논문 : https://arxiv.org/abs/2310.07297
Score Regularized Policy Optimization through Diffusion Behavior
Recent developments in offline reinforcement learning have uncovered the immense potential of diffusion modeling, which excels at representing heterogeneous behavior policies. However, sampling from diffusion policies is considerably slow because it necess
arxiv.org
0. Abstract
Offline RL 분야에서 Diffusion modeling은 heterogeneous behavior policy, 이질적인 행동 정책을 표현하는 데에 효과적이다. 그러나 diffusion policy의 샘플링은 수십에서 수백 번의 반복적인 추론 단계가 필요하므로 상당히 느리다. 이 문제를 해결하기 위해 우리는 효과적인 deterministic inference policy를 크리틱 모델과 사전 훈련된 diffusion 행동 모델에서부터 추출하고, 최적화 동안 행동 분포의 score functino을 활용하여 정책 그래디언트를 regularize(규제, 정규화)한다. D4RL 작업에서의 결과는 해당 방법이 다양한 방법들과 비교하였을 때 약 25배 이상의 행동 샘플링 속도 향상을 보였다.

1. introduction
Offline RL은 미리 수집된 행동 데이터 셋을 이용하여 decision-making 문제에 대처한다. 해당 분야에서의 주용한 과제 중 하나는 학습된 정책(policy)이 행동 분포(behavior distribution)를 지원하는 것을 보장하는 행동 정규화(behavior regularization)이다. [1] Weighted Regression과 같이, 액션을 정책 훈련의 감독 정보로 직접 활용하여 행동 정규화를 실행한다. [2] 행동 정규화된 정책을 최적화한다. 생성적인 행동 모델을 구축한 다음, 정책 최적화 중에 학습된 정책과 행동 모델 간의 divergence를 제한하는 방식이다. [1]의 방식에서 unimodal (단일 모드) 액터는 종종 'mode covering' 문제에 빠지게 된다. diffusion model은 이러한 문제를 해결하는 데 도움이 된다.
Offline RL에서 확산 모델을 활용하는 주요 단점은 상당히 느린 샘플링 속도인데, 확산 정책이 과도하게 확률적이기 때문에 최종 최적의 액션을 찾기 위해 병렬로 여러 액션 후보를 생성한다. Score Regularized Policy Optimization(SRPO)는 평가 중에 반복적인 확산 샘플링 프로세스를 피하기 위해, critic과 diffusion behavior 모델에서 간단한 결정론적 추론 정책을 추출한다. 또한 행동 분포의 score function을 직접 활용하여 정책 최적화를 진행, 즉 정책 그래디언트를 규제함으로써 가짜 행동 생성을 줄이고자 한다.
SRPO를 연속 제어 작업에 적용하기 위해 해당 논문에선 SRPO를 implicit Q-learning 및 연속 시간 확산 행동 모델링과 결합하는 알고리즘을 개발하였다. D4RL 작업에서 SRPO는 25배 높은 액션 샘플링 속도를 보임과 동시에, 평가에 필요한 계산 비용이 1% 미만으로 감소하면서 성공적인 실험 결과를 도출하였다.
2. Background
(1) Offline reunforcement learning
전형적인 MDP(Markov Decision Process)는 ⟨S,A,P,r,γ⟩로 설명된다. 각각 상태 공간, 행동 공간, transition function(전이 함수), 보상 함수, 감가율이다. 강화학습의 목표는 파라미터화된 정책 πθ(a|s)를 훈련하여 기대 에피소드 반환을 최대화하는 것이다. Offline RL은 정적 데이터셋에만 의존하여 파라미터화된 정책을 훈련한다. Q-network를 사용하여 최적화 문제를 풀면, 최적 정책은 아래와 같다. Offline RL의 학습 목표는 π∗(a|s)를 효율적으로 모델링하고 샘플링하는 것이다.
(2) Optimal policy extraction
π∗를 explicitly 모델링하기 위한 매개변수화된 정책 πθ의 기존 방법은 주로 두 가지 범주로 나뉜다. [1] Weighted regression(가중 회귀) 방법은 정책 훈련에 action을 직접 감독 정보로 활용하여 복잡한 행동 정책을 명시적으로 모델링할 필요 없이, 행동 데이터셋의 일부로써 사용한다. 그러나 해당 방법은 목적 함수가 forward KL의 특성을 가지므로 계산 효율성이 높지 않고, 해결되지 못한 서브 문제들이 많이 존재한다. [2] Behavior-regulrized policy optimization(행동 정규화된 정책)은 Gaussian 모델과 같이 간단한 정책 모델에 대한 훈련에 더 적합한 접근 방식이며, 기본적으로 Reverse KL 목적 함수에 기초하여 모드 탐색 행동을 자연적으로 장려한다. 그러나 두 번째 KL 항을 근사하는 것은 어렵기 때문에 실제 구현에선 먼저 generative behavior 모델을 생성하여 μ(a|s)를 학습한 후, 학습된 행동 모델을 사용하여 주어진 상태에 대해 여러 행동을 생성한다.
(3) Diffusion models for score function estimation
Diffusion model은 데이터 분포를 노이즈 분포로 왜곡시키는 forward 과정을 진행하여 모델을 훈련한다. 이후, reverse 과정을 거쳐 순수한 노이즈에서 데이터 샘플을 생성한다.
확산 모델은 본질적으로 확산된 데이터 분포 qt의 score function ∇xt log qt(xt)를 추정하는 것이다. 그리고 reverse diffution process는 그 아래와 같이 식별될 수 있다.
일반적으로 상태는 조건으로 간주되고, 행동은 데이터 포인트로 간주된다. 조건부 확산 모델 ϵ(at|s,t)을 구성하여 µ(a|s)를 나타낼 수 있다.
3. Score regularized policy optimization
(1) Challenges for behavior regularization

이 training loss를 구현하는데 내재된 도전 과제는 µ(a|s)의 밀도 추정 문제일 것이다.
(2) Regularizing policy gradient through pretrained diffusion behavior
사전 훈련된 diffusion behavior모델을 활용하여 (9)의 행동 정규화를 실현한다. 구체적으로 다음과 같이 식을 미분할 수 있다.
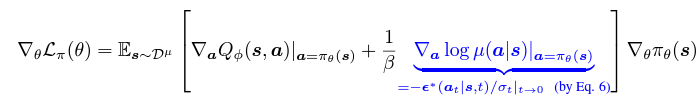
유일하게 알려지지 않은 항은 ∇a log µ(a|s) 이다. Song의 논문에서 확산 모델 ϵ(x|t)이 본질적으로 확산된 데이터 분포 µt(xt)의 점수 함수 ∇x log µt(xt)를 근사하는 것으로 나타냈고, 이는 사전 훈련된 확산 행동 모델인 ϵ(at | s,t)을 사용하여 ∇a log µ(a|s)를 근사할 수 있음을 시사한다. 이렇게 함으로써 원하는 결정론적인 액터의 최적화 과정을 정규화할 수 있으며, 확산 행동 모델에서 샘플링이나 역전파를 할 필요가 없다.
해당 논문의 SRPO 알고리즘은 손실 함수 수준이 아니라, 그래디언트 수준에서 정규화를 수행하는 특징을 갖는다. Evaluation에서 추론을 위해 확산 정책을 직접 훈련시키는 이전 연구들과 비교하였을 때 SRPO의 주요 이점은 계산 효율성이다. 행동 샘플링 체계를 완전히 우회하므로 계산 비용이 많이 들지 않고, 그럼에도 확산 모델의 강력한 생성 능력을 활용하여 다양한 데이터셋을 표현할 수 있다.
4. Pratical algorithm
이 섹션에서는 Offline RL에서 SRPO를 적용하는 실용적인 알고리즘을 유도한다. 알고리즘은 크게 3가지 부분으로 구성된다. implicit Q-learning, diffusion-based behavior modeling, score-regularized policy extracion이다.
(1) Pretraining the diffusion behavior model and Q-networks
Q-network의 경우 critic training을 actor training과 분리하기 위해 implicit Q-learning을 사용하기로 한다. 기존 데이터셋에서 액션을 샘플링하여 bootstrapping하는 기대회귀가 핵심 구성 요소다.
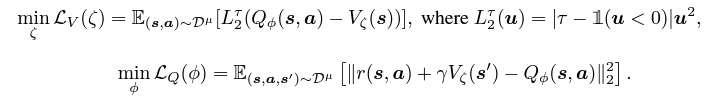
평균 손실 LV(ζ)에 대한 목적 함수는 이 0.5보다 클 때 하위 Q값을 가진 부적절한 행동에 가중치를 낮추어 명시적인 정책이 필요하지 않도록 한다. 행동 모델의 경우, 높은 신뢰도로 행동 분포를 나타내고 그의 score function을 추정하기 위해 이전 연구들과 동일하게 조건부 행동 복제 모델을 훈련한다.
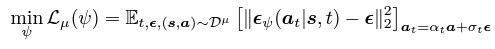
이고 . 의 모델 아키텍처에선 이산적인 입력이 아닌, 연속적인 입력을 사용한다. 행동 분포 ϵψ의 훈련이 완료되면 이를 통해 시간 t에서 의 확산된 분포인 의 점수 함수를 추정할 수 있다.
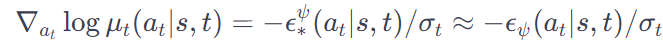

(2) Policy extraction from pretrained models
확산 행동 모델 을 에서 활용한다. 이때 행동 분포 가 확산되지 않은 상태다. 그러나 는 여러 시간 에서 확산된 행동 분포 를 나타내도록 훈련된다. 의 생성 능력을 활용하기 위해 원래의 훈련 목적인 을 새로운 대리 목적으로 대체한다.
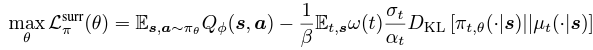


------> 살짝 집중력 감소 이슈로.... section 4부터 다시 제대로 공부해야 함
(15) 식을 보면, ϵψ (at|s,t)에서 ϵ(액션 노이즈)를 제외하였음을 알 수 있다. 이는 ∇θ Lsurr π (θ)의 기대값에 영향을 미치지 않지만, 추정의 분산을 줄일 수 있다.
5. Related work
Behavior Regularization in Offline reinforcement Learning : behavior regularization는 주로 암묵적, 명시적으로든 이루어질 수 있다. 명시적인 방법은 일반적으로 학습된 정책을 정규화하기 위해 행동 모델을 구성해야 한다. 예를 들어, TD3+BC는 행동을 가우시안으로 간주하고 정규화를 실현하기 위해 보조 L2 손실 용어를 도입한다. BCQ 및 BEAR은 행동 정책을 VAE 모델을 사용하여 나타낸다. BCQ는 훈련된 VAE 기반 행동 모델의 잠재 도메인 내에서 행동 공간을 제한하고, BEAR는 학습된 정책과 행동 정책 간의 차이를 추정하기 위해 샘플 기반 MMD 커널을 사용한다. Diffusion-QL은 TD3+BC와 유사하지만, auxiliary loss(보조 손실)을 확산 중심 목표로 교체한다. QGPO는 사전 훈련된 확산 행동을 에너지 가이드 확산 샘플링의 베이지안 사전으로 간주한다.
Diffusion Models in Offline Reinforcement Learning : 이질적인 행동 데이터셋을 모델링하고, 멀티 모달 정책을 표현하는 데 특히 적합하다는 것이 입증되었다. 그러나 확산 모델을 강화 학습에 통합할 때 상당한 샘플링 시간이 필요하다는 것은 중요한 고려사항이다. 이 도전에 대한 대응으로 병렬 샘플링 체계 도입, 특화된 확산 ODE 솔버 사용, 필요한 샘플링 단게를 최소화하기 위한 근사된 확산 샘플링 체계 도입 등의 다양한 전략이 제안되었다. 이러한 기술들은 개선을 제공하지만, 반복적인 샘플링의 필요성을 완전히 제거하지는 않는다.
Score Distillation Methods : 최근 text-to-3D generation이 발전하였다. 대표적인 방법은 DreamFusion으로, 3D NeRF 모델을 최적화하여 해당 모델의 투사된 2D 그래디언트가 대규모 사전 교육된 2D 확산 모델의 점수 방향을 따르도록 보장한다. 이와 유사하게 SRPO도 후속 네트워크의 교육을 안내하기 위해 확산 모델을 사용한다. 그러나 우리는 점수 증류가 아닌, 점수 정규화에 중점을 둔다. behavior score는 Q 그래디언트를 정규화하기 위해 추가로 통합된다.
6. Evaluation
(1) D4RL Performance
전반적으로 SRPO는 대부분의 작업에서 가우시안 또는 디랙 추론 정책을 사용하는 참조 기준을 일관되게 능가하며, 대부분의 작업에서 큰 간격으로 선도한다. 또한, Diffusion-QL 및 IDQL과 같은 최첨단 확산 기반 방법의 벤치마크를 거의 따라잡지만 훨씬 간단한 추론 정책을 갖추고 있다.

(2) Computational efficiency
높은 계산 효율성을 유지하면서, 행동 샘플링 속도도 다른 확산 기반 방법보다 25 ~ 1000배 빠르다.
(3) Ablation studies
실험적으로 Antmazetasks가 의 변화에 민감하게 반응하고, 반면에 Locomotiontasks는 그렇지 않은 것으로 관찰되었다. 종합적으로 모든 테스트된 작업에 대해 2가 적절한 선택이며 실험 전반에 걸쳐 기본 하이퍼파라미터로 선택된다. 또한 을 추정된 행동 그래디언트에서 뺀다면 일관된 성능 향상을 제공한다.
7. Conclusion
SRPO는 확산 모델의 능력을 활용하면서도 시간이 많이 소요되는 확산 샘플링 방식을 우회하는 혁신적인 오프라인 강화학습 알고리즘이다. 행동 정규화 정책 최적화 문제에 대응하며 확산 행동 모델링을 통해 효율적인 계산 방법을 제공한다. implicit Q-learning과 같은 기술과 결합하여 로봇 공학 등의 계산에 민감한 도메인에서의 응용을 더욱 견고하게 하였다.
[Index]
B. Theoretical Analysis
내용
C. Experimental details for D4RL benchmarks
내용


