1. first try
# Copyright 2022 Twitter, Inc and Zhendong Wang.
# SPDX-License-Identifier: Apache-2.0
import argparse
import gym
import numpy as np
import os
import torch
import json
import glob
import io
import base64
from IPython.display import HTML
from IPython import display as ipythondisplay
from gym.wrappers.record_video import RecordVideo
from pyvirtualdisplay import Display
from xvfbwrapper import Xvfb
import d4rl
from utils import utils
from utils.data_sampler import Data_Sampler
from utils.logger import logger, setup_logger
from torch.utils.tensorboard import SummaryWriter
hyperparameters = {
'halfcheetah-medium-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 9.0, 'top_k': 1},
'hopper-medium-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 9.0, 'top_k': 2},
'walker2d-medium-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 1.0, 'top_k': 1},
'halfcheetah-medium-replay-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 2.0, 'top_k': 0},
'hopper-medium-replay-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 4.0, 'top_k': 2},
'walker2d-medium-replay-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 4.0, 'top_k': 1},
'halfcheetah-medium-expert-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 7.0, 'top_k': 0},
'hopper-medium-expert-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 5.0, 'top_k': 2},
'walker2d-medium-expert-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 5.0, 'top_k': 1},
'antmaze-umaze-v0': {'lr': 3e-4, 'eta': 0.5, 'max_q_backup': False, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 2.0, 'top_k': 2},
'antmaze-umaze-diverse-v0': {'lr': 3e-4, 'eta': 2.0, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 3.0, 'top_k': 2},
'antmaze-medium-play-v0': {'lr': 1e-3, 'eta': 2.0, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 2.0, 'top_k': 1},
'antmaze-medium-diverse-v0': {'lr': 3e-4, 'eta': 3.0, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 1.0, 'top_k': 1},
'antmaze-large-play-v0': {'lr': 3e-4, 'eta': 4.5, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 10.0, 'top_k': 2},
'antmaze-large-diverse-v0': {'lr': 3e-4, 'eta': 3.5, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 7.0, 'top_k': 1},
'pen-human-v1': {'lr': 3e-5, 'eta': 0.15, 'max_q_backup': False, 'reward_tune': 'normalize', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 7.0, 'top_k': 2},
'pen-cloned-v1': {'lr': 3e-5, 'eta': 0.1, 'max_q_backup': False, 'reward_tune': 'normalize', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 8.0, 'top_k': 2},
'kitchen-complete-v0': {'lr': 3e-4, 'eta': 0.005, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 250 , 'gn': 9.0, 'top_k': 2},
'kitchen-partial-v0': {'lr': 3e-4, 'eta': 0.005, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 10.0, 'top_k': 2},
'kitchen-mixed-v0': {'lr': 3e-4, 'eta': 0.005, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 10.0, 'top_k': 0},
}
def train_agent(env, state_dim, action_dim, max_action, device, output_dir, args):
# Load buffer
dataset = d4rl.qlearning_dataset(env)
data_sampler = Data_Sampler(dataset, device, args.reward_tune)
utils.print_banner('Loaded buffer')
if args.algo == 'ql':
from agents.ql_diffusion import Diffusion_QL as Agent
agent = Agent(state_dim=state_dim,
action_dim=action_dim,
max_action=max_action,
device=device,
discount=args.discount,
tau=args.tau,
max_q_backup=args.max_q_backup,
beta_schedule=args.beta_schedule,
n_timesteps=args.T,
eta=args.eta,
lr=args.lr,
lr_decay=args.lr_decay,
lr_maxt=args.num_epochs,
grad_norm=args.gn)
elif args.algo == 'bc':
from agents.bc_diffusion import Diffusion_BC as Agent
agent = Agent(state_dim=state_dim,
action_dim=action_dim,
max_action=max_action,
device=device,
discount=args.discount,
tau=args.tau,
beta_schedule=args.beta_schedule,
n_timesteps=args.T,
lr=args.lr)
early_stop = False
stop_check = utils.EarlyStopping(tolerance=1, min_delta=0.)
writer = None # SummaryWriter(output_dir)
evaluations = []
training_iters = 0
max_timesteps = args.num_epochs * args.num_steps_per_epoch
metric = 100.
utils.print_banner(f"Training Start", separator="*", num_star=90)
while (training_iters < max_timesteps) and (not early_stop):
iterations = int(args.eval_freq * args.num_steps_per_epoch)
loss_metric = agent.train(data_sampler,
iterations=iterations,
batch_size=args.batch_size,
log_writer=writer)
training_iters += iterations
curr_epoch = int(training_iters // int(args.num_steps_per_epoch))
# Logging
utils.print_banner(f"Train step: {training_iters}", separator="*", num_star=90)
logger.record_tabular('Trained Epochs', curr_epoch)
logger.record_tabular('BC Loss', np.mean(loss_metric['bc_loss']))
logger.record_tabular('QL Loss', np.mean(loss_metric['ql_loss']))
logger.record_tabular('Actor Loss', np.mean(loss_metric['actor_loss']))
logger.record_tabular('Critic Loss', np.mean(loss_metric['critic_loss']))
logger.dump_tabular()
# Evaluation
eval_res, eval_res_std, eval_norm_res, eval_norm_res_std = eval_policy(agent, args.env_name, args.seed,
eval_episodes=args.eval_episodes)
evaluations.append([eval_res, eval_res_std, eval_norm_res, eval_norm_res_std,
np.mean(loss_metric['bc_loss']), np.mean(loss_metric['ql_loss']),
np.mean(loss_metric['actor_loss']), np.mean(loss_metric['critic_loss']),
curr_epoch])
np.save(os.path.join(output_dir, "eval"), evaluations)
logger.record_tabular('Average Episodic Reward', eval_res)
logger.record_tabular('Average Episodic N-Reward', eval_norm_res)
logger.dump_tabular()
bc_loss = np.mean(loss_metric['bc_loss'])
if args.early_stop:
early_stop = stop_check(metric, bc_loss)
metric = bc_loss
if args.save_best_model:
agent.save_model(output_dir, curr_epoch)
# Model Selection: online or offline
scores = np.array(evaluations)
if args.ms == 'online':
best_id = np.argmax(scores[:, 2])
best_res = {'model selection': args.ms, 'epoch': scores[best_id, -1],
'best normalized score avg': scores[best_id, 2],
'best normalized score std': scores[best_id, 3],
'best raw score avg': scores[best_id, 0],
'best raw score std': scores[best_id, 1]}
with open(os.path.join(output_dir, f"best_score_{args.ms}.txt"), 'w') as f:
f.write(json.dumps(best_res))
elif args.ms == 'offline':
bc_loss = scores[:, 4]
top_k = min(len(bc_loss) - 1, args.top_k)
where_k = np.argsort(bc_loss) == top_k
best_res = {'model selection': args.ms, 'epoch': scores[where_k][0][-1],
'best normalized score avg': scores[where_k][0][2],
'best normalized score std': scores[where_k][0][3],
'best raw score avg': scores[where_k][0][0],
'best raw score std': scores[where_k][0][1]}
with open(os.path.join(output_dir, f"best_score_{args.ms}.txt"), 'w') as f:
f.write(json.dumps(best_res))
# writer.close()
# Runs policy for X episodes and returns average reward
# A fixed seed is used for the eval environment
def eval_policy(policy, env_name, seed, eval_episodes=10):
eval_env = gym.make(env_name)
eval_env.seed(seed + 100)
scores = []
for _ in range(eval_episodes):
traj_return = 0.
state, done = eval_env.reset(), False
while not done:
action = policy.sample_action(np.array(state))
state, reward, done, _ = eval_env.step(action)
traj_return += reward
scores.append(traj_return)
avg_reward = np.mean(scores)
std_reward = np.std(scores)
normalized_scores = [eval_env.get_normalized_score(s) for s in scores]
avg_norm_score = eval_env.get_normalized_score(avg_reward)
std_norm_score = np.std(normalized_scores)
utils.print_banner(f"Evaluation over {eval_episodes} episodes: {avg_reward:.2f} {avg_norm_score:.2f}")
utils.print_banner(f"State : {state} action : {action}")
return avg_reward, std_reward, avg_norm_score, std_norm_score
if __name__ == "__main__":
parser = argparse.ArgumentParser()
### Experimental Setups ###
parser.add_argument("--exp", default='exp_1', type=str) # Experiment ID
parser.add_argument('--device', default=0, type=int) # device, {"cpu", "cuda", "cuda:0", "cuda:1"}, etc
parser.add_argument("--env_name", default="walker2d-medium-expert-v2", type=str) # OpenAI gym environment name
parser.add_argument("--dir", default="results", type=str) # Logging directory
parser.add_argument("--seed", default=0, type=int) # Sets Gym, PyTorch and Numpy seeds
parser.add_argument("--num_steps_per_epoch", default=1000, type=int)
### Optimization Setups ###
parser.add_argument("--batch_size", default=256, type=int)
parser.add_argument("--lr_decay", action='store_true')
parser.add_argument('--early_stop', action='store_true')
parser.add_argument('--save_best_model', action='store_true')
### RL Parameters ###
parser.add_argument("--discount", default=0.99, type=float)
parser.add_argument("--tau", default=0.005, type=float)
### Diffusion Setting ###
parser.add_argument("--T", default=5, type=int)
parser.add_argument("--beta_schedule", default='vp', type=str)
### Algo Choice ###
parser.add_argument("--algo", default="ql", type=str) # ['bc', 'ql']
parser.add_argument("--ms", default='offline', type=str, help="['online', 'offline']")
# parser.add_argument("--top_k", default=1, type=int)
# parser.add_argument("--lr", default=3e-4, type=float)
# parser.add_argument("--eta", default=1.0, type=float)
# parser.add_argument("--max_q_backup", action='store_true')
# parser.add_argument("--reward_tune", default='no', type=str)
# parser.add_argument("--gn", default=-1.0, type=float)
args = parser.parse_args()
args.device = f"cuda:{args.device}" if torch.cuda.is_available() else "cpu"
args.output_dir = f'{args.dir}'
args.num_epochs = hyperparameters[args.env_name]['num_epochs']
args.eval_freq = hyperparameters[args.env_name]['eval_freq']
args.eval_episodes = 10 if 'v2' in args.env_name else 100
args.lr = hyperparameters[args.env_name]['lr']
args.eta = hyperparameters[args.env_name]['eta']
args.max_q_backup = hyperparameters[args.env_name]['max_q_backup']
args.reward_tune = hyperparameters[args.env_name]['reward_tune']
args.gn = hyperparameters[args.env_name]['gn']
args.top_k = hyperparameters[args.env_name]['top_k']
# Setup Logging
file_name = f"{args.env_name}|{args.exp}|diffusion-{args.algo}|T-{args.T}"
if args.lr_decay: file_name += '|lr_decay'
file_name += f'|ms-{args.ms}'
if args.ms == 'offline': file_name += f'|k-{args.top_k}'
file_name += f'|{args.seed}'
results_dir = os.path.join(args.output_dir, file_name)
if not os.path.exists(results_dir):
os.makedirs(results_dir)
utils.print_banner(f"Saving location: {results_dir}")
# if os.path.exists(os.path.join(results_dir, 'variant.json')):
# raise AssertionError("Experiment under this setting has been done!")
variant = vars(args)
variant.update(version=f"Diffusion-Policies-RL")
#env = gym.make(args.env_name)
display = Display(visible=0, size=(1400, 900))
display.start()
def show_video():
mp4list = glob.glob('video/*.mp4')
if len(mp4list) > 0:
mp4 = mp4list[0]
video = io.open(mp4, 'r+b').read()
encoded = base64.b64encode(video)
ipythondisplay.display(HTML(data='''<video alt="test" autoplay
loop controls style="height: 400px;">
<source src="data:video/mp4;base64,{0}" type="video/mp4" />
</video>'''.format(encoded.decode('ascii'))))
else:
print("Could not find video")
env = gym.make(args.env_name)
env.seed(args.seed)
torch.manual_seed(args.seed)
np.random.seed(args.seed)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
max_action = float(env.action_space.high[0])
variant.update(state_dim=state_dim)
variant.update(action_dim=action_dim)
variant.update(max_action=max_action)
setup_logger(os.path.basename(results_dir), variant=variant, log_dir=results_dir)
utils.print_banner(f"Env: {args.env_name}, state_dim: {state_dim}, action_dim: {action_dim}")
train_agent(env,
state_dim,
action_dim,
max_action,
args.device,
results_dir,
args)
env = RecordVideo(env, './video', episode_trigger = lambda episode_number: True)
state = env.reset()
while True:
env.render()
mu,sigma = agent.get_action(torch.from_numpy(state).float().to(device))
dist = torch.distributions.Normal(mu,sigma[0])
action = dist.sample()
state, reward, done, info = env.step(action.cpu().numpy())
if done: break
env.close()
show_video()
2. second try
with GPT's help..
# Copyright 2022 Twitter, Inc and Zhendong Wang.
# SPDX-License-Identifier: Apache-2.0
import argparse
import gym
import numpy as np
import os
import torch
import json
import glob
import io
import base64
from IPython.display import HTML
from IPython import display as ipythondisplay
from gym.wrappers.record_video import RecordVideo
from pyvirtualdisplay import Display
from xvfbwrapper import Xvfb
import d4rl
from utils import utils
from utils.data_sampler import Data_Sampler
from utils.logger import logger, setup_logger
from torch.utils.tensorboard import SummaryWriter
hyperparameters = {
'halfcheetah-medium-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 9.0, 'top_k': 1},
'hopper-medium-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 9.0, 'top_k': 2},
'walker2d-medium-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 1.0, 'top_k': 1},
'halfcheetah-medium-replay-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 2.0, 'top_k': 0},
'hopper-medium-replay-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 4.0, 'top_k': 2},
'walker2d-medium-replay-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 4.0, 'top_k': 1},
'halfcheetah-medium-expert-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 7.0, 'top_k': 0},
'hopper-medium-expert-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 5.0, 'top_k': 2},
'walker2d-medium-expert-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 5.0, 'top_k': 1},
'antmaze-umaze-v0': {'lr': 3e-4, 'eta': 0.5, 'max_q_backup': False, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 2.0, 'top_k': 2},
'antmaze-umaze-diverse-v0': {'lr': 3e-4, 'eta': 2.0, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 3.0, 'top_k': 2},
'antmaze-medium-play-v0': {'lr': 1e-3, 'eta': 2.0, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 2.0, 'top_k': 1},
'antmaze-medium-diverse-v0': {'lr': 3e-4, 'eta': 3.0, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 1.0, 'top_k': 1},
'antmaze-large-play-v0': {'lr': 3e-4, 'eta': 4.5, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 10.0, 'top_k': 2},
'antmaze-large-diverse-v0': {'lr': 3e-4, 'eta': 3.5, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 7.0, 'top_k': 1},
'pen-human-v1': {'lr': 3e-5, 'eta': 0.15, 'max_q_backup': False, 'reward_tune': 'normalize', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 7.0, 'top_k': 2},
'pen-cloned-v1': {'lr': 3e-5, 'eta': 0.1, 'max_q_backup': False, 'reward_tune': 'normalize', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 8.0, 'top_k': 2},
'kitchen-complete-v0': {'lr': 3e-4, 'eta': 0.005, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 250 , 'gn': 9.0, 'top_k': 2},
'kitchen-partial-v0': {'lr': 3e-4, 'eta': 0.005, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 10.0, 'top_k': 2},
'kitchen-mixed-v0': {'lr': 3e-4, 'eta': 0.005, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 10.0, 'top_k': 0},
}
try:
from xvfbwrapper import Xvfb
except ImportError:
print("Xvfb not found. Installing xvfbwrapper...")
os.system("pip install xvfbwrapper")
from xvfbwrapper import Xvfb
def train_agent(env, state_dim, action_dim, max_action, device, output_dir, args):
# Load buffer
dataset = d4rl.qlearning_dataset(env)
data_sampler = Data_Sampler(dataset, device, args.reward_tune)
utils.print_banner('Loaded buffer')
if args.algo == 'ql':
from agents.ql_diffusion import Diffusion_QL as Agent
agent = Agent(state_dim=state_dim,
action_dim=action_dim,
max_action=max_action,
device=device,
discount=args.discount,
tau=args.tau,
max_q_backup=args.max_q_backup,
beta_schedule=args.beta_schedule,
n_timesteps=args.T,
eta=args.eta,
lr=args.lr,
lr_decay=args.lr_decay,
lr_maxt=args.num_epochs,
grad_norm=args.gn)
elif args.algo == 'bc':
from agents.bc_diffusion import Diffusion_BC as Agent
agent = Agent(state_dim=state_dim,
action_dim=action_dim,
max_action=max_action,
device=device,
discount=args.discount,
tau=args.tau,
beta_schedule=args.beta_schedule,
n_timesteps=args.T,
lr=args.lr)
early_stop = False
stop_check = utils.EarlyStopping(tolerance=1, min_delta=0.)
writer = None # SummaryWriter(output_dir)
evaluations = []
training_iters = 0
max_timesteps = args.num_epochs * args.num_steps_per_epoch
metric = 100.
utils.print_banner(f"Training Start", separator="*", num_star=90)
while (training_iters < max_timesteps) and (not early_stop):
iterations = int(args.eval_freq * args.num_steps_per_epoch)
loss_metric = agent.train(data_sampler,
iterations=iterations,
batch_size=args.batch_size,
log_writer=writer)
training_iters += iterations
curr_epoch = int(training_iters // int(args.num_steps_per_epoch))
# Logging
utils.print_banner(f"Train step: {training_iters}", separator="*", num_star=90)
logger.record_tabular('Trained Epochs', curr_epoch)
logger.record_tabular('BC Loss', np.mean(loss_metric['bc_loss']))
logger.record_tabular('QL Loss', np.mean(loss_metric['ql_loss']))
logger.record_tabular('Actor Loss', np.mean(loss_metric['actor_loss']))
logger.record_tabular('Critic Loss', np.mean(loss_metric['critic_loss']))
logger.dump_tabular()
# Evaluation
eval_res, eval_res_std, eval_norm_res, eval_norm_res_std = eval_policy(agent, args.env_name, args.seed,
eval_episodes=args.eval_episodes)
evaluations.append([eval_res, eval_res_std, eval_norm_res, eval_norm_res_std,
np.mean(loss_metric['bc_loss']), np.mean(loss_metric['ql_loss']),
np.mean(loss_metric['actor_loss']), np.mean(loss_metric['critic_loss']),
curr_epoch])
np.save(os.path.join(output_dir, "eval"), evaluations)
logger.record_tabular('Average Episodic Reward', eval_res)
logger.record_tabular('Average Episodic N-Reward', eval_norm_res)
logger.dump_tabular()
bc_loss = np.mean(loss_metric['bc_loss'])
if args.early_stop:
early_stop = stop_check(metric, bc_loss)
metric = bc_loss
if args.save_best_model:
agent.save_model(output_dir, curr_epoch)
# Model Selection: online or offline
scores = np.array(evaluations)
if args.ms == 'online':
best_id = np.argmax(scores[:, 2])
best_res = {'model selection': args.ms, 'epoch': scores[best_id, -1],
'best normalized score avg': scores[best_id, 2],
'best normalized score std': scores[best_id, 3],
'best raw score avg': scores[best_id, 0],
'best raw score std': scores[best_id, 1]}
with open(os.path.join(output_dir, f"best_score_{args.ms}.txt"), 'w') as f:
f.write(json.dumps(best_res))
elif args.ms == 'offline':
bc_loss = scores[:, 4]
top_k = min(len(bc_loss) - 1, args.top_k)
where_k = np.argsort(bc_loss) == top_k
best_res = {'model selection': args.ms, 'epoch': scores[where_k][0][-1],
'best normalized score avg': scores[where_k][0][2],
'best normalized score std': scores[where_k][0][3],
'best raw score avg': scores[where_k][0][0],
'best raw score std': scores[where_k][0][1]}
with open(os.path.join(output_dir, f"best_score_{args.ms}.txt"), 'w') as f:
f.write(json.dumps(best_res))
# writer.close()
# Runs policy for X episodes and returns average reward
# A fixed seed is used for the eval environment
def eval_policy(policy, env_name, seed, eval_episodes=10):
eval_env = gym.make(env_name)
eval_env.seed(seed + 100)
scores = []
for _ in range(eval_episodes):
traj_return = 0.
state, done = eval_env.reset(), False
while not done:
action = policy.sample_action(np.array(state))
state, reward, done, _ = eval_env.step(action)
traj_return += reward
scores.append(traj_return)
avg_reward = np.mean(scores)
std_reward = np.std(scores)
normalized_scores = [eval_env.get_normalized_score(s) for s in scores]
avg_norm_score = eval_env.get_normalized_score(avg_reward)
std_norm_score = np.std(normalized_scores)
utils.print_banner(f"Evaluation over {eval_episodes} episodes: {avg_reward:.2f} {avg_norm_score:.2f}")
utils.print_banner(f"State : {state} action : {action}")
return avg_reward, std_reward, avg_norm_score, std_norm_score
if __name__ == "__main__":
parser = argparse.ArgumentParser()
### Experimental Setups ###
parser.add_argument("--exp", default='exp_1', type=str) # Experiment ID
parser.add_argument('--device', default=0, type=int) # device, {"cpu", "cuda", "cuda:0", "cuda:1"}, etc
parser.add_argument("--env_name", default="walker2d-medium-expert-v2", type=str) # OpenAI gym environment name
parser.add_argument("--dir", default="results", type=str) # Logging directory
parser.add_argument("--seed", default=0, type=int) # Sets Gym, PyTorch and Numpy seeds
parser.add_argument("--num_steps_per_epoch", default=1000, type=int)
### Optimization Setups ###
parser.add_argument("--batch_size", default=256, type=int)
parser.add_argument("--lr_decay", action='store_true')
parser.add_argument('--early_stop', action='store_true')
parser.add_argument('--save_best_model', action='store_true')
### RL Parameters ###
parser.add_argument("--discount", default=0.99, type=float)
parser.add_argument("--tau", default=0.005, type=float)
### Diffusion Setting ###
parser.add_argument("--T", default=5, type=int)
parser.add_argument("--beta_schedule", default='vp', type=str)
### Algo Choice ###
parser.add_argument("--algo", default="ql", type=str) # ['bc', 'ql']
parser.add_argument("--ms", default='offline', type=str, help="['online', 'offline']")
# parser.add_argument("--top_k", default=1, type=int)
# parser.add_argument("--lr", default=3e-4, type=float)
# parser.add_argument("--eta", default=1.0, type=float)
# parser.add_argument("--max_q_backup", action='store_true')
# parser.add_argument("--reward_tune", default='no', type=str)
# parser.add_argument("--gn", default=-1.0, type=float)
args = parser.parse_args()
args.device = f"cuda:{args.device}" if torch.cuda.is_available() else "cpu"
args.output_dir = f'{args.dir}'
args.num_epochs = hyperparameters[args.env_name]['num_epochs']
args.eval_freq = hyperparameters[args.env_name]['eval_freq']
args.eval_episodes = 10 if 'v2' in args.env_name else 100
args.lr = hyperparameters[args.env_name]['lr']
args.eta = hyperparameters[args.env_name]['eta']
args.max_q_backup = hyperparameters[args.env_name]['max_q_backup']
args.reward_tune = hyperparameters[args.env_name]['reward_tune']
args.gn = hyperparameters[args.env_name]['gn']
args.top_k = hyperparameters[args.env_name]['top_k']
# Setup Logging
file_name = f"{args.env_name}|{args.exp}|diffusion-{args.algo}|T-{args.T}"
if args.lr_decay: file_name += '|lr_decay'
file_name += f'|ms-{args.ms}'
if args.ms == 'offline': file_name += f'|k-{args.top_k}'
file_name += f'|{args.seed}'
results_dir = os.path.join(args.output_dir, file_name)
if not os.path.exists(results_dir):
os.makedirs(results_dir)
utils.print_banner(f"Saving location: {results_dir}")
# if os.path.exists(os.path.join(results_dir, 'variant.json')):
# raise AssertionError("Experiment under this setting has been done!")
variant = vars(args)
variant.update(version=f"Diffusion-Policies-RL")
#env = gym.make(args.env_name)
with Display(visible=0, size=(1400, 900)):
env = gym.make(args.env_name)
env.seed(args.seed)
torch.manual_seed(args.seed)
np.random.seed(args.seed)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
max_action = float(env.action_space.high[0])
variant.update(state_dim=state_dim)
variant.update(action_dim=action_dim)
variant.update(max_action=max_action)
setup_logger(os.path.basename(results_dir), variant=variant, log_dir=results_dir)
utils.print_banner(f"Env: {args.env_name}, state_dim: {state_dim}, action_dim: {action_dim}")
train_agent(env, state_dim, action_dim, max_action, args.device, results_dir, args)
def show_video():
mp4list = glob.glob('video/*.mp4')
if len(mp4list) > 0:
mp4 = mp4list[0]
video = io.open(mp4, 'r+b').read()
encoded = base64.b64encode(video)
ipythondisplay.display(HTML(data='''<video alt="test" autoplay
loop controls style="height: 400px;">
<source src="data:video/mp4;base64,{0}" type="video/mp4" />
</video>'''.format(encoded.decode('ascii'))))
else:
print("Could not find video")
env = RecordVideo(env, './video', episode_trigger = lambda episode_number: True)
state = env.reset()
while True:
env.render()
mu,sigma = agent.get_action(torch.from_numpy(state).float().to(device))
dist = torch.distributions.Normal(mu,sigma[0])
action = dist.sample()
state, reward, done, info = env.step(action.cpu().numpy())
if done: break
env.close()
show_video()
3. third try
ok.. let's do it step by step.
(1) do a simple mujuco rendering

import gym
env = gym.make('Humanoid-v4')
obs = env.reset()
for _ in range(1000):
action = env.action_space.sample()
obs, reward, done, info = env.step(action)
env.render()
(2) apply it..
# Copyright 2022 Twitter, Inc and Zhendong Wang.
# SPDX-License-Identifier: Apache-2.0
import argparse
import gym
import numpy as np
import os
import torch
import json
import d4rl
from utils import utils
from utils.data_sampler import Data_Sampler
from utils.logger import logger, setup_logger
from torch.utils.tensorboard import SummaryWriter
hyperparameters = {
'halfcheetah-medium-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 9.0, 'top_k': 1},
'hopper-medium-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 9.0, 'top_k': 2},
'walker2d-medium-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 1.0, 'top_k': 1},
'halfcheetah-medium-replay-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 2.0, 'top_k': 0},
'hopper-medium-replay-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 4.0, 'top_k': 2},
'walker2d-medium-replay-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 4.0, 'top_k': 1},
'halfcheetah-medium-expert-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 7.0, 'top_k': 0},
'hopper-medium-expert-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 5.0, 'top_k': 2},
'walker2d-medium-expert-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 5.0, 'top_k': 1},
'antmaze-umaze-v0': {'lr': 3e-4, 'eta': 0.5, 'max_q_backup': False, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 2.0, 'top_k': 2},
'antmaze-umaze-diverse-v0': {'lr': 3e-4, 'eta': 2.0, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 3.0, 'top_k': 2},
'antmaze-medium-play-v0': {'lr': 1e-3, 'eta': 2.0, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 2.0, 'top_k': 1},
'antmaze-medium-diverse-v0': {'lr': 3e-4, 'eta': 3.0, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 1.0, 'top_k': 1},
'antmaze-large-play-v0': {'lr': 3e-4, 'eta': 4.5, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 10.0, 'top_k': 2},
'antmaze-large-diverse-v0': {'lr': 3e-4, 'eta': 3.5, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 7.0, 'top_k': 1},
'pen-human-v1': {'lr': 3e-5, 'eta': 0.15, 'max_q_backup': False, 'reward_tune': 'normalize', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 7.0, 'top_k': 2},
'pen-cloned-v1': {'lr': 3e-5, 'eta': 0.1, 'max_q_backup': False, 'reward_tune': 'normalize', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 8.0, 'top_k': 2},
'kitchen-complete-v0': {'lr': 3e-4, 'eta': 0.005, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 250 , 'gn': 9.0, 'top_k': 2},
'kitchen-partial-v0': {'lr': 3e-4, 'eta': 0.005, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 10.0, 'top_k': 2},
'kitchen-mixed-v0': {'lr': 3e-4, 'eta': 0.005, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 10.0, 'top_k': 0},
}
def train_agent(env, state_dim, action_dim, max_action, device, output_dir, args):
# Load buffer
dataset = d4rl.qlearning_dataset(env)
data_sampler = Data_Sampler(dataset, device, args.reward_tune)
utils.print_banner('Loaded buffer')
if args.algo == 'ql':
from agents.ql_diffusion import Diffusion_QL as Agent
agent = Agent(state_dim=state_dim,
action_dim=action_dim,
max_action=max_action,
device=device,
discount=args.discount,
tau=args.tau,
max_q_backup=args.max_q_backup,
beta_schedule=args.beta_schedule,
n_timesteps=args.T,
eta=args.eta,
lr=args.lr,
lr_decay=args.lr_decay,
lr_maxt=args.num_epochs,
grad_norm=args.gn)
elif args.algo == 'bc':
from agents.bc_diffusion import Diffusion_BC as Agent
agent = Agent(state_dim=state_dim,
action_dim=action_dim,
max_action=max_action,
device=device,
discount=args.discount,
tau=args.tau,
beta_schedule=args.beta_schedule,
n_timesteps=args.T,
lr=args.lr)
early_stop = False
stop_check = utils.EarlyStopping(tolerance=1, min_delta=0.)
writer = None # SummaryWriter(output_dir)
evaluations = []
training_iters = 0
max_timesteps = args.num_epochs * args.num_steps_per_epoch
metric = 100.
utils.print_banner(f"Training Start", separator="*", num_star=90)
while (training_iters < max_timesteps) and (not early_stop):
iterations = int(args.eval_freq * args.num_steps_per_epoch)
loss_metric = agent.train(data_sampler,
iterations=iterations,
batch_size=args.batch_size,
log_writer=writer)
training_iters += iterations
curr_epoch = int(training_iters // int(args.num_steps_per_epoch))
# Logging
utils.print_banner(f"Train step: {training_iters}", separator="*", num_star=90)
logger.record_tabular('Trained Epochs', curr_epoch)
logger.record_tabular('BC Loss', np.mean(loss_metric['bc_loss']))
logger.record_tabular('QL Loss', np.mean(loss_metric['ql_loss']))
logger.record_tabular('Actor Loss', np.mean(loss_metric['actor_loss']))
logger.record_tabular('Critic Loss', np.mean(loss_metric['critic_loss']))
logger.dump_tabular()
# Evaluation
eval_res, eval_res_std, eval_norm_res, eval_norm_res_std = eval_policy(agent, args.env_name, args.seed,
eval_episodes=args.eval_episodes)
evaluations.append([eval_res, eval_res_std, eval_norm_res, eval_norm_res_std,
np.mean(loss_metric['bc_loss']), np.mean(loss_metric['ql_loss']),
np.mean(loss_metric['actor_loss']), np.mean(loss_metric['critic_loss']),
curr_epoch])
np.save(os.path.join(output_dir, "eval"), evaluations)
logger.record_tabular('Average Episodic Reward', eval_res)
logger.record_tabular('Average Episodic N-Reward', eval_norm_res)
logger.dump_tabular()
bc_loss = np.mean(loss_metric['bc_loss'])
if args.early_stop:
early_stop = stop_check(metric, bc_loss)
metric = bc_loss
if args.save_best_model:
agent.save_model(output_dir, curr_epoch)
# Model Selection: online or offline
scores = np.array(evaluations)
if args.ms == 'online':
best_id = np.argmax(scores[:, 2])
best_res = {'model selection': args.ms, 'epoch': scores[best_id, -1],
'best normalized score avg': scores[best_id, 2],
'best normalized score std': scores[best_id, 3],
'best raw score avg': scores[best_id, 0],
'best raw score std': scores[best_id, 1]}
with open(os.path.join(output_dir, f"best_score_{args.ms}.txt"), 'w') as f:
f.write(json.dumps(best_res))
elif args.ms == 'offline':
bc_loss = scores[:, 4]
top_k = min(len(bc_loss) - 1, args.top_k)
where_k = np.argsort(bc_loss) == top_k
best_res = {'model selection': args.ms, 'epoch': scores[where_k][0][-1],
'best normalized score avg': scores[where_k][0][2],
'best normalized score std': scores[where_k][0][3],
'best raw score avg': scores[where_k][0][0],
'best raw score std': scores[where_k][0][1]}
with open(os.path.join(output_dir, f"best_score_{args.ms}.txt"), 'w') as f:
f.write(json.dumps(best_res))
# writer.close()
# Runs policy for X episodes and returns average reward
# A fixed seed is used for the eval environment
def eval_policy(policy, env_name, seed, eval_episodes=10):
eval_env = gym.make(env_name)
eval_env.seed(seed + 100)
scores = []
for _ in range(eval_episodes):
traj_return = 0.
state, done = eval_env.reset(), False
while not done:
action = policy.sample_action(np.array(state))
state, reward, done, _ = eval_env.step(action)
traj_return += reward
scores.append(traj_return)
avg_reward = np.mean(scores)
std_reward = np.std(scores)
normalized_scores = [eval_env.get_normalized_score(s) for s in scores]
avg_norm_score = eval_env.get_normalized_score(avg_reward)
std_norm_score = np.std(normalized_scores)
utils.print_banner(f"Evaluation over {eval_episodes} episodes: {avg_reward:.2f} {avg_norm_score:.2f}")
return avg_reward, std_reward, avg_norm_score, std_norm_score
if __name__ == "__main__":
parser = argparse.ArgumentParser()
### Experimental Setups ###
parser.add_argument("--exp", default='exp_1', type=str) # Experiment ID
parser.add_argument('--device', default=0, type=int) # device, {"cpu", "cuda", "cuda:0", "cuda:1"}, etc
parser.add_argument("--env_name", default="walker2d-medium-expert-v2", type=str) # OpenAI gym environment name
parser.add_argument("--dir", default="results", type=str) # Logging directory
parser.add_argument("--seed", default=0, type=int) # Sets Gym, PyTorch and Numpy seeds
parser.add_argument("--num_steps_per_epoch", default=1000, type=int)
### Optimization Setups ###
parser.add_argument("--batch_size", default=256, type=int)
parser.add_argument("--lr_decay", action='store_true')
parser.add_argument('--early_stop', action='store_true')
parser.add_argument('--save_best_model', action='store_true')
### RL Parameters ###
parser.add_argument("--discount", default=0.99, type=float)
parser.add_argument("--tau", default=0.005, type=float)
### Diffusion Setting ###
parser.add_argument("--T", default=5, type=int)
parser.add_argument("--beta_schedule", default='vp', type=str)
### Algo Choice ###
parser.add_argument("--algo", default="ql", type=str) # ['bc', 'ql']
parser.add_argument("--ms", default='offline', type=str, help="['online', 'offline']")
# parser.add_argument("--top_k", default=1, type=int)
# parser.add_argument("--lr", default=3e-4, type=float)
# parser.add_argument("--eta", default=1.0, type=float)
# parser.add_argument("--max_q_backup", action='store_true')
# parser.add_argument("--reward_tune", default='no', type=str)
# parser.add_argument("--gn", default=-1.0, type=float)
args = parser.parse_args()
args.device = f"cuda:{args.device}" if torch.cuda.is_available() else "cpu"
args.output_dir = f'{args.dir}'
args.num_epochs = hyperparameters[args.env_name]['num_epochs']
args.eval_freq = hyperparameters[args.env_name]['eval_freq']
args.eval_episodes = 10 if 'v2' in args.env_name else 100
args.lr = hyperparameters[args.env_name]['lr']
args.eta = hyperparameters[args.env_name]['eta']
args.max_q_backup = hyperparameters[args.env_name]['max_q_backup']
args.reward_tune = hyperparameters[args.env_name]['reward_tune']
args.gn = hyperparameters[args.env_name]['gn']
args.top_k = hyperparameters[args.env_name]['top_k']
# Setup Logging
file_name = f"{args.env_name}|{args.exp}|diffusion-{args.algo}|T-{args.T}"
if args.lr_decay: file_name += '|lr_decay'
file_name += f'|ms-{args.ms}'
if args.ms == 'offline': file_name += f'|k-{args.top_k}'
file_name += f'|{args.seed}'
results_dir = os.path.join(args.output_dir, file_name)
if not os.path.exists(results_dir):
os.makedirs(results_dir)
utils.print_banner(f"Saving location: {results_dir}")
# if os.path.exists(os.path.join(results_dir, 'variant.json')):
# raise AssertionError("Experiment under this setting has been done!")
variant = vars(args)
variant.update(version=f"Diffusion-Policies-RL")
env = gym.make(args.env_name)
obs = env.reset()
for _ in range(10000000):
action = env.action_space.sample()
obs, reward, done, info = env.step(action)
env.render()
env.seed(args.seed)
torch.manual_seed(args.seed)
np.random.seed(args.seed)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
max_action = float(env.action_space.high[0])
variant.update(state_dim=state_dim)
variant.update(action_dim=action_dim)
variant.update(max_action=max_action)
setup_logger(os.path.basename(results_dir), variant=variant, log_dir=results_dir)
utils.print_banner(f"Env: {args.env_name}, state_dim: {state_dim}, action_dim: {action_dim}")
train_agent(env,
state_dim,
action_dim,
max_action,
args.device,
results_dir,
args)
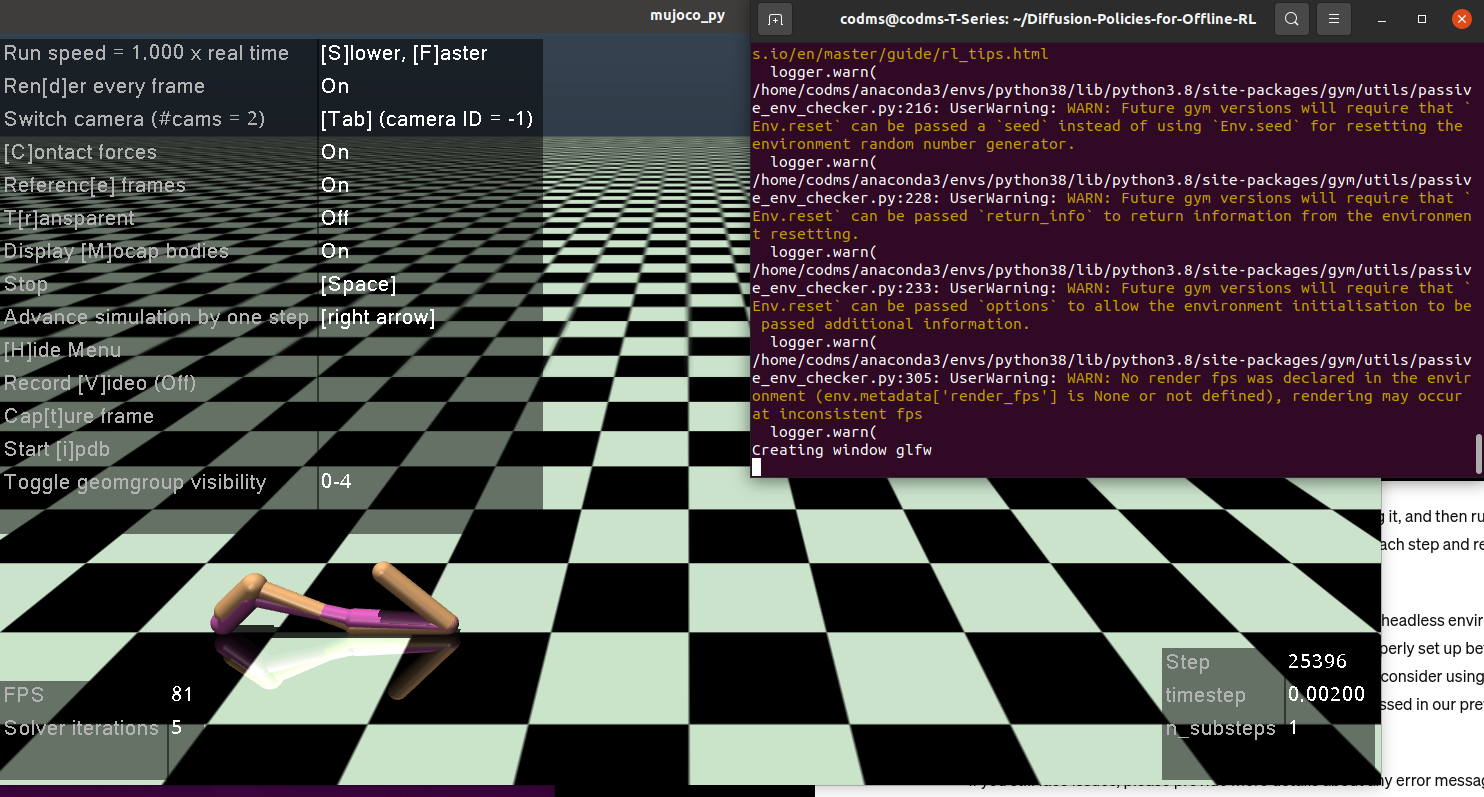
just rendering without training.
(3) modify and apply it..
# Copyright 2022 Twitter, Inc and Zhendong Wang.
# SPDX-License-Identifier: Apache-2.0
import argparse
import gym
import numpy as np
import os
import torch
import json
import d4rl
from utils import utils
from utils.data_sampler import Data_Sampler
from utils.logger import logger, setup_logger
from torch.utils.tensorboard import SummaryWriter
hyperparameters = {
'halfcheetah-medium-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 9.0, 'top_k': 1},
'hopper-medium-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 9.0, 'top_k': 2},
'walker2d-medium-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 1.0, 'top_k': 1},
'halfcheetah-medium-replay-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 2.0, 'top_k': 0},
'hopper-medium-replay-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 4.0, 'top_k': 2},
'walker2d-medium-replay-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 4.0, 'top_k': 1},
'halfcheetah-medium-expert-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 7.0, 'top_k': 0},
'hopper-medium-expert-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 5.0, 'top_k': 2},
'walker2d-medium-expert-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 5.0, 'top_k': 1},
'antmaze-umaze-v0': {'lr': 3e-4, 'eta': 0.5, 'max_q_backup': False, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 2.0, 'top_k': 2},
'antmaze-umaze-diverse-v0': {'lr': 3e-4, 'eta': 2.0, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 3.0, 'top_k': 2},
'antmaze-medium-play-v0': {'lr': 1e-3, 'eta': 2.0, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 2.0, 'top_k': 1},
'antmaze-medium-diverse-v0': {'lr': 3e-4, 'eta': 3.0, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 1.0, 'top_k': 1},
'antmaze-large-play-v0': {'lr': 3e-4, 'eta': 4.5, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 10.0, 'top_k': 2},
'antmaze-large-diverse-v0': {'lr': 3e-4, 'eta': 3.5, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 7.0, 'top_k': 1},
'pen-human-v1': {'lr': 3e-5, 'eta': 0.15, 'max_q_backup': False, 'reward_tune': 'normalize', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 7.0, 'top_k': 2},
'pen-cloned-v1': {'lr': 3e-5, 'eta': 0.1, 'max_q_backup': False, 'reward_tune': 'normalize', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 8.0, 'top_k': 2},
'kitchen-complete-v0': {'lr': 3e-4, 'eta': 0.005, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 250 , 'gn': 9.0, 'top_k': 2},
'kitchen-partial-v0': {'lr': 3e-4, 'eta': 0.005, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 10.0, 'top_k': 2},
'kitchen-mixed-v0': {'lr': 3e-4, 'eta': 0.005, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 10.0, 'top_k': 0},
}
def train_agent(env, state_dim, action_dim, max_action, device, output_dir, args):
# Load buffer
dataset = d4rl.qlearning_dataset(env)
data_sampler = Data_Sampler(dataset, device, args.reward_tune)
utils.print_banner('Loaded buffer')
state, done = env.reset(), False
if args.algo == 'ql':
from agents.ql_diffusion import Diffusion_QL as Agent
agent = Agent(state_dim=state_dim,
action_dim=action_dim,
max_action=max_action,
device=device,
discount=args.discount,
tau=args.tau,
max_q_backup=args.max_q_backup,
beta_schedule=args.beta_schedule,
n_timesteps=args.T,
eta=args.eta,
lr=args.lr,
lr_decay=args.lr_decay,
lr_maxt=args.num_epochs,
grad_norm=args.gn)
elif args.algo == 'bc':
from agents.bc_diffusion import Diffusion_BC as Agent
agent = Agent(state_dim=state_dim,
action_dim=action_dim,
max_action=max_action,
device=device,
discount=args.discount,
tau=args.tau,
beta_schedule=args.beta_schedule,
n_timesteps=args.T,
lr=args.lr)
early_stop = False
stop_check = utils.EarlyStopping(tolerance=1, min_delta=0.)
writer = None # SummaryWriter(output_dir)
evaluations = []
training_iters = 0
max_timesteps = args.num_epochs * args.num_steps_per_epoch
metric = 100.
utils.print_banner(f"Training Start", separator="*", num_star=90)
while (training_iters < max_timesteps) and (not early_stop):
iterations = int(args.eval_freq * args.num_steps_per_epoch)
loss_metric = agent.train(data_sampler,
iterations=iterations,
batch_size=args.batch_size,
log_writer=writer)
training_iters += iterations
curr_epoch = int(training_iters // int(args.num_steps_per_epoch))
env.render()
# Logging
utils.print_banner(f"Train step: {training_iters}", separator="*", num_star=90)
logger.record_tabular('Trained Epochs', curr_epoch)
logger.record_tabular('BC Loss', np.mean(loss_metric['bc_loss']))
logger.record_tabular('QL Loss', np.mean(loss_metric['ql_loss']))
logger.record_tabular('Actor Loss', np.mean(loss_metric['actor_loss']))
logger.record_tabular('Critic Loss', np.mean(loss_metric['critic_loss']))
logger.dump_tabular()
# Evaluation
eval_res, eval_res_std, eval_norm_res, eval_norm_res_std = eval_policy(agent, args.env_name, args.seed,
eval_episodes=args.eval_episodes)
evaluations.append([eval_res, eval_res_std, eval_norm_res, eval_norm_res_std,
np.mean(loss_metric['bc_loss']), np.mean(loss_metric['ql_loss']),
np.mean(loss_metric['actor_loss']), np.mean(loss_metric['critic_loss']),
curr_epoch])
np.save(os.path.join(output_dir, "eval"), evaluations)
logger.record_tabular('Average Episodic Reward', eval_res)
logger.record_tabular('Average Episodic N-Reward', eval_norm_res)
logger.dump_tabular()
bc_loss = np.mean(loss_metric['bc_loss'])
if args.early_stop:
early_stop = stop_check(metric, bc_loss)
metric = bc_loss
if args.save_best_model:
agent.save_model(output_dir, curr_epoch)
# Model Selection: online or offline
scores = np.array(evaluations)
if args.ms == 'online':
best_id = np.argmax(scores[:, 2])
best_res = {'model selection': args.ms, 'epoch': scores[best_id, -1],
'best normalized score avg': scores[best_id, 2],
'best normalized score std': scores[best_id, 3],
'best raw score avg': scores[best_id, 0],
'best raw score std': scores[best_id, 1]}
with open(os.path.join(output_dir, f"best_score_{args.ms}.txt"), 'w') as f:
f.write(json.dumps(best_res))
elif args.ms == 'offline':
bc_loss = scores[:, 4]
top_k = min(len(bc_loss) - 1, args.top_k)
where_k = np.argsort(bc_loss) == top_k
best_res = {'model selection': args.ms, 'epoch': scores[where_k][0][-1],
'best normalized score avg': scores[where_k][0][2],
'best normalized score std': scores[where_k][0][3],
'best raw score avg': scores[where_k][0][0],
'best raw score std': scores[where_k][0][1]}
with open(os.path.join(output_dir, f"best_score_{args.ms}.txt"), 'w') as f:
f.write(json.dumps(best_res))
# writer.close()
# Runs policy for X episodes and returns average reward
# A fixed seed is used for the eval environment
def eval_policy(policy, env_name, seed, eval_episodes=10):
eval_env = gym.make(env_name)
eval_env.seed(seed + 100)
scores = []
for _ in range(eval_episodes):
traj_return = 0.
state, done = eval_env.reset(), False
while not done:
action = policy.sample_action(np.array(state))
state, reward, done, _ = eval_env.step(action)
traj_return += reward
scores.append(traj_return)
avg_reward = np.mean(scores)
std_reward = np.std(scores)
normalized_scores = [eval_env.get_normalized_score(s) for s in scores]
avg_norm_score = eval_env.get_normalized_score(avg_reward)
std_norm_score = np.std(normalized_scores)
utils.print_banner(f"Evaluation over {eval_episodes} episodes: {avg_reward:.2f} {avg_norm_score:.2f}")
return avg_reward, std_reward, avg_norm_score, std_norm_score
if __name__ == "__main__":
parser = argparse.ArgumentParser()
### Experimental Setups ###
parser.add_argument("--exp", default='exp_1', type=str) # Experiment ID
parser.add_argument('--device', default=0, type=int) # device, {"cpu", "cuda", "cuda:0", "cuda:1"}, etc
parser.add_argument("--env_name", default="walker2d-medium-expert-v2", type=str) # OpenAI gym environment name
parser.add_argument("--dir", default="results", type=str) # Logging directory
parser.add_argument("--seed", default=0, type=int) # Sets Gym, PyTorch and Numpy seeds
parser.add_argument("--num_steps_per_epoch", default=1000, type=int)
### Optimization Setups ###
parser.add_argument("--batch_size", default=256, type=int)
parser.add_argument("--lr_decay", action='store_true')
parser.add_argument('--early_stop', action='store_true')
parser.add_argument('--save_best_model', action='store_true')
### RL Parameters ###
parser.add_argument("--discount", default=0.99, type=float)
parser.add_argument("--tau", default=0.005, type=float)
### Diffusion Setting ###
parser.add_argument("--T", default=5, type=int)
parser.add_argument("--beta_schedule", default='vp', type=str)
### Algo Choice ###
parser.add_argument("--algo", default="ql", type=str) # ['bc', 'ql']
parser.add_argument("--ms", default='offline', type=str, help="['online', 'offline']")
# parser.add_argument("--top_k", default=1, type=int)
# parser.add_argument("--lr", default=3e-4, type=float)
# parser.add_argument("--eta", default=1.0, type=float)
# parser.add_argument("--max_q_backup", action='store_true')
# parser.add_argument("--reward_tune", default='no', type=str)
# parser.add_argument("--gn", default=-1.0, type=float)
args = parser.parse_args()
args.device = f"cuda:{args.device}" if torch.cuda.is_available() else "cpu"
args.output_dir = f'{args.dir}'
args.num_epochs = hyperparameters[args.env_name]['num_epochs']
args.eval_freq = hyperparameters[args.env_name]['eval_freq']
args.eval_episodes = 10 if 'v2' in args.env_name else 100
args.lr = hyperparameters[args.env_name]['lr']
args.eta = hyperparameters[args.env_name]['eta']
args.max_q_backup = hyperparameters[args.env_name]['max_q_backup']
args.reward_tune = hyperparameters[args.env_name]['reward_tune']
args.gn = hyperparameters[args.env_name]['gn']
args.top_k = hyperparameters[args.env_name]['top_k']
# Setup Logging
file_name = f"{args.env_name}|{args.exp}|diffusion-{args.algo}|T-{args.T}"
if args.lr_decay: file_name += '|lr_decay'
file_name += f'|ms-{args.ms}'
if args.ms == 'offline': file_name += f'|k-{args.top_k}'
file_name += f'|{args.seed}'
results_dir = os.path.join(args.output_dir, file_name)
if not os.path.exists(results_dir):
os.makedirs(results_dir)
utils.print_banner(f"Saving location: {results_dir}")
# if os.path.exists(os.path.join(results_dir, 'variant.json')):
# raise AssertionError("Experiment under this setting has been done!")
variant = vars(args)
variant.update(version=f"Diffusion-Policies-RL")
env = gym.make(args.env_name)
env.seed(args.seed)
torch.manual_seed(args.seed)
np.random.seed(args.seed)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
max_action = float(env.action_space.high[0])
variant.update(state_dim=state_dim)
variant.update(action_dim=action_dim)
variant.update(max_action=max_action)
setup_logger(os.path.basename(results_dir), variant=variant, log_dir=results_dir)
utils.print_banner(f"Env: {args.env_name}, state_dim: {state_dim}, action_dim: {action_dim}")
train_agent(env,
state_dim,
action_dim,
max_action,
args.device,
results_dir,
args)
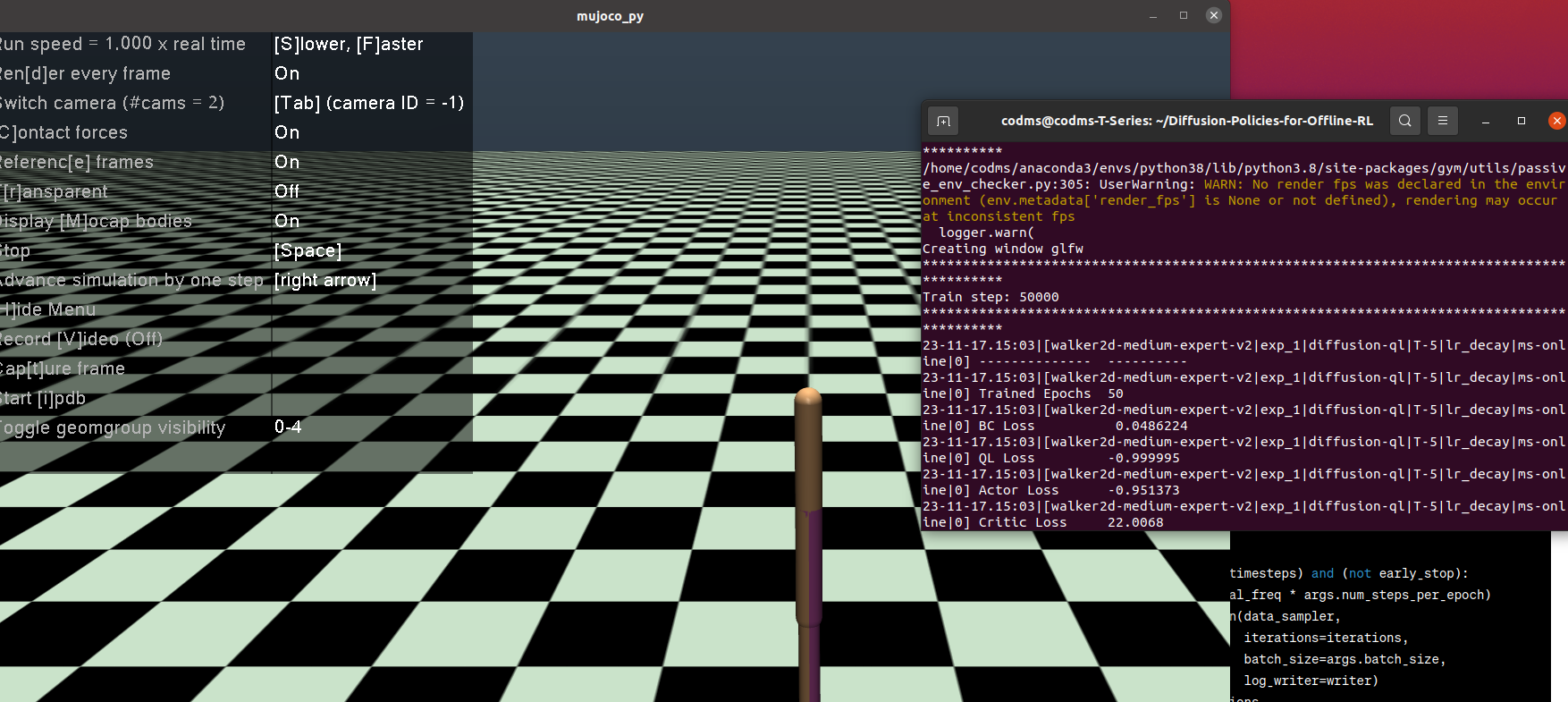
did it, but not moving video, just mujuco pic.
(4) did it..
# Copyright 2022 Twitter, Inc and Zhendong Wang.
# SPDX-License-Identifier: Apache-2.0
import argparse
import gym
import numpy as np
import os
import torch
import json
import d4rl
from utils import utils
from utils.data_sampler import Data_Sampler
from utils.logger import logger, setup_logger
from torch.utils.tensorboard import SummaryWriter
hyperparameters = {
'halfcheetah-medium-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 9.0, 'top_k': 1},
'hopper-medium-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 9.0, 'top_k': 2},
'walker2d-medium-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 1.0, 'top_k': 1},
'halfcheetah-medium-replay-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 2.0, 'top_k': 0},
'hopper-medium-replay-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 4.0, 'top_k': 2},
'walker2d-medium-replay-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 4.0, 'top_k': 1},
'halfcheetah-medium-expert-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 7.0, 'top_k': 0},
'hopper-medium-expert-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 5.0, 'top_k': 2},
'walker2d-medium-expert-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 5.0, 'top_k': 1},
'antmaze-umaze-v0': {'lr': 3e-4, 'eta': 0.5, 'max_q_backup': False, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 2.0, 'top_k': 2},
'antmaze-umaze-diverse-v0': {'lr': 3e-4, 'eta': 2.0, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 3.0, 'top_k': 2},
'antmaze-medium-play-v0': {'lr': 1e-3, 'eta': 2.0, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 2.0, 'top_k': 1},
'antmaze-medium-diverse-v0': {'lr': 3e-4, 'eta': 3.0, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 1.0, 'top_k': 1},
'antmaze-large-play-v0': {'lr': 3e-4, 'eta': 4.5, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 10.0, 'top_k': 2},
'antmaze-large-diverse-v0': {'lr': 3e-4, 'eta': 3.5, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 7.0, 'top_k': 1},
'pen-human-v1': {'lr': 3e-5, 'eta': 0.15, 'max_q_backup': False, 'reward_tune': 'normalize', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 7.0, 'top_k': 2},
'pen-cloned-v1': {'lr': 3e-5, 'eta': 0.1, 'max_q_backup': False, 'reward_tune': 'normalize', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 8.0, 'top_k': 2},
'kitchen-complete-v0': {'lr': 3e-4, 'eta': 0.005, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 250 , 'gn': 9.0, 'top_k': 2},
'kitchen-partial-v0': {'lr': 3e-4, 'eta': 0.005, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 10.0, 'top_k': 2},
'kitchen-mixed-v0': {'lr': 3e-4, 'eta': 0.005, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 10.0, 'top_k': 0},
}
def train_agent(env, state_dim, action_dim, max_action, device, output_dir, args):
# Load buffer
dataset = d4rl.qlearning_dataset(env)
data_sampler = Data_Sampler(dataset, device, args.reward_tune)
utils.print_banner('Loaded buffer')
if args.algo == 'ql':
from agents.ql_diffusion import Diffusion_QL as Agent
agent = Agent(state_dim=state_dim,
action_dim=action_dim,
max_action=max_action,
device=device,
discount=args.discount,
tau=args.tau,
max_q_backup=args.max_q_backup,
beta_schedule=args.beta_schedule,
n_timesteps=args.T,
eta=args.eta,
lr=args.lr,
lr_decay=args.lr_decay,
lr_maxt=args.num_epochs,
grad_norm=args.gn)
elif args.algo == 'bc':
from agents.bc_diffusion import Diffusion_BC as Agent
agent = Agent(state_dim=state_dim,
action_dim=action_dim,
max_action=max_action,
device=device,
discount=args.discount,
tau=args.tau,
beta_schedule=args.beta_schedule,
n_timesteps=args.T,
lr=args.lr)
early_stop = False
stop_check = utils.EarlyStopping(tolerance=1, min_delta=0.)
writer = None # SummaryWriter(output_dir)
evaluations = []
training_iters = 0
max_timesteps = args.num_epochs * args.num_steps_per_epoch
metric = 100.
utils.print_banner(f"Training Start", separator="*", num_star=90)
while (training_iters < max_timesteps) and (not early_stop):
iterations = int(args.eval_freq * args.num_steps_per_epoch)
loss_metric = agent.train(data_sampler,
iterations=iterations,
batch_size=args.batch_size,
log_writer=writer)
training_iters += iterations
curr_epoch = int(training_iters // int(args.num_steps_per_epoch))
# Logging
utils.print_banner(f"Train step: {training_iters}", separator="*", num_star=90)
logger.record_tabular('Trained Epochs', curr_epoch)
logger.record_tabular('BC Loss', np.mean(loss_metric['bc_loss']))
logger.record_tabular('QL Loss', np.mean(loss_metric['ql_loss']))
logger.record_tabular('Actor Loss', np.mean(loss_metric['actor_loss']))
logger.record_tabular('Critic Loss', np.mean(loss_metric['critic_loss']))
logger.dump_tabular()
# Evaluation
eval_res, eval_res_std, eval_norm_res, eval_norm_res_std = eval_policy(agent, args.env_name, args.seed,
eval_episodes=args.eval_episodes)
evaluations.append([eval_res, eval_res_std, eval_norm_res, eval_norm_res_std,
np.mean(loss_metric['bc_loss']), np.mean(loss_metric['ql_loss']),
np.mean(loss_metric['actor_loss']), np.mean(loss_metric['critic_loss']),
curr_epoch])
np.save(os.path.join(output_dir, "eval"), evaluations)
logger.record_tabular('Average Episodic Reward', eval_res)
logger.record_tabular('Average Episodic N-Reward', eval_norm_res)
logger.dump_tabular()
bc_loss = np.mean(loss_metric['bc_loss'])
if args.early_stop:
early_stop = stop_check(metric, bc_loss)
metric = bc_loss
if args.save_best_model:
agent.save_model(output_dir, curr_epoch)
# Model Selection: online or offline
scores = np.array(evaluations)
if args.ms == 'online':
best_id = np.argmax(scores[:, 2])
best_res = {'model selection': args.ms, 'epoch': scores[best_id, -1],
'best normalized score avg': scores[best_id, 2],
'best normalized score std': scores[best_id, 3],
'best raw score avg': scores[best_id, 0],
'best raw score std': scores[best_id, 1]}
with open(os.path.join(output_dir, f"best_score_{args.ms}.txt"), 'w') as f:
f.write(json.dumps(best_res))
elif args.ms == 'offline':
bc_loss = scores[:, 4]
top_k = min(len(bc_loss) - 1, args.top_k)
where_k = np.argsort(bc_loss) == top_k
best_res = {'model selection': args.ms, 'epoch': scores[where_k][0][-1],
'best normalized score avg': scores[where_k][0][2],
'best normalized score std': scores[where_k][0][3],
'best raw score avg': scores[where_k][0][0],
'best raw score std': scores[where_k][0][1]}
with open(os.path.join(output_dir, f"best_score_{args.ms}.txt"), 'w') as f:
f.write(json.dumps(best_res))
# writer.close()
# Runs policy for X episodes and returns average reward
# A fixed seed is used for the eval environment
def eval_policy(policy, env_name, seed, eval_episodes=10):
eval_env = gym.make(env_name)
eval_env.seed(seed + 100)
scores = []
for _ in range(eval_episodes):
traj_return = 0.
state, done = eval_env.reset(), False
while not done:
action = policy.sample_action(np.array(state))
state, reward, done, _ = eval_env.step(action)
traj_return += reward
eval_env.render()
eval_env.close()
scores.append(traj_return)
avg_reward = np.mean(scores)
std_reward = np.std(scores)
normalized_scores = [eval_env.get_normalized_score(s) for s in scores]
avg_norm_score = eval_env.get_normalized_score(avg_reward)
std_norm_score = np.std(normalized_scores)
utils.print_banner(f"Evaluation over {eval_episodes} episodes: {avg_reward:.2f} {avg_norm_score:.2f}")
return avg_reward, std_reward, avg_norm_score, std_norm_score
if __name__ == "__main__":
parser = argparse.ArgumentParser()
### Experimental Setups ###
parser.add_argument("--exp", default='exp_1', type=str) # Experiment ID
parser.add_argument('--device', default=0, type=int) # device, {"cpu", "cuda", "cuda:0", "cuda:1"}, etc
parser.add_argument("--env_name", default="walker2d-medium-expert-v2", type=str) # OpenAI gym environment name
parser.add_argument("--dir", default="results", type=str) # Logging directory
parser.add_argument("--seed", default=0, type=int) # Sets Gym, PyTorch and Numpy seeds
parser.add_argument("--num_steps_per_epoch", default=1000, type=int)
### Optimization Setups ###
parser.add_argument("--batch_size", default=256, type=int)
parser.add_argument("--lr_decay", action='store_true')
parser.add_argument('--early_stop', action='store_true')
parser.add_argument('--save_best_model', action='store_true')
### RL Parameters ###
parser.add_argument("--discount", default=0.99, type=float)
parser.add_argument("--tau", default=0.005, type=float)
### Diffusion Setting ###
parser.add_argument("--T", default=5, type=int)
parser.add_argument("--beta_schedule", default='vp', type=str)
### Algo Choice ###
parser.add_argument("--algo", default="ql", type=str) # ['bc', 'ql']
parser.add_argument("--ms", default='offline', type=str, help="['online', 'offline']")
# parser.add_argument("--top_k", default=1, type=int)
# parser.add_argument("--lr", default=3e-4, type=float)
# parser.add_argument("--eta", default=1.0, type=float)
# parser.add_argument("--max_q_backup", action='store_true')
# parser.add_argument("--reward_tune", default='no', type=str)
# parser.add_argument("--gn", default=-1.0, type=float)
args = parser.parse_args()
args.device = f"cuda:{args.device}" if torch.cuda.is_available() else "cpu"
args.output_dir = f'{args.dir}'
args.num_epochs = hyperparameters[args.env_name]['num_epochs']
args.eval_freq = hyperparameters[args.env_name]['eval_freq']
args.eval_episodes = 10 if 'v2' in args.env_name else 100
args.lr = hyperparameters[args.env_name]['lr']
args.eta = hyperparameters[args.env_name]['eta']
args.max_q_backup = hyperparameters[args.env_name]['max_q_backup']
args.reward_tune = hyperparameters[args.env_name]['reward_tune']
args.gn = hyperparameters[args.env_name]['gn']
args.top_k = hyperparameters[args.env_name]['top_k']
# Setup Logging
file_name = f"{args.env_name}|{args.exp}|diffusion-{args.algo}|T-{args.T}"
if args.lr_decay: file_name += '|lr_decay'
file_name += f'|ms-{args.ms}'
if args.ms == 'offline': file_name += f'|k-{args.top_k}'
file_name += f'|{args.seed}'
results_dir = os.path.join(args.output_dir, file_name)
if not os.path.exists(results_dir):
os.makedirs(results_dir)
utils.print_banner(f"Saving location: {results_dir}")
# if os.path.exists(os.path.join(results_dir, 'variant.json')):
# raise AssertionError("Experiment under this setting has been done!")
variant = vars(args)
variant.update(version=f"Diffusion-Policies-RL")
env = gym.make(args.env_name)
env.seed(args.seed)
torch.manual_seed(args.seed)
np.random.seed(args.seed)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
max_action = float(env.action_space.high[0])
variant.update(state_dim=state_dim)
variant.update(action_dim=action_dim)
variant.update(max_action=max_action)
setup_logger(os.path.basename(results_dir), variant=variant, log_dir=results_dir)
utils.print_banner(f"Env: {args.env_name}, state_dim: {state_dim}, action_dim: {action_dim}")
train_agent(env,
state_dim,
action_dim,
max_action,
args.device,
results_dir,
args)
now, we have to save video.
4. How to save video?
(1) first try
# Copyright 2022 Twitter, Inc and Zhendong Wang.
# SPDX-License-Identifier: Apache-2.0
import argparse
import gym
import numpy as np
import os
import torch
import json
import imageio
import d4rl
from utils import utils
from utils.data_sampler import Data_Sampler
from utils.logger import logger, setup_logger
from torch.utils.tensorboard import SummaryWriter
hyperparameters = {
'halfcheetah-medium-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 9.0, 'top_k': 1},
'hopper-medium-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 9.0, 'top_k': 2},
'walker2d-medium-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 1.0, 'top_k': 1},
'halfcheetah-medium-replay-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 2.0, 'top_k': 0},
'hopper-medium-replay-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 4.0, 'top_k': 2},
'walker2d-medium-replay-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 4.0, 'top_k': 1},
'halfcheetah-medium-expert-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 7.0, 'top_k': 0},
'hopper-medium-expert-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 5.0, 'top_k': 2},
'walker2d-medium-expert-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 5.0, 'top_k': 1},
'antmaze-umaze-v0': {'lr': 3e-4, 'eta': 0.5, 'max_q_backup': False, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 2.0, 'top_k': 2},
'antmaze-umaze-diverse-v0': {'lr': 3e-4, 'eta': 2.0, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 3.0, 'top_k': 2},
'antmaze-medium-play-v0': {'lr': 1e-3, 'eta': 2.0, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 2.0, 'top_k': 1},
'antmaze-medium-diverse-v0': {'lr': 3e-4, 'eta': 3.0, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 1.0, 'top_k': 1},
'antmaze-large-play-v0': {'lr': 3e-4, 'eta': 4.5, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 10.0, 'top_k': 2},
'antmaze-large-diverse-v0': {'lr': 3e-4, 'eta': 3.5, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 7.0, 'top_k': 1},
'pen-human-v1': {'lr': 3e-5, 'eta': 0.15, 'max_q_backup': False, 'reward_tune': 'normalize', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 7.0, 'top_k': 2},
'pen-cloned-v1': {'lr': 3e-5, 'eta': 0.1, 'max_q_backup': False, 'reward_tune': 'normalize', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 8.0, 'top_k': 2},
'kitchen-complete-v0': {'lr': 3e-4, 'eta': 0.005, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 250 , 'gn': 9.0, 'top_k': 2},
'kitchen-partial-v0': {'lr': 3e-4, 'eta': 0.005, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 10.0, 'top_k': 2},
'kitchen-mixed-v0': {'lr': 3e-4, 'eta': 0.005, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 10.0, 'top_k': 0},
}
def train_agent(env, state_dim, action_dim, max_action, device, output_dir, args):
# Load buffer
dataset = d4rl.qlearning_dataset(env)
data_sampler = Data_Sampler(dataset, device, args.reward_tune)
utils.print_banner('Loaded buffer')
if args.algo == 'ql':
from agents.ql_diffusion import Diffusion_QL as Agent
agent = Agent(state_dim=state_dim,
action_dim=action_dim,
max_action=max_action,
device=device,
discount=args.discount,
tau=args.tau,
max_q_backup=args.max_q_backup,
beta_schedule=args.beta_schedule,
n_timesteps=args.T,
eta=args.eta,
lr=args.lr,
lr_decay=args.lr_decay,
lr_maxt=args.num_epochs,
grad_norm=args.gn)
elif args.algo == 'bc':
from agents.bc_diffusion import Diffusion_BC as Agent
agent = Agent(state_dim=state_dim,
action_dim=action_dim,
max_action=max_action,
device=device,
discount=args.discount,
tau=args.tau,
beta_schedule=args.beta_schedule,
n_timesteps=args.T,
lr=args.lr)
early_stop = False
stop_check = utils.EarlyStopping(tolerance=1, min_delta=0.)
writer = None # SummaryWriter(output_dir)
evaluations = []
training_iters = 0
max_timesteps = args.num_epochs * args.num_steps_per_epoch
metric = 100.
utils.print_banner(f"Training Start", separator="*", num_star=90)
while (training_iters < max_timesteps) and (not early_stop):
iterations = int(args.eval_freq * args.num_steps_per_epoch)
loss_metric = agent.train(data_sampler,
iterations=iterations,
batch_size=args.batch_size,
log_writer=writer)
training_iters += iterations
curr_epoch = int(training_iters // int(args.num_steps_per_epoch))
# Logging
utils.print_banner(f"Train step: {training_iters}", separator="*", num_star=90)
logger.record_tabular('Trained Epochs', curr_epoch)
logger.record_tabular('BC Loss', np.mean(loss_metric['bc_loss']))
logger.record_tabular('QL Loss', np.mean(loss_metric['ql_loss']))
logger.record_tabular('Actor Loss', np.mean(loss_metric['actor_loss']))
logger.record_tabular('Critic Loss', np.mean(loss_metric['critic_loss']))
logger.dump_tabular()
# Evaluation
eval_res, eval_res_std, eval_norm_res, eval_norm_res_std = eval_policy(agent, args.env_name, args.seed,
eval_episodes=args.eval_episodes, save_video=True)
evaluations.append([eval_res, eval_res_std, eval_norm_res, eval_norm_res_std,
np.mean(loss_metric['bc_loss']), np.mean(loss_metric['ql_loss']),
np.mean(loss_metric['actor_loss']), np.mean(loss_metric['critic_loss']),
curr_epoch])
np.save(os.path.join(output_dir, "eval"), evaluations)
logger.record_tabular('Average Episodic Reward', eval_res)
logger.record_tabular('Average Episodic N-Reward', eval_norm_res)
logger.dump_tabular()
bc_loss = np.mean(loss_metric['bc_loss'])
if args.early_stop:
early_stop = stop_check(metric, bc_loss)
metric = bc_loss
if args.save_best_model:
agent.save_model(output_dir, curr_epoch)
# Model Selection: online or offline
scores = np.array(evaluations)
if args.ms == 'online':
best_id = np.argmax(scores[:, 2])
best_res = {'model selection': args.ms, 'epoch': scores[best_id, -1],
'best normalized score avg': scores[best_id, 2],
'best normalized score std': scores[best_id, 3],
'best raw score avg': scores[best_id, 0],
'best raw score std': scores[best_id, 1]}
with open(os.path.join(output_dir, f"best_score_{args.ms}.txt"), 'w') as f:
f.write(json.dumps(best_res))
elif args.ms == 'offline':
bc_loss = scores[:, 4]
top_k = min(len(bc_loss) - 1, args.top_k)
where_k = np.argsort(bc_loss) == top_k
best_res = {'model selection': args.ms, 'epoch': scores[where_k][0][-1],
'best normalized score avg': scores[where_k][0][2],
'best normalized score std': scores[where_k][0][3],
'best raw score avg': scores[where_k][0][0],
'best raw score std': scores[where_k][0][1]}
with open(os.path.join(output_dir, f"best_score_{args.ms}.txt"), 'w') as f:
f.write(json.dumps(best_res))
# writer.close()
# Runs policy for X episodes and returns average reward
# A fixed seed is used for the eval environment
def eval_policy(policy, env_name, seed, eval_episodes=10, save_video=False):
eval_env = gym.make(env_name)
eval_env.seed(seed + 100)
scores = []
i = 0
for _ in range(eval_episodes):
traj_return = 0.
state, done = eval_env.reset(), False
# Setup video recording
if save_video:
video_path = os.path.join("videos", f"{env_name}_episode_{i}.mp4")
writer = imageio.get_writer(video_path, fps=20)
i += 1
while not done:
action = policy.sample_action(np.array(state))
state, reward, done, _ = eval_env.step(action)
traj_return += reward
eval_env.render()
# Save the frame to the video
if save_video:
frame = eval_env.render(mode='rgb_array')
writer.append_data(frame)
eval_env.close()
scores.append(traj_return)
if save_video:
writer.close()
avg_reward = np.mean(scores)
std_reward = np.std(scores)
normalized_scores = [eval_env.get_normalized_score(s) for s in scores]
avg_norm_score = eval_env.get_normalized_score(avg_reward)
std_norm_score = np.std(normalized_scores)
utils.print_banner(f"Evaluation over {eval_episodes} episodes: {avg_reward:.2f} {avg_norm_score:.2f}")
return avg_reward, std_reward, avg_norm_score, std_norm_score
if __name__ == "__main__":
parser = argparse.ArgumentParser()
### Experimental Setups ###
parser.add_argument("--exp", default='exp_1', type=str) # Experiment ID
parser.add_argument('--device', default=0, type=int) # device, {"cpu", "cuda", "cuda:0", "cuda:1"}, etc
parser.add_argument("--env_name", default="walker2d-medium-expert-v2", type=str) # OpenAI gym environment name
parser.add_argument("--dir", default="results", type=str) # Logging directory
parser.add_argument("--seed", default=0, type=int) # Sets Gym, PyTorch and Numpy seeds
parser.add_argument("--num_steps_per_epoch", default=1000, type=int)
### Optimization Setups ###
parser.add_argument("--batch_size", default=256, type=int)
parser.add_argument("--lr_decay", action='store_true')
parser.add_argument('--early_stop', action='store_true')
parser.add_argument('--save_best_model', action='store_true')
### RL Parameters ###
parser.add_argument("--discount", default=0.99, type=float)
parser.add_argument("--tau", default=0.005, type=float)
### Diffusion Setting ###
parser.add_argument("--T", default=5, type=int)
parser.add_argument("--beta_schedule", default='vp', type=str)
### Algo Choice ###
parser.add_argument("--algo", default="ql", type=str) # ['bc', 'ql']
parser.add_argument("--ms", default='offline', type=str, help="['online', 'offline']")
# parser.add_argument("--top_k", default=1, type=int)
# parser.add_argument("--lr", default=3e-4, type=float)
# parser.add_argument("--eta", default=1.0, type=float)
# parser.add_argument("--max_q_backup", action='store_true')
# parser.add_argument("--reward_tune", default='no', type=str)
# parser.add_argument("--gn", default=-1.0, type=float)
args = parser.parse_args()
args.device = f"cuda:{args.device}" if torch.cuda.is_available() else "cpu"
args.output_dir = f'{args.dir}'
args.num_epochs = hyperparameters[args.env_name]['num_epochs']
args.eval_freq = hyperparameters[args.env_name]['eval_freq']
args.eval_episodes = 10 if 'v2' in args.env_name else 100
args.lr = hyperparameters[args.env_name]['lr']
args.eta = hyperparameters[args.env_name]['eta']
args.max_q_backup = hyperparameters[args.env_name]['max_q_backup']
args.reward_tune = hyperparameters[args.env_name]['reward_tune']
args.gn = hyperparameters[args.env_name]['gn']
args.top_k = hyperparameters[args.env_name]['top_k']
# Setup Logging
file_name = f"{args.env_name}|{args.exp}|diffusion-{args.algo}|T-{args.T}"
if args.lr_decay: file_name += '|lr_decay'
file_name += f'|ms-{args.ms}'
if args.ms == 'offline': file_name += f'|k-{args.top_k}'
file_name += f'|{args.seed}'
results_dir = os.path.join(args.output_dir, file_name)
if not os.path.exists(results_dir):
os.makedirs(results_dir)
utils.print_banner(f"Saving location: {results_dir}")
# if os.path.exists(os.path.join(results_dir, 'variant.json')):
# raise AssertionError("Experiment under this setting has been done!")
variant = vars(args)
variant.update(version=f"Diffusion-Policies-RL")
env = gym.make(args.env_name)
env.seed(args.seed)
torch.manual_seed(args.seed)
np.random.seed(args.seed)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
max_action = float(env.action_space.high[0])
variant.update(state_dim=state_dim)
variant.update(action_dim=action_dim)
variant.update(max_action=max_action)
setup_logger(os.path.basename(results_dir), variant=variant, log_dir=results_dir)
utils.print_banner(f"Env: {args.env_name}, state_dim: {state_dim}, action_dim: {action_dim}")
train_agent(env,
state_dim,
action_dim,
max_action,
args.device,
results_dir,
args)
(2) another way to save video..
# Copyright 2022 Twitter, Inc and Zhendong Wang.
# SPDX-License-Identifier: Apache-2.0
import argparse
import gym
import numpy as np
import os
import torch
import json
import imageio
import d4rl
from utils import utils
from utils.data_sampler import Data_Sampler
from utils.logger import logger, setup_logger
from torch.utils.tensorboard import SummaryWriter
hyperparameters = {
'halfcheetah-medium-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 9.0, 'top_k': 1},
'hopper-medium-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 9.0, 'top_k': 2},
'walker2d-medium-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 1.0, 'top_k': 1},
'halfcheetah-medium-replay-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 2.0, 'top_k': 0},
'hopper-medium-replay-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 4.0, 'top_k': 2},
'walker2d-medium-replay-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 4.0, 'top_k': 1},
'halfcheetah-medium-expert-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 7.0, 'top_k': 0},
'hopper-medium-expert-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 5.0, 'top_k': 2},
'walker2d-medium-expert-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 5.0, 'top_k': 1},
'antmaze-umaze-v0': {'lr': 3e-4, 'eta': 0.5, 'max_q_backup': False, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 2.0, 'top_k': 2},
'antmaze-umaze-diverse-v0': {'lr': 3e-4, 'eta': 2.0, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 3.0, 'top_k': 2},
'antmaze-medium-play-v0': {'lr': 1e-3, 'eta': 2.0, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 2.0, 'top_k': 1},
'antmaze-medium-diverse-v0': {'lr': 3e-4, 'eta': 3.0, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 1.0, 'top_k': 1},
'antmaze-large-play-v0': {'lr': 3e-4, 'eta': 4.5, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 10.0, 'top_k': 2},
'antmaze-large-diverse-v0': {'lr': 3e-4, 'eta': 3.5, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 7.0, 'top_k': 1},
'pen-human-v1': {'lr': 3e-5, 'eta': 0.15, 'max_q_backup': False, 'reward_tune': 'normalize', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 7.0, 'top_k': 2},
'pen-cloned-v1': {'lr': 3e-5, 'eta': 0.1, 'max_q_backup': False, 'reward_tune': 'normalize', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 8.0, 'top_k': 2},
'kitchen-complete-v0': {'lr': 3e-4, 'eta': 0.005, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 250 , 'gn': 9.0, 'top_k': 2},
'kitchen-partial-v0': {'lr': 3e-4, 'eta': 0.005, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 10.0, 'top_k': 2},
'kitchen-mixed-v0': {'lr': 3e-4, 'eta': 0.005, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 10.0, 'top_k': 0},
}
def train_agent(env, state_dim, action_dim, max_action, device, output_dir, args):
# Load buffer
dataset = d4rl.qlearning_dataset(env)
data_sampler = Data_Sampler(dataset, device, args.reward_tune)
utils.print_banner('Loaded buffer')
if args.algo == 'ql':
from agents.ql_diffusion import Diffusion_QL as Agent
agent = Agent(state_dim=state_dim,
action_dim=action_dim,
max_action=max_action,
device=device,
discount=args.discount,
tau=args.tau,
max_q_backup=args.max_q_backup,
beta_schedule=args.beta_schedule,
n_timesteps=args.T,
eta=args.eta,
lr=args.lr,
lr_decay=args.lr_decay,
lr_maxt=args.num_epochs,
grad_norm=args.gn)
elif args.algo == 'bc':
from agents.bc_diffusion import Diffusion_BC as Agent
agent = Agent(state_dim=state_dim,
action_dim=action_dim,
max_action=max_action,
device=device,
discount=args.discount,
tau=args.tau,
beta_schedule=args.beta_schedule,
n_timesteps=args.T,
lr=args.lr)
early_stop = False
stop_check = utils.EarlyStopping(tolerance=1, min_delta=0.)
writer = None # SummaryWriter(output_dir)
evaluations = []
training_iters = 0
max_timesteps = args.num_epochs * args.num_steps_per_epoch
metric = 100.
utils.print_banner(f"Training Start", separator="*", num_star=90)
while (training_iters < max_timesteps) and (not early_stop):
iterations = int(args.eval_freq * args.num_steps_per_epoch)
loss_metric = agent.train(data_sampler,
iterations=iterations,
batch_size=args.batch_size,
log_writer=writer)
training_iters += iterations
curr_epoch = int(training_iters // int(args.num_steps_per_epoch))
# Logging
utils.print_banner(f"Train step: {training_iters}", separator="*", num_star=90)
logger.record_tabular('Trained Epochs', curr_epoch)
logger.record_tabular('BC Loss', np.mean(loss_metric['bc_loss']))
logger.record_tabular('QL Loss', np.mean(loss_metric['ql_loss']))
logger.record_tabular('Actor Loss', np.mean(loss_metric['actor_loss']))
logger.record_tabular('Critic Loss', np.mean(loss_metric['critic_loss']))
logger.dump_tabular()
# Evaluation
eval_res, eval_res_std, eval_norm_res, eval_norm_res_std = eval_policy(agent, args.env_name, args.seed,
eval_episodes=args.eval_episodes, save_video=True)
evaluations.append([eval_res, eval_res_std, eval_norm_res, eval_norm_res_std,
np.mean(loss_metric['bc_loss']), np.mean(loss_metric['ql_loss']),
np.mean(loss_metric['actor_loss']), np.mean(loss_metric['critic_loss']),
curr_epoch])
np.save(os.path.join(output_dir, "eval"), evaluations)
logger.record_tabular('Average Episodic Reward', eval_res)
logger.record_tabular('Average Episodic N-Reward', eval_norm_res)
logger.dump_tabular()
bc_loss = np.mean(loss_metric['bc_loss'])
if args.early_stop:
early_stop = stop_check(metric, bc_loss)
metric = bc_loss
if args.save_best_model:
agent.save_model(output_dir, curr_epoch)
# Model Selection: online or offline
scores = np.array(evaluations)
if args.ms == 'online':
best_id = np.argmax(scores[:, 2])
best_res = {'model selection': args.ms, 'epoch': scores[best_id, -1],
'best normalized score avg': scores[best_id, 2],
'best normalized score std': scores[best_id, 3],
'best raw score avg': scores[best_id, 0],
'best raw score std': scores[best_id, 1]}
with open(os.path.join(output_dir, f"best_score_{args.ms}.txt"), 'w') as f:
f.write(json.dumps(best_res))
elif args.ms == 'offline':
bc_loss = scores[:, 4]
top_k = min(len(bc_loss) - 1, args.top_k)
where_k = np.argsort(bc_loss) == top_k
best_res = {'model selection': args.ms, 'epoch': scores[where_k][0][-1],
'best normalized score avg': scores[where_k][0][2],
'best normalized score std': scores[where_k][0][3],
'best raw score avg': scores[where_k][0][0],
'best raw score std': scores[where_k][0][1]}
with open(os.path.join(output_dir, f"best_score_{args.ms}.txt"), 'w') as f:
f.write(json.dumps(best_res))
# writer.close()
# Runs policy for X episodes and returns average reward
# A fixed seed is used for the eval environment
def eval_policy(policy, env_name, seed, eval_episodes=10, save_video=True):
eval_env = gym.make(env_name)
eval_env.seed(seed + 100)
scores = []
images = []
for _ in range(eval_episodes):
traj_return = 0.
state, done = eval_env.reset(), False
while not done:
action = policy.sample_action(np.array(state))
state, reward, done, _ = eval_env.step(action)
traj_return += reward
images.append(eval_env.render(mode='rgb_array'))
eval_env.close()
scores.append(traj_return)
avg_reward = np.mean(scores)
std_reward = np.std(scores)
normalized_scores = [eval_env.get_normalized_score(s) for s in scores]
avg_norm_score = eval_env.get_normalized_score(avg_reward)
std_norm_score = np.std(normalized_scores)
utils.print_banner(f"Evaluation over {eval_episodes} episodes: {avg_reward:.2f} {avg_norm_score:.2f}")
if save_video:
video_path = os.path.join('videos', f'evaluation_{env_name}.gif')
imageio.mimsave(video_path, images, fps=eval_env.metadata['video.frames_per_second'])
utils.print_banner(f"Saved evaluation video to: {video_path}")
return avg_reward, std_reward, avg_norm_score, std_norm_score
if __name__ == "__main__":
parser = argparse.ArgumentParser()
### Experimental Setups ###
parser.add_argument("--exp", default='exp_1', type=str) # Experiment ID
parser.add_argument('--device', default=0, type=int) # device, {"cpu", "cuda", "cuda:0", "cuda:1"}, etc
parser.add_argument("--env_name", default="walker2d-medium-expert-v2", type=str) # OpenAI gym environment name
parser.add_argument("--dir", default="results", type=str) # Logging directory
parser.add_argument("--seed", default=0, type=int) # Sets Gym, PyTorch and Numpy seeds
parser.add_argument("--num_steps_per_epoch", default=1000, type=int)
### Optimization Setups ###
parser.add_argument("--batch_size", default=256, type=int)
parser.add_argument("--lr_decay", action='store_true')
parser.add_argument('--early_stop', action='store_true')
parser.add_argument('--save_best_model', action='store_true')
### RL Parameters ###
parser.add_argument("--discount", default=0.99, type=float)
parser.add_argument("--tau", default=0.005, type=float)
### Diffusion Setting ###
parser.add_argument("--T", default=5, type=int)
parser.add_argument("--beta_schedule", default='vp', type=str)
### Algo Choice ###
parser.add_argument("--algo", default="ql", type=str) # ['bc', 'ql']
parser.add_argument("--ms", default='offline', type=str, help="['online', 'offline']")
# parser.add_argument("--top_k", default=1, type=int)
# parser.add_argument("--lr", default=3e-4, type=float)
# parser.add_argument("--eta", default=1.0, type=float)
# parser.add_argument("--max_q_backup", action='store_true')
# parser.add_argument("--reward_tune", default='no', type=str)
# parser.add_argument("--gn", default=-1.0, type=float)
args = parser.parse_args()
args.device = f"cuda:{args.device}" if torch.cuda.is_available() else "cpu"
args.output_dir = f'{args.dir}'
args.num_epochs = hyperparameters[args.env_name]['num_epochs']
args.eval_freq = hyperparameters[args.env_name]['eval_freq']
args.eval_episodes = 10 if 'v2' in args.env_name else 100
args.lr = hyperparameters[args.env_name]['lr']
args.eta = hyperparameters[args.env_name]['eta']
args.max_q_backup = hyperparameters[args.env_name]['max_q_backup']
args.reward_tune = hyperparameters[args.env_name]['reward_tune']
args.gn = hyperparameters[args.env_name]['gn']
args.top_k = hyperparameters[args.env_name]['top_k']
# Setup Logging
file_name = f"{args.env_name}|{args.exp}|diffusion-{args.algo}|T-{args.T}"
if args.lr_decay: file_name += '|lr_decay'
file_name += f'|ms-{args.ms}'
if args.ms == 'offline': file_name += f'|k-{args.top_k}'
file_name += f'|{args.seed}'
results_dir = os.path.join(args.output_dir, file_name)
if not os.path.exists(results_dir):
os.makedirs(results_dir)
utils.print_banner(f"Saving location: {results_dir}")
# if os.path.exists(os.path.join(results_dir, 'variant.json')):
# raise AssertionError("Experiment under this setting has been done!")
variant = vars(args)
variant.update(version=f"Diffusion-Policies-RL")
env = gym.make(args.env_name)
env.seed(args.seed)
torch.manual_seed(args.seed)
np.random.seed(args.seed)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
max_action = float(env.action_space.high[0])
variant.update(state_dim=state_dim)
variant.update(action_dim=action_dim)
variant.update(max_action=max_action)
setup_logger(os.path.basename(results_dir), variant=variant, log_dir=results_dir)
utils.print_banner(f"Env: {args.env_name}, state_dim: {state_dim}, action_dim: {action_dim}")
train_agent(env,
state_dim,
action_dim,
max_action,
args.device,
results_dir,
args)
(3) the end
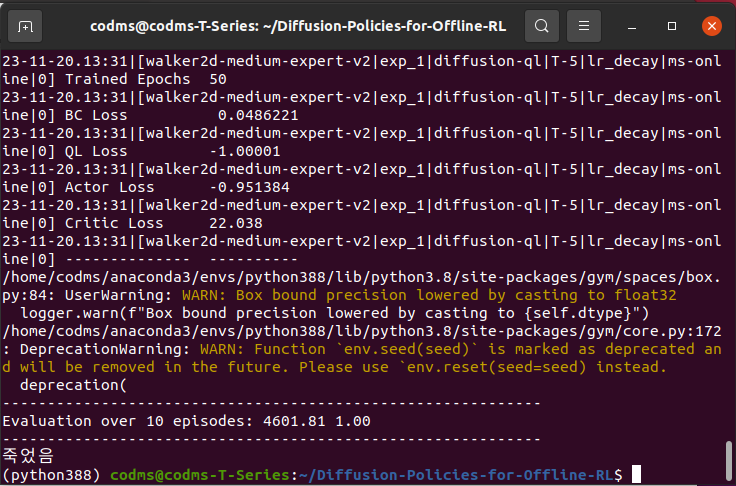
we decided to just record display.. haha :) :(
so the result is ..
# Copyright 2022 Twitter, Inc and Zhendong Wang.
# SPDX-License-Identifier: Apache-2.0
import argparse
import gym
import numpy as np
import os
import torch
import json
import d4rl
from utils import utils
from utils.data_sampler import Data_Sampler
from utils.logger import logger, setup_logger
from torch.utils.tensorboard import SummaryWriter
hyperparameters = {
'halfcheetah-medium-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 9.0, 'top_k': 1},
'hopper-medium-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 9.0, 'top_k': 2},
'walker2d-medium-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 1.0, 'top_k': 1},
'halfcheetah-medium-replay-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 2.0, 'top_k': 0},
'hopper-medium-replay-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 4.0, 'top_k': 2},
'walker2d-medium-replay-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 4.0, 'top_k': 1},
'halfcheetah-medium-expert-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 7.0, 'top_k': 0},
'hopper-medium-expert-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 5.0, 'top_k': 2},
'walker2d-medium-expert-v2': {'lr': 3e-4, 'eta': 1.0, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 2000, 'gn': 5.0, 'top_k': 1},
'antmaze-umaze-v0': {'lr': 3e-4, 'eta': 0.5, 'max_q_backup': False, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 2.0, 'top_k': 2},
'antmaze-umaze-diverse-v0': {'lr': 3e-4, 'eta': 2.0, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 3.0, 'top_k': 2},
'antmaze-medium-play-v0': {'lr': 1e-3, 'eta': 2.0, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 2.0, 'top_k': 1},
'antmaze-medium-diverse-v0': {'lr': 3e-4, 'eta': 3.0, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 1.0, 'top_k': 1},
'antmaze-large-play-v0': {'lr': 3e-4, 'eta': 4.5, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 10.0, 'top_k': 2},
'antmaze-large-diverse-v0': {'lr': 3e-4, 'eta': 3.5, 'max_q_backup': True, 'reward_tune': 'cql_antmaze', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 7.0, 'top_k': 1},
'pen-human-v1': {'lr': 3e-5, 'eta': 0.15, 'max_q_backup': False, 'reward_tune': 'normalize', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 7.0, 'top_k': 2},
'pen-cloned-v1': {'lr': 3e-5, 'eta': 0.1, 'max_q_backup': False, 'reward_tune': 'normalize', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 8.0, 'top_k': 2},
'kitchen-complete-v0': {'lr': 3e-4, 'eta': 0.005, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 250 , 'gn': 9.0, 'top_k': 2},
'kitchen-partial-v0': {'lr': 3e-4, 'eta': 0.005, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 10.0, 'top_k': 2},
'kitchen-mixed-v0': {'lr': 3e-4, 'eta': 0.005, 'max_q_backup': False, 'reward_tune': 'no', 'eval_freq': 50, 'num_epochs': 1000, 'gn': 10.0, 'top_k': 0},
}
def train_agent(env, state_dim, action_dim, max_action, device, output_dir, args):
# Load buffer
dataset = d4rl.qlearning_dataset(env)
data_sampler = Data_Sampler(dataset, device, args.reward_tune)
utils.print_banner('Loaded buffer')
if args.algo == 'ql':
from agents.ql_diffusion import Diffusion_QL as Agent
agent = Agent(state_dim=state_dim,
action_dim=action_dim,
max_action=max_action,
device=device,
discount=args.discount,
tau=args.tau,
max_q_backup=args.max_q_backup,
beta_schedule=args.beta_schedule,
n_timesteps=args.T,
eta=args.eta,
lr=args.lr,
lr_decay=args.lr_decay,
lr_maxt=args.num_epochs,
grad_norm=args.gn)
elif args.algo == 'bc':
from agents.bc_diffusion import Diffusion_BC as Agent
agent = Agent(state_dim=state_dim,
action_dim=action_dim,
max_action=max_action,
device=device,
discount=args.discount,
tau=args.tau,
beta_schedule=args.beta_schedule,
n_timesteps=args.T,
lr=args.lr)
early_stop = False
stop_check = utils.EarlyStopping(tolerance=1, min_delta=0.)
writer = None # SummaryWriter(output_dir)
evaluations = []
training_iters = 0
max_timesteps = args.num_epochs * args.num_steps_per_epoch
metric = 100.
utils.print_banner(f"Training Start", separator="*", num_star=90)
while (training_iters < max_timesteps) and (not early_stop):
iterations = int(args.eval_freq * args.num_steps_per_epoch)
loss_metric = agent.train(data_sampler,
iterations=iterations,
batch_size=args.batch_size,
log_writer=writer)
training_iters += iterations
curr_epoch = int(training_iters // int(args.num_steps_per_epoch))
# Logging
utils.print_banner(f"Train step: {training_iters}", separator="*", num_star=90)
logger.record_tabular('Trained Epochs', curr_epoch)
logger.record_tabular('BC Loss', np.mean(loss_metric['bc_loss']))
logger.record_tabular('QL Loss', np.mean(loss_metric['ql_loss']))
logger.record_tabular('Actor Loss', np.mean(loss_metric['actor_loss']))
logger.record_tabular('Critic Loss', np.mean(loss_metric['critic_loss']))
logger.dump_tabular()
# Evaluation
eval_res, eval_res_std, eval_norm_res, eval_norm_res_std = eval_policy(agent, args.env_name, args.seed,
eval_episodes=args.eval_episodes)
evaluations.append([eval_res, eval_res_std, eval_norm_res, eval_norm_res_std,
np.mean(loss_metric['bc_loss']), np.mean(loss_metric['ql_loss']),
np.mean(loss_metric['actor_loss']), np.mean(loss_metric['critic_loss']),
curr_epoch])
np.save(os.path.join(output_dir, "eval"), evaluations)
logger.record_tabular('Average Episodic Reward', eval_res)
logger.record_tabular('Average Episodic N-Reward', eval_norm_res)
logger.dump_tabular()
bc_loss = np.mean(loss_metric['bc_loss'])
if args.early_stop:
early_stop = stop_check(metric, bc_loss)
metric = bc_loss
if args.save_best_model:
agent.save_model(output_dir, curr_epoch)
# Model Selection: online or offline
scores = np.array(evaluations)
if args.ms == 'online':
best_id = np.argmax(scores[:, 2])
best_res = {'model selection': args.ms, 'epoch': scores[best_id, -1],
'best normalized score avg': scores[best_id, 2],
'best normalized score std': scores[best_id, 3],
'best raw score avg': scores[best_id, 0],
'best raw score std': scores[best_id, 1]}
with open(os.path.join(output_dir, f"best_score_{args.ms}.txt"), 'w') as f:
f.write(json.dumps(best_res))
elif args.ms == 'offline':
bc_loss = scores[:, 4]
top_k = min(len(bc_loss) - 1, args.top_k)
where_k = np.argsort(bc_loss) == top_k
best_res = {'model selection': args.ms, 'epoch': scores[where_k][0][-1],
'best normalized score avg': scores[where_k][0][2],
'best normalized score std': scores[where_k][0][3],
'best raw score avg': scores[where_k][0][0],
'best raw score std': scores[where_k][0][1]}
with open(os.path.join(output_dir, f"best_score_{args.ms}.txt"), 'w') as f:
f.write(json.dumps(best_res))
# writer.close()
# Runs policy for X episodes and returns average reward
# A fixed seed is used for the eval environment
def eval_policy(policy, env_name, seed, eval_episodes=10):
eval_env = gym.make(env_name)
eval_env.seed(seed + 100)
scores = []
for _ in range(eval_episodes):
traj_return = 0.
state, done = eval_env.reset(), False
while not done:
action = policy.sample_action(np.array(state))
state, reward, done, _ = eval_env.step(action)
traj_return += reward
# eval_env.render()
# eval_env.close()
scores.append(traj_return)
avg_reward = np.mean(scores)
std_reward = np.std(scores)
normalized_scores = [eval_env.get_normalized_score(s) for s in scores]
avg_norm_score = eval_env.get_normalized_score(avg_reward)
std_norm_score = np.std(normalized_scores)
utils.print_banner(f"Evaluation over {eval_episodes} episodes: {avg_reward:.2f} {avg_norm_score:.2f}")
utils.print_banner(f"State : {state} action : {action}")
return avg_reward, std_reward, avg_norm_score, std_norm_score
if __name__ == "__main__":
parser = argparse.ArgumentParser()
### Experimental Setups ###
parser.add_argument("--exp", default='exp_1', type=str) # Experiment ID
parser.add_argument('--device', default=0, type=int) # device, {"cpu", "cuda", "cuda:0", "cuda:1"}, etc
parser.add_argument("--env_name", default="walker2d-medium-expert-v2", type=str) # OpenAI gym environment name
parser.add_argument("--dir", default="results", type=str) # Logging directory
parser.add_argument("--seed", default=0, type=int) # Sets Gym, PyTorch and Numpy seeds
parser.add_argument("--num_steps_per_epoch", default=1000, type=int)
### Optimization Setups ###
parser.add_argument("--batch_size", default=256, type=int)
parser.add_argument("--lr_decay", action='store_true')
parser.add_argument('--early_stop', action='store_true')
parser.add_argument('--save_best_model', action='store_true')
### RL Parameters ###
parser.add_argument("--discount", default=0.99, type=float)
parser.add_argument("--tau", default=0.005, type=float)
### Diffusion Setting ###
parser.add_argument("--T", default=5, type=int)
parser.add_argument("--beta_schedule", default='vp', type=str)
### Algo Choice ###
parser.add_argument("--algo", default="ql", type=str) # ['bc', 'ql']
parser.add_argument("--ms", default='offline', type=str, help="['online', 'offline']")
# parser.add_argument("--top_k", default=1, type=int)
# parser.add_argument("--lr", default=3e-4, type=float)
# parser.add_argument("--eta", default=1.0, type=float)
# parser.add_argument("--max_q_backup", action='store_true')
# parser.add_argument("--reward_tune", default='no', type=str)
# parser.add_argument("--gn", default=-1.0, type=float)
args = parser.parse_args()
args.device = f"cuda:{args.device}" if torch.cuda.is_available() else "cpu"
args.output_dir = f'{args.dir}'
args.num_epochs = hyperparameters[args.env_name]['num_epochs']
args.eval_freq = hyperparameters[args.env_name]['eval_freq']
args.eval_episodes = 10 if 'v2' in args.env_name else 100
args.lr = hyperparameters[args.env_name]['lr']
args.eta = hyperparameters[args.env_name]['eta']
args.max_q_backup = hyperparameters[args.env_name]['max_q_backup']
args.reward_tune = hyperparameters[args.env_name]['reward_tune']
args.gn = hyperparameters[args.env_name]['gn']
args.top_k = hyperparameters[args.env_name]['top_k']
# Setup Logging
file_name = f"{args.env_name}|{args.exp}|diffusion-{args.algo}|T-{args.T}"
if args.lr_decay: file_name += '|lr_decay'
file_name += f'|ms-{args.ms}'
if args.ms == 'offline': file_name += f'|k-{args.top_k}'
file_name += f'|{args.seed}'
results_dir = os.path.join(args.output_dir, file_name)
if not os.path.exists(results_dir):
os.makedirs(results_dir)
utils.print_banner(f"Saving location: {results_dir}")
# if os.path.exists(os.path.join(results_dir, 'variant.json')):
# raise AssertionError("Experiment under this setting has been done!")
variant = vars(args)
variant.update(version=f"Diffusion-Policies-RL")
env = gym.make(args.env_name)
env.seed(args.seed)
torch.manual_seed(args.seed)
np.random.seed(args.seed)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
max_action = float(env.action_space.high[0])
variant.update(state_dim=state_dim)
variant.update(action_dim=action_dim)
variant.update(max_action=max_action)
setup_logger(os.path.basename(results_dir), variant=variant, log_dir=results_dir)
utils.print_banner(f"Env: {args.env_name}, state_dim: {state_dim}, action_dim: {action_dim}")
train_agent(env,
state_dim,
action_dim,
max_action,
args.device,
results_dir,
args)
5. Visual studio code - running
(0) install VS code
https://phoenixnap.com/kb/install-vscode-ubuntu
(1) install node.js
https://github.com/nodejs/Release
(2) debuging
-> conda install cycler, pip install kiwisolver, Attributeerror: module matplotlib has no attribute get_data_path(pip show matplotlib, pip install --upgrade matplotlib, pip uninstall matplotlib, pip install matplotlib) : https://itsourcecode.com/attributeerror/attributeerror-module-matplotlib-has-no-attribute-get_data_path/,
-> and this.
import pickle
expert = ReplayMemory(10000)
with open('expert.pkl', 'rb') as f:
expert = pickle.load(f)
print(expert.memory[500])
import torch
torch.save(expert, 'expert.pth')
expert = torch.load('expert.pth', map_location=torch.device('cpu'))
print(expert.memory[500])
->



