Diffusion Model에 사용되는 아주 기본 공식들(여기를 클릭)
공부하기 전에 알아두면 좋은 DPM 기본 공식들 (여기를 클릭)
Abstract
diffusion model이 현재의 state-of-the-art generative model보다 우수한 [이미지 샘플 퀄리티]를 가진다.
일련의 절제(ablation)를 통해, 더 나은 아키텍처로 unconditional image synthesis을 수행한다.
conditional image synthesis을 위해, 분류 지침을 통해, 샘플 품질을 추가적으로 개선한다.
-> 분류 지침(clssifier guidance) : 분류기로부터 gradient를 사용하여, 다양성을 교환. 간단하고 효율적 방법
Diffusion Process
1) 원래의 이미지를 아주 약간(nearly infinitesimal) 노이즈화시킨다.
2) 이 노이즈화를 다회 반복하여, 원래 이미지와 거의 독립적인 noise로 만든다.
** neural network에서는 diffusion process의 역과정인 reverse process의 coefficient를 학습한다.
DDPM
noising process의 역과정을 수학적으로 나타내서, 역과정을 학습하는 방법
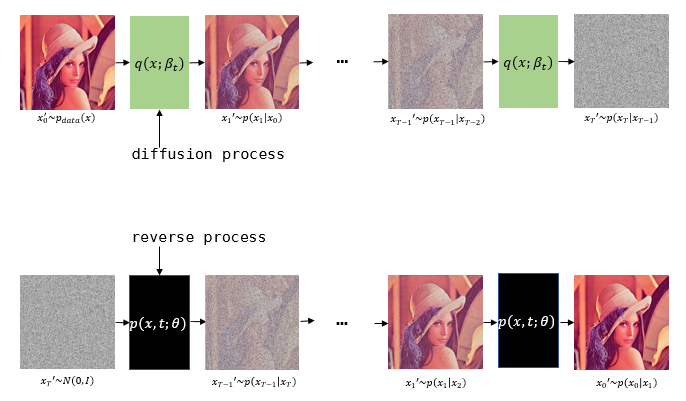

1) Forward process model, q

q : difusion process, 미세한 Gaussian noise를 추가하는 과정
-> q에는 trainable parameter가 없다.
(VAE에서 사용하는 reparameterization trick으로 학습할 수 있으나, hyperparameter를 사용했기 때문)
-> q는 점점 걷어내지는 과정 상에서 Markov chain이다.
(x[T-1]이 condition이라면, x[T-1] 이전의 값들에 독립적이다.)
-> x의 아래 첨자는 0에서 T까지의 process 과정을 표현한다.
-> x0은 noise가 없는 데이터, t가 커지면 점점 noise가 생기며, xT는 Gaussian noise가 된다.
2) Reverse process model(our purpose), p


p : reverse process, 미세한 Gaussian noise를 걷어내는 과정
-> 아래 첨자로
** 정리하자면
1) DDPM의 핵심 : neural network로 표현되는 p 모델이 q를 보고 noise를 걷어내는 과정을 학습하는 것
2) q는 noise를 아주 조금 추가하는 과정이다.
3) [noise를 추가하는 과정]을 보고 어떻게 [noise를 걷어내는 과정, denoising process]가 학습될까?
DDPM Loss
<VAE loss 수식 유도>
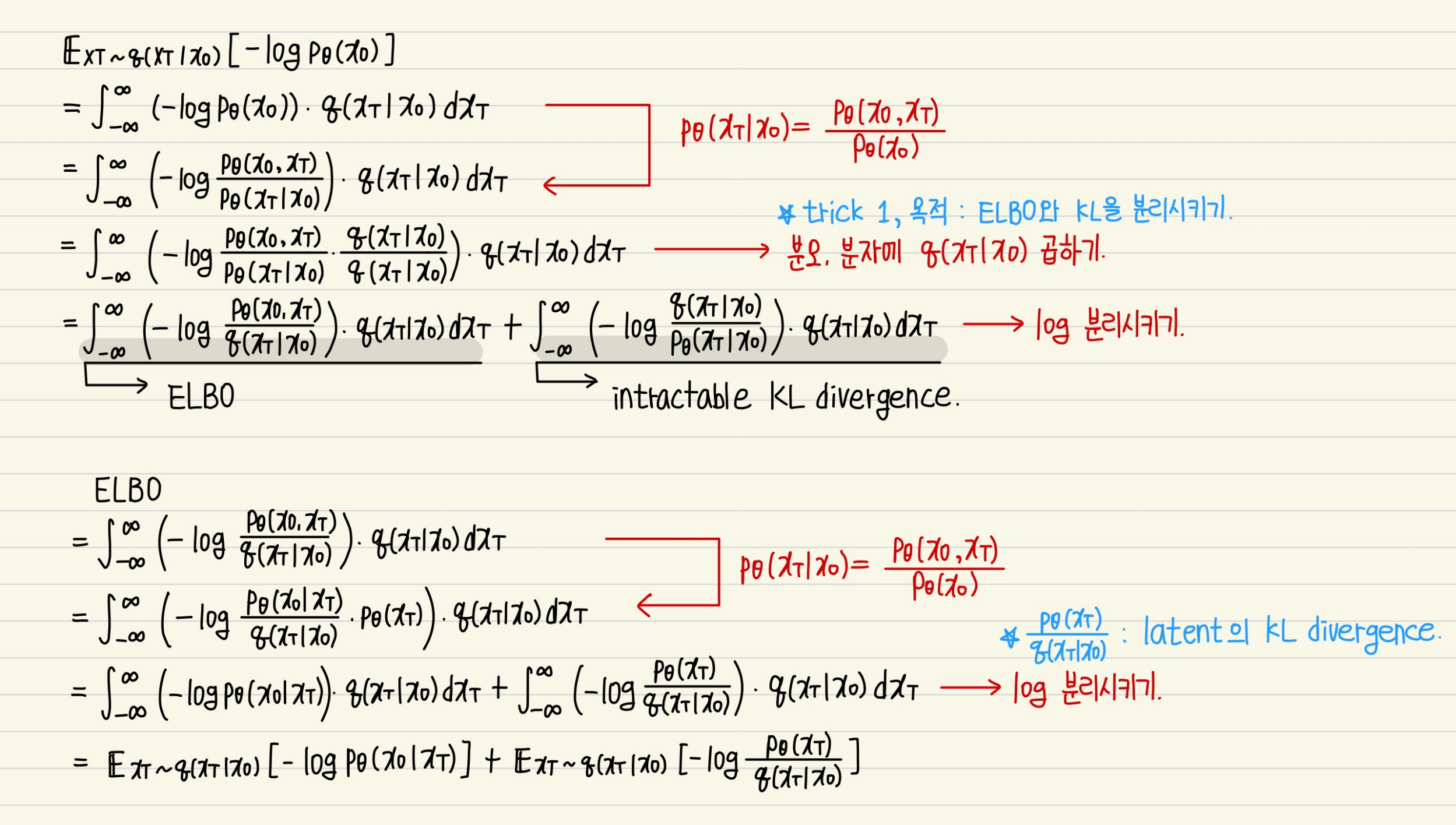
-> VAE loss는 latent를 z로 표현하기 때문에
유도 과정에서 보이는 XT를 z라고 생각한다면, 이전에 우리가 유도했던 VAE loss 공식과 일치하다.
<DDPM loss 수식 유도>

-> Q. [noise를 추가하는 과정]을 보고 어떻게 [noise를 걷어내는 과정, denoising process]가 학습될까?
에 대한 답을 얻을 수 있다.
-> A. 두 분포의 condition과 target variable이 서로 반대이다.

-> 5번에서, p와 q가 markov chain임을 이용하여 Markov chain의 성질을 사용했다.

-> * 부분 : Markov chain의 성질로 나타낼 수 잇는 부분. 사실상 loss term을 만들어낼 때의 핵심 구간
(이 과정을 통해서 [p와 q distribution]이 [같은 condition]으로부터 [같은 target distribution]을 나타냄)
-> 총 3개의 term이 나옴을 알 수 있다.
<Loss term 설명>

-> 1번 : VAE의 KL divergence와 비슷한 term
-> 2번 : reverse process와 diffusion process의 분포를 매칭시키는(=KL divergence를 낮추는) loss
(2번 식에서 [아래의 수식] 유도 과정은 나중에 하자 [여기를 참고] )
-> 3번 : reverse process의 마지막 과정, VAE의 reconstruction loss에 대응되는 term
<Loss 설명 및 training technique>
-> 이 loss term을 최적화시키는 방법, 더 좋은 generative model이 되도록 loss modification 시행


-> 를 에 대한 reparameterization 형태 ? 무슨 의미인지 모르겠다면 여기를 클릭
-> Q. neural net의 output이 Gaussian noise에 수렴하도록 한다?
A. neural net의 output도 reparameterization을 수행, diffusion porcess q 또한 reparameterization을 수행
두 reparameterization의 불확실성인 Gaussian을 matching시키는 것
-> loss의 계수(coefficient)는 t와 반비례한다.
따라서 coefficient를 제거하면, t가 큰 process의 loss가 더 커짐 -> larger t의 process에 집중
[이미지에 가까운, 덜 noisy한 것에서 noise를 제거하는 것]보다
[noise가 심한 이미지에서 noise를 제거하는 것]에 더 집중하는 모델이 성능이 좋을 것이다 !

결과 및 discussion
<결과>
좋은 샘플을 만들어냈고, FID 결과가 좋았다.
-> IS(inceptino score) :
생성된 image로부터 classification을 할 때, 얼마나 특정 class로 추정을 잘 하는지에 대한 score
(classification 성능이 좋으면서, 전체 class를 고르게 생성해낼수록 IS score가 높다.)
-> FID(Frechet Inception Distance) :
실제 데이터 분포를 참고하여 평균, 공분산을 비교. 낮을수록 좋다.
<Discussion>
FID는 좋지만, NLL 결과는 좋지 않았다.
-> NLL이 높다 = 이미지 픽셀당 평균 확률이 낮다, 불확실하다.

Langevin dynamics
여기를 클릭하면 랑주뱅 동역학이 무엇인지 알 수 있음!
출처 논문 :
https://paperswithcode.com/paper/diffusion-models-beat-gans-on-image-synthesis
Papers with Code - Diffusion Models Beat GANs on Image Synthesis
#3 best model for Image Generation on ImageNet 64x64 (FID metric)
paperswithcode.com
같이 참고하면 좋을 듯한 논문 :
DBpia
논문, 학술저널 검색 플랫폼 서비스
www.dbpia.co.kr



