀스 생성.
U1_sl = 0.5 * np.sin(np.linspace(0, 2 * np.pi, H_sl))
U2_sl = - U1_sl
U_sl = np.hstack((U1_sl[:, np.newaxis], U2_sl[:, np.newaxis]))
x0_sl = np.zeros(4) # 초기 상태.
# plant system 시뮬레이션.
X_ref_sl = controller.sim_open_loop_plant(x0_sl, U_sl, t_sample=tau, H=H_sl)
# PINN system 시뮬레이션.
X_sl = controller.sim_open_loop(x0_sl, U_sl, t_sample=tau, H=H_sl)
T_sl = np.arange(0., H_sl * tau + tau, tau)
plot_input_sequence(T_sl, U=np.vstack((U_sl, U_sl[-1:, :])))
plot_states(T_sl, X_ref_sl, X_sl)
plot_absolute_error(T_sl, X_ref_sl, X_sl)
# 닫힌 루프(closed loop) 제어 시스템 테스트.
X_mpc, U_mpc, X_pred = controller.sim(x0, X_ref, T_ref)
plot_input_sequence(T_ref, U_mpc)
plot_states(T_ref, X_ref[:-H], Z_mpc=X_mpc)
plot_absolute_error(T_ref, X_ref[:-H], Z_mpc=X_mpc)
animate(X_ref[:-H], [X_mpc], ['MPC'], fps=1 / tau)
<mpc.py>
동적 모델 ('plant')과 추정 모델('model')을 활용하여 로봇 제어를 시뮬레이션하는 MPC 클래스.
import logging
import time
import numpy as np
import tensorflow as tf
from scipy.integrate import solve_ivp
class MPC:
# MPC 클래스의 인스턴스 초기화.
def __init__(self, plant, model, u_ub, u_lb, t_sample=0.1, H=10,
Q=tf.eye(1, dtype=tf.float64), R=tf.eye(1, dtype=tf.float64)):
self.plant = plant # 물리적 시스템의 동적 모델.
self.model = model # 뉴럴 네트워크 모델, 상태 예측에 사용.
self.H = H # 제어 입력의 예측 단계 수 (디폴트:10)
self.t_sample = t_sample # 샘플링 간격 (디폴트:0.1)
self.optimizer = tf.keras.optimizers.RMSprop()
self.u_ub = u_ub
self.u_lb = u_lb
self.input_dim = len(self.u_ub) # 제어 입력 차원.
# 모델에서 최적화될 제어 입력, 초기값은 0. 크기는 (H, input_dim).
self.u = tf.Variable(initial_value=np.zeros((self.H, self.input_dim)), name='u', trainable=True,
dtype=tf.float64)
# cost function에서 상태의 차이를 가중치 부여하는 행렬.
self.Q = tf.convert_to_tensor(Q, dtype=tf.float64)
# cost function에서 제어 입력의 제곱을 가중치 부여하는 행렬.
self.R = tf.convert_to_tensor(R, dtype=tf.float64)
self.solving_times = {} # 최적화까지 걸린 시간.
def costs(self, x_ref, x_pred):
# MPC의 cost function 계산에 사용.
# '단계 비용'과 '최종 비용'은 각각 가중치 행렬 Q, R에 의해 조절됨.
# x_ref : 참조 상태, x_pred : 예측된 상태.
J = tf.reduce_sum(tf.square(x_ref - x_pred) @ self.Q) \
+ tf.reduce_sum(tf.square(self.u) @ self.R)
return J
def solve_ocp(self, x0, x_ref, iterations=1000, tol=1e-8):
# 최적 제어 문제(OCP) 해결에 사용.
# cost function이 수렴할 때까지 or 최대 반복 횟수에 도달할 때까지 최적화 단계 반복.
J_prev = -1 # 이전 비용 초기화.
for epoch in range(iterations):
J, x_pred = self.optimization_step(x0, x_ref)
if np.abs(J - J_prev) < tol: # tol : 허용 오차.
return J, x_pred
J_prev = J
return J, x_pred
@tf.function
def optimization_step(self, x0, x_ref):
# 한 번의 최적화 단계를 수행하는 역할.
with tf.GradientTape() as tape:
# 시스템 예측 상태 및 비용 함수 계산.
x_pred = self.sim_open_loop(x0, self.u, t_sample=self.t_sample, H=self.H)
cost = self.costs(x_ref, x_pred)
gradients = tape.gradient(cost, self.u) # 제어 입력 'self.u'의 그래디언트 계산.
self.optimizer.apply_gradients(zip([gradients], [self.u]))
self.ensure_constraints()
return cost, x_pred # 최적화된 비용, 예측 상태를 반환.
def ensure_constraints(self):
# 제어 입력의 제약 조건 확인 및 조정하는 역할.
for k in range(self.H):
for i, u_ub_i in enumerate(self.u_ub):
# 상한 값 이하로 조정.
if self.u[k, i] > u_ub_i:
self.u[k, i].assign(u_ub_i)
for i, u_lb_i in enumerate(self.u_lb):
# 하한 값 이상으로 조정.
if self.u[k, i] < u_lb_i:
self.u[k, i].assign(u_lb_i)
def sim(self, x0, X_ref, T_ref):
# MPC를 사용하여 시스템 시뮬레이션 및 결과 반환.
N = len(T_ref)
X_mpc = np.zeros((N, len(x0)))
X_pred = np.zeros((N, len(x0)))
U_mpc = np.zeros((N, self.u.shape[1]))
X_mpc[0] = x0 # 초기 상태 저장.
X_pred[0] = x0
U_mpc[0] = self.u[0].numpy() # 초기 제어 입력 값 저장.
for i, t in enumerate(T_ref[:-1]):
start_time = time.time()
# 현재 상태에서 MPC를 사용하여 최적의 제어 입력 및 예측 상태 계산.
J, x_pred = self.solve_ocp(X_mpc[i], X_ref[i:i + self.H + 1])
ocp_solving_time = time.time() - start_time # 최적화 소요 시간.
self.solving_times[i] = ocp_solving_time
u_k = self.u[0]
# 현재 상태에서 실제 시스템을 시뮬레이션, 실제 상태 계산.
x_true = self.sim_plant_system(X_mpc[i], u_k, self.t_sample)
X_pred[i + 1] = x_pred[1] # MPC에서 예측한 다음 상태.
X_mpc[i + 1] = x_true # 실제 시스템에서 계산한 다음 상태.
U_mpc[i + 1] = u_k.numpy() # 다음 제어 입력.
log_str = f'\tIter: {str(i + 1).zfill(len(str(N - 1)))}/{N - 1},\tJ: {J:.2e},' \
f'\tt: {t + self.t_sample:.2f} s,'
for i in range(len(u_k)):
log_str = log_str + f'\tu{i + 1}: {u_k.numpy()[i]:.2f},'
for i in range(int(len(x_true) / 2)):
log_str = log_str + f'\tx{i + 1}(t, u): {x_true[i]:.2f},'
log_str = log_str + f'\tOCP-solving-time: {ocp_solving_time:.2e} s'
logging.info(log_str)
return X_mpc, U_mpc, X_pred # MPC 시뮬레이션 결과 반환.
def sim_plant_system(self, x0, u, tau):
# 초기 상태, 제어 입력을 사용하여 실제 시스템의 동역학 시뮬레이션.
ivp_solution = solve_ivp(self.plant, [0, tau], x0, args=[u])
z_true = np.moveaxis(ivp_solution.y[:, -1], -1, 0)
return z_true
def sim_open_loop(self, x0, u_array, t_sample, H):
# 초기 상태, 제어 입력 배열을 사용하여 모델 시스템을 open loop로 시뮬레이션.
t = tf.constant(t_sample, dtype=tf.float64, shape=(1, 1))
x_i = tf.expand_dims(x0, 0)
X_pred = x_i
for i in range(H):
x = tf.concat((t, x_i, u_array[i:i + 1]), 1)
x_pred = self.model(x)
X_pred = tf.concat((X_pred, x_pred), 0)
x_i = x_pred
return X_pred
def sim_open_loop_plant(self, x0, u_array, t_sample, H):
# 초기 상태, 제어 입력 배열을 사용하여 실제 시스템을 open loop로 시뮬레이션.
x_i = x0
X = x_i
for i in range(H):
x = self.sim_plant_system(x_i, u_array[i], t_sample)
X = np.vstack((X, x))
x_i = x
return X
728x90
반응형



