해당 논문 링크 : https://arxiv.org/abs/2208.06193
Diffusion Policies as an Expressive Policy Class for Offline Reinforcement Learning
Offline reinforcement learning (RL), which aims to learn an optimal policy using a previously collected static dataset, is an important paradigm of RL. Standard RL methods often perform poorly in this regime due to the function approximation errors on out-
arxiv.org
해당 코드 링크 : https://github.com/Zhendong-Wang/Diffusion-Policies-for-Offline-RL
GitHub - Zhendong-Wang/Diffusion-Policies-for-Offline-RL
Contribute to Zhendong-Wang/Diffusion-Policies-for-Offline-RL development by creating an account on GitHub.
github.com
0. Abstract
오프라인 강화 학습(RL)은 강화학습의 중요한 패러다임으로, 이전에 수집된 정적 데이터 세트를 사용하여 최적의 정책을 학습한다. 표준 RL 방법은 분포 외 행동에 대한 함수 근사치 오류로 인해, 성능이 저하될 수 있다. 이 문제를 해결하기 위해 다양한 정규화 방법이 제안되었지만, 이들은 표현력이 제한된 정책 클래스에 제약을 받아(It was constrained by policy classes with limited expressiveness) 사용되지 못했다. 이 논문에서는 최근 표현력이 뛰어난 심층 생성 모델로 알려진 diffusion model로 정책을 표현할 것이다. 조건부 확산 모델을 활용하여 정책을 표현하는 Diffusion-QL을 소개한다. 이 접근 방식에서는 [1] 행동 가치 함수를 학습하고, [2] 조건부 확산 모델의 학습 손실(training loss)에 행동 가치(action - values)를 최대화하는 항을 추가한다. 그러면 행동 정책에 가까운 최적의 행동을 찾는 손실이 발생한다. 확산 모델 기반 정책의 표현력과, 확산 모델에 따른 행동 복제 및 정책 개선의 결합이 모두 성능을 좋게 한다는 결과가 도출되었다. 멀티 모달 행동 정책을 사용하는 간단한 2D 도둑 예제를 통해, 기존 연구와 비교하여, 우리 방법의 우수성을 설명할 것이다. 그 후, 우리의 방법이 대부분의 D4RL 벤치마크 작업에서 최첨단 성능을 달성할 수 있음을 보여준다.
1. Introduction
Offline RL은 환경과 상호작용하지 않고, 이전에 수집된 데이터로부터 정책을 학습한다. Offline RL은 (훈련되지 않은 정책으로 실제 세계를 탐색하는 것이 위험하고, 비용이 많이 드는) 자율 주행 및 환자 치료 계획과 같은 광범위한 실제 응용 프로그램에 이점을 보인다. Offline RL은 훨씬 저렴한 비용으로 사전 데이터의 사용을 강조하지만, 이전에 수집된 데이터에만 의존하는 것은 어렵다. . 이러한 다양한 이유로 Offline RL에 대한 순진한 접근 방식은 잘못된 정책을 학습하는 등 성능이 만족스럽지 못하다.
Offline Rl에 대한 이전 연구는 크게 4가지로 나뉜다. [1] 정책이 행동 정책에서 얼마나 벗어날 수 있는지 정규화, [2] 학습된 가치 함수를 제한하여 분배 외 행동에 낮은 값을 할당하도록 제한, [3] 학습된 Markov 의사결정 과정(MDP)에서 모델을 학습하고 비관적인 계획 수행, [4] 오프라인 RL을 시퀀스 예측 문제로 처리. 우리는 첫번째 범주로 접근할 것이다.
우리는 diffusion loss에 두 가지 항을 포함했다. [1] 확산 모델이 훈련 세트와 동일한 분포에서 행동을 샘플링하도록 장려하는 behavior-cloning term, [2] 높은 가치의 행동을 샘플링하려고 시도하는 policy improvement term이다. diffusion model은 상태를 조건으로 하고, 동작을 출력으로 하는 조건부 모델이다. diffusion의 3가지 특성을 말해보자면 [1] 매우 표현적이고 다중 모델 분포를 잘 포착할 수 있다. [2] diffusion model loss는 강력한 분포 매칭 기법을 구성하므로 추가적인 행동 복제가 필요 없는 정책 정규화(policy regularization) 방법이다. [3] 반복 정제를 통해 생성을 수행하며, Q-value function을 극대화하는 guidance가 각 reverse diffusion step에서 추가될 수 있다.
요약하자면, diffusion model을 활용하여 정확한 정책 정규화(policy regularization)를 달성하고, reverse process 과정에 Q-learning guidance를 주입하여 최적의 행동을 찾게 한다. 이 알고리즘은 대부분의 작업에서 기존 방법보다 성능이 우수함을 보여준다.
2. Preliminaries and Related Work
(1) Offline RL
기존의 Online RL과는 다른 접근 방식을 취한다. Online RL은 에이전트가 환경과 실시간으로 상호작용하면서 데이터를 수집하고 학습한다. 또한 에이전트는 현재 정책에 따라 환경과 상호작용하고, 얻은 경험 데이터를 사용하여 정책을 업데이트한다. 이는 실시간 응용 프로그램 및 실제 환경에서의 에이전트 학습에 적합하다. 반면에 Offline RL은 사전에 수집된, 고정된 데이터 집합을 기반으로 에이전트를 학습한다. 에이전트는 환경과 상호작용하지 않고, 주어진 데이터를 활용하여 정책을 학습한다. 주로 과거 경험 데이터를 활용하여 새로운 정책을 학습하거나, 개선하는데 사용된다. 에이전트의 정책 개선을 안정적으로 수행할 순 있으나, 데이터의 분포가 변하는 경우에는 문제가 발생할 수 있다. 추가로 Offline DRL은 기존의 Offline RL을 딥러닝 기술과 함께 사용하는 것이다. 사전에 수집된 대규모의 데이터 집합을 사용하여 딥러닝 신경망 모델을 학습, 정책 또는 가치 함수를 근사화한다. 그 다음 학습된 딥러닝 모델을 통해 보상을 최대화하도록 정책을 개선하거나, 최적 가치 함수를 추정한다.
내용
-> 참고로, Offline RL은 데이터 수집 과정에서 미리 수집된 '배치(batch)' 형태의 데이터 집합을 사용한다. 에이전트는 환경과 실시간 상호작용을 하지 않는다. 아무튼 이러한 데이터 집합을 '배치'라고 부르며, 이를 활용하여 학습하는 것을 강조하기 위해 'Batch RL'이라고도 부른다.
(2) Diffusion Model
내용
-> Diffusion model로 logP(a|s)를 계산하는 것이 가능한가? 일반적인 확산 모델에서 logP(a0t|st)는 분석 확률 밀도 함수를 갖지 않는다. 각 확산 단계에서 신경망 기반 비선형 변환을 하기 때문이다. 그러나 P(a0t|st)는 semi-implicit(반 암시적) 분포로 공식화할 수 있다. 첫번째 계층은 분석적 가우스 분포이며, 매개변수는 이후의 모든 역확산 계층으로 구성된 implicit 분포에서 아이덴티티를 도출할 수 있다. 해당 논문의 방법에 따라 반 암시적 분포의 경우, 몬테카를로 추정을 통해 logP(a0t|st)의 하한/상한을 구하고, 그 값을 근사화할 수 있다.
(3) Related Work: Policy Regularization
내용
(4) Related Work: Diffusion Models in RL
내용
3. Diffusion Q-Learning
아래에서는 행동 복제에 대한 명시적 정책으로 conditional diffusion model을 적용하는 방법을 설명한다. 그다음 훈련 단계에서 diffusion model 학습에 행동 복제와 함께 Q-learning 가이드를 추가하여 정책 정규화(Policy Regularization)의 한 형태로 작동시킬 것이다.
(1) Diffusion Policy
이 작업에서는 확산 과정과 강화학습의 2가지 유형의 time step이 있으므로, diffusion time step을 나타내기 위해 i∈{1,...,N}를, trajectory time step을 나타내기 위해 t∈{1,...,T}를 사용한다. conditional diffusion model의 역과정을 통해 RL 정책을 다음과 같이 표현한다. 여기서 역과정의 마지막 샘플인 a0는 RL 평가에 사용되는 행동이며, pθ(ai-1|ai,s)는 가우시안 분포 N(ai-1;µθ(ai,s,i),Σθ(ai,s,i))로 모델링할 수 있으므로 다음 공식처럼 표현한다.

공분산 행렬을 Σθ(ai,s,i)=βiI로 고정하고, 평균을 아래 공식으로 구성한 노이즈 예측 모델로서 pθ(ai-1|ai,s)를 매개변수화한다.

먼저 aN∼N(0,I)을 샘플링한 다음, θ로 매개변수화된 reverse diffusion chain에서 아래 공식으로 샘플링한다.

DDPM 논문과 동일하게, i=1일 때 ϵ는 샘플링 품질을 개선하기 위해 0으로 설정된다. 또한 DDPM 논문에서 제안한 단순화된 목표를 모방하여, 아래 식을 통해 conditional ϵ-model을 훈련한다.
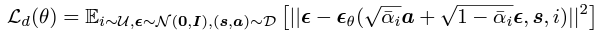
여기서 U는 {1,...,N}과 같은 이산 집합에 대한 균등 분포이고, D는 행동 정책 πb에 의해 수집된 오프라인 데이터 집합을 나타낸다. 디퓨전 모델의 loss Ld(θ)는 행동 복제 손실로, 행동 정책 πb(a|s)를 학습하는 것을 목표로 한다. 즉, 훈련 데이터와 동일한 분포에서 샘플 행동을 찾으려 한다. 다만 [1] 역확산 체인은 복잡한 분포 특성(왜곡 및 다중 양식)을 포착할 수 있는 너무 과하게 암시적이고.. 표현적인.. 분포를 제공한다는 유의점이 있다. 또한 [2] 정규화는 샘플링 기반이므로 D와 현재 정책 모두에서 무작위 샘플을 추출하기만 하면 된다. (이게 왜 단점이냐면.. 이 방법은 행동 정책을 알 필요가 없다.. 그래서 사람이 직접 데모를 통해 데이터 세트를 수집하는 경우 실행이 불가능할 수 있다..) 그래도 일반적인 two-step 전략과 달리, 이 전략은 유연한 정책에 정규화를 적용할 수 있는 깔끔하고 효과적인 방법이다.
-> 일반적인 two-step 전략이란? 강화학습에서 정책을 학습하고, 업데이트하는 방법 중 하나로, 유연한 정책을 다룰 때 어려움을 겪을 수 있는 문제에 대한 대안적인 접근법이다. DPG, TRPO, PPO, C51 알고리즘 등이 있다. 이런 알고리즘들은 어려운 태스크나 고차원 행동 공간에서 효과적이지만, 특정 문제와 상황에 따라 성능이 다를 수 있다.
각 데이터 포인트에 대해 단일 확산 단계 i를 샘플링하여 Ld(θ)를 효율적으로 최적화할 수 있다. 그러나 equation (1)의 역 샘플링은 ϵθ 네트워크를 N번 반복적으로 계산해야 하므로 런타임에 병목 현상이 생길 수 있다. 따라서 N을 상대적으로 작은 값으로 제한하는 것이 좋다. βmin=0.1, βmax=10.0의 작은 N으로 작업하려면 DDPM 논문을 따라 알파를 아래처럼 정의하자.

(2) Q-Learning
policy-regularization loss Ld(θ)는 behavior-cloning term이지만, 학습 데이터를 생성한 행동 정책을 능가할 수 있는 정책을 학습하진 못한다. 정책을 개선하기 위해, 우리는 훈련 단계의 reverse diffusion chain에 Q-value function을 주입한다. 높은 값을 가진 행동을 우선적으로 샘플링하기 위해서다. 최종 정책 학습 목표는 정책 정규화(policy regularization)와 정책 개선(policy improvement)의 선형적인 조합이다.

a0는 equation (1)에 의해 재파라미터화되므로, 동작(action)에 대한 Q-value function의 기울기는 전체 diffusion chain을 통해 역전파된다는 점을 유의하자.
Q-value function의 스케일은 오프라인 데이터 세트마다 다르기 때문에 이를 정규화하자. α를 α= η/ E(s,a)∼D[|Qϕ(s,a)|]로 설정한다. 여기서 η는 두 손실 항의 균형을 맞추는 초모수이고 분모의 Q는 정규화 전용이며 미분하지 않는다. Q-value function 자체는 기존 방식으로 학습되어 Bellman operator를 최소화한다. 우리는 두 개의 Q-네트워크인 Qϕ1, Qϕ2와 목표 네트워크인 Qϕ′ 1, Qϕ′ 2, πθ′를 구축했다. 그런 다음 아래의 목표를 최소화하여 i={1,2}에 대해 ϕi를 최적화한다.
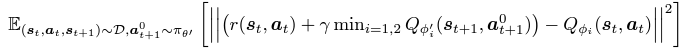
이제 섹션 4와 5에서 광범위한 실험을 수행할 것이다. 실험을 통해 Ld와 Lq가 함께 작동하여 최상의 성능을 달성하는 것을 보일 것이며, 아래는 구현을 요약한 알고리즘이다.

알고리즘 설명 : πθ는 현재 정책을, πθ'는 타겟 정책을 나타낸다. 정책 네트워크, 가치 함수 네트워크, 타겟 네트워크를 초기화한다. [1] 경험 데이터셋 D에서 미니 배치 B를 무작위로 샘플링한다. 이 미니 배치는 상태(st), 행동(at), 보상(rt), 다음 상태(st+1)로 구성된다. [2] 타겟 정책 πθ′를 사용하여 다음 시간 단계에서의 행동 a0t+1을 샘플링한다. Q-learning의 원칙을 따라 가치 함수 네트워크 Qϕ1 및 Qϕ2를 업데이트한다. [3] 현재 정책 πθ를 사용하여 현재 시간 단계에서의 행동 a0 t를 샘플링한다. equation (3)를 최소화하며 정책 네트워크를 업데이트한다. [4] 타겟 네크워크를 업데이트한다. 타겟 네트워크는 주기적으로 원본 네트워크의 가중치를 복사하여 업데이트된다. (학습의 안정성 향상) [1]~ [4]를 여러 번 반복한다.
4. Policy Regularization
내용
(1) BC-MLE
내용
(2) BC-CVAE
내용
(3) BC-MMD
내용
(4) Example
내용
(5) Diffusions steps
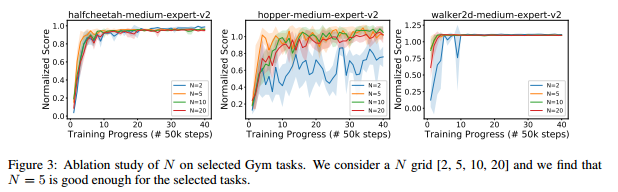
확산 횟수에 따라 확산 정책이 어떻게 수행되는지 추가로 조사하였다. 시간 단계 N은 다양하다. Figure 2를 보면, 예상대로 N이 증가함에 따라 확산 모델이 더 표현적으로 되고 기본 데이터 분포에 대해 더 자세히 학습함을 알 수 있다. N이 50까지 증가하면 실제 데이터 분포가 정확하게 복구된다. Firgure 2의 두번째 행을 보면, Q-learning이 적용되면 적당히 작은 N이 손실 커플링으로 인해 좋은 성능을 제공함을 알 수 있다. 그러나 N이 클수록 확산 모델 기반 복제에 의해 부과되는 정책 정규화가 더 강해진다. N=2일 때 훈련 데이터가 없는 지역 근처에서 샘플링된 몇 개의 작업 지점이 여전히 존재하는 반면, N=50일 때의 정책은 일부 데이터 영역에서 제한된다.
이처럼 Diffusion-QL에 대한 정책 표현성과 계산 비용 사이의 tradeoff 역할을 하는 타임스텝 수 N은 D4RL 데이터 세트에서 N=5가 우수한 성능을 보인다는 것을 발견하였다.

5. Experiments
내용 읽자. 장난간 예제-> '행동 복제'랑 '정책 개선'을 분리한 방식이 좋대. 다른 접근 방식에 비해 멀티모달 데이터를 처리하는데 어떻게 유리한지 명확하게 시각화하여 보여준대.
우리는 D4RL 벤치마크에서 평가를 진행한다. 확산 모델에 필요한 시간 단계 수에 대한 실증 연구, Diffusion-QL의 2가지 주요 구성 요소의 기여도를 분석하기 위한 연구를 수행한다.
Datasets : 우리는 D4RL 벤치마크에서 Gym, AntMaze, Adroit, Kitchen의 4가지 다른 영역의 작업을 고려한다. Gym-Mujoco 이동 작업은 가장 일반적으로 사용되는 표준 작업이며, 데이터세트가 거의 최적에 가까운 궤적의 상당 부분을 포함하고, 보상 함수가 상당히 매끄럽기 때문에 평가가 비교적 쉽다. AntMaze는 보상이 희박하고, 미로의 목표를 향한 경로를 찾기 위해 다양한 차선의 궤적을 꿰매야 하므로 더 도전적이라 할 수 있다. Adroit 데이터셋은 대부분 사람의 행동에 의해 수집되며 오프라인 데이터에 의해 반영되는 상태-행동 영역은 매우 좁기 때문에 강력한 정책 정규화가 필요하다. Kitchen 환경에서는 4개의 하위 작업을 완료해야 하므로 장기적인 값 최적화가 중요하다.
Baselines : ㅇ
Experimental details : 1000 에포크(Gym task의 경우 2000) 동안 훈련한다. 각 에포크는 배치 크기가 256인 1000개의 그래디언트 스텝으로 구성된다. 훈련은 AntMazr 작업에 대한 훈련이 보상 설정이 희박하고, 오프라인 데이터 세트에서 최적의 궤적이 없기 때문에 변동이 있는 것 빼곤, 일반적으로 상당히 안정적이다. 완전 오프라인 방식을 사용하여 성능 평가를 위한 최적의 체크 포인트를 선택한다. 또한 Ld loss를 온라인 성능의 lagging 지표로 사용하여 조기 정지를 수행하고, 2번째 또는 3번째로 Ld 값이 낮은 체크포인트를 선택한다. 본 논문의 결과는 모두 오프라인 모델로, 소량의 온라인 상호 작용을 할 때보다 훨씬 더 좋은 결과를 얻는다.
Effect of hyperparameter : 우리는 확산 모델의 시간 단계 N이 실제 작업에 미치는 영향에 대한 실증 연구를 수행한다. 경험적으로 N이 증가함에 따라 모델리 더 빠르게 수렴하고, 성능이 더 안정적임을 발견할 수 있다. D4RL 작업에서는 성능과 계산 비용의 균형을 맞추기 위해 중간 값인 N = 5를 설정한다.
6. Conclusion
이 논문에서는 conditional diffusion policy 기반 Offline RL 알고리즘인 Diffusion-QL을 제시한다. [1] 이 알고리즘의 정책(policy)은 conditional diffusion model의 reverse chain에 의해 구축되었고, 정책 클래스의 표현이 뛰어나며 학습 자체가 강력한 정책 정규화 방법으로 작용한다. [2] 공동으로 학습한 Q-value function을 통한 Q-learning guidance는 디퓨전 정책 학습에 주입되어, 탐색 영역에서 최적의 영역을 향해 샘플링을 하게 한다. 이 2가지 핵심 구성 요소는 모든 작업에서 높은 성능을 보인다.
-> 참고 리뷰 : https://openreview.net/forum?id=AHvFDPi-FA
-> 요약1: [데이터가 수집된 정책의 [행동 복제]]와 [Q-value function을 통해 역추적하여 도출된 [정책 개선]]의 균형을 맞추기 위해 diffusion policies를 사용한다. Q-value function은 표준 방식으로 학습된다.
-> 요약2: actor-critic model로도 볼 수 있다. generative diffusion model이 actor이고, standard Q-function이 critic인 상황이다. [1] 확산 모델은 지도 학습을 통해 데이터 분포를 모방하도록 훈련된다. [2] Q함수를 사용하여 확산 모델을 학습하는 동안 Q값이 더 높은 액션으로 기울기를 안내한다. 이 접근 방식을 (데이터 분포의 하위 집합으로 제한되는) 정책 정규화 방법이라고 소개한다.
-> 요약3: 이 논문은 행동의 분포가 diffusion model로 표현되는 새로운 Offline RL 알고리즘을 제안한다 .동시에 기존 방법은 단순 가우시안 모델을 사용한다. [1] diffusion은 고전적인 행동 복제 손실(diffusion BC)과 함께 사용할 수 있으며, [2] diffusion은 보상이 사용가능할 때 Q함수과 결합할 수 있다.(diffusion QL) 이 과정에서 Q함수와 연결할 때, TD3+BC 방법과 유사한 전략을 사용하였다.
-> 요약4: diffusion model의 최종 action 출력에 Q-learning guidnace를 결합했다.
-> 단점 : 다른 생성 모델의 성능이 좋지 않다는 점, 데이터 세트별 하이퍼파라미터 튜닝의 필요성에 대한 아쉬움이 있다. offline-RL에서 다른 생성 모델을 대체하기 위해 diffusion policies를 사용했다.


-> 장점 : 비록 이 알고리즘이 단순하지만 evaluation에 메리트가 있으며 추가 작업을 생각해볼 수 있다. 확산 모델의 가장 큰 장점은 데이터 분포가 multimodal(다중 모드)일 때도 정확하게 모델링할 수 있다는 점이다. 아무튼 이렇게 결합된 접근 방식은 에이전트가 샘플에서 벗어난 행동을 취하는 것을 방지하는 동시에, 탐색된 state action 집합 중에서 최적의 action으로 수렴하도록 보장한다. 이 방법이 데이터 분포를 정확하게 모델링할 수 있는 유일한 방법이며, 기준선 중에서 최적의 행동으로 안정적으로 수렴하는 유일한 방법이다. (장난감 도둑 문제 참고)
-> 이전 접근법과의 비교 :이전 정책 정규화(policy regularization) 접근법의 주요 문제점은 데이터 분포의 부정확한 근사치였다. 따라서 다중 모드 행동 정책을 직접 모델링하기 위해 확산 모델을 활용하는 것이 효과적이고 합리적이다.
7. Appendix
(1) More toy experiments
내용
(2) Implementation Details
내용
(3) Experimental details
내용
(4) Offline model Selection
내용
(5) Hyperparameters
내용
(6) Optimal results
제한 사항에 대한 논의 추가 , 여긴가 ? 리뷰어가 말한 단점(실제 시나리오에서 이 접근법을 배포하지 못하게 할 수 있는 행동 샘플링의 높은 계산 비용과 같은 제안된 접근법의 한계에 대해 거의 논의하지 않았다)을 보완하여 부록에 써뒀다 함.
(7) Limitations and future work
아담 옵티마이저 사용 언급
(8) Gaussian mixture policy
가우시안 혼합 정책 사용에 대한 제거 연구 추가.
단순 가우시안 대신, 가우시안과 혼합된 고전적인 최신 방법을 사용할 때도 비교해보자. 가우스 혼합 네트워크는 다중 모드 분포를 포착할 수 있다. 그러나 공분산 행렬을 학습하기 어렵고, 고차원작업 공간에서 성능이 저항되는 경향이 있다. 실제 결과에서도 그 한계가 보였다. 항상 안정적으로 수행되진 못했으며 정책 개선을 추가했을 시 최적의 목표 위치로 수렴하지 못하는 모습을 보인다. 또한 서로 다른 동작 차원 간의 의존성을 포착하는 데 한계를 보였다.
즉, 다중 모드 분포를 모델링할 수 있는 다른 방법들(mixture of diagonal Gaussian, BCQ, BEAR)과 비교해보아도 Diffusion-QL이 더 높은 성능을 보였다.


