해당 논문 링크 : https://arxiv.org/abs/2206.14176
DayDreamer: World Models for Physical Robot Learning
To solve tasks in complex environments, robots need to learn from experience. Deep reinforcement learning is a common approach to robot learning but requires a large amount of trial and error to learn, limiting its deployment in the physical world. As a co
arxiv.org
0. Abstract
(1) 개요
선배로부터 과제를 할당받았다. 2020년 이후의, 학습 알고리즘이 들어 있는 논문을 선택하여 리뷰하기. 막막함에 '로봇 학습 알고리즘'을 무진장 검색했다. 눈에 띄는 기사를 발견.

데이드리머(DayDreamer)는 UC버클리 연구진이 만든 강화학습(RL) 인공지능(AI) 알고리즘이다. 이 알고리즘은 로봇이 월드 모델을 사용해 픽킹, 탐색 또는 걷기와 같은 작업을 빠르게 학습할 수 있도록 도와준다. 월드 모델은 AI 시뮬레이터와 상호 작용할 필요가 없다. 또한 강화학습만 사용하는 것보다, 월드 모델을 같이 사용할 경우 AI 알고리즘이 더 빠르게 학습된다.
이 프로세스는 기존의 전통적인 로봇 학습 방법에 비해 장점을 가진다. 자체 강화학습보다 빠르고, 실제 세계의 복잡성과 역학을 처리할 수 있는 장비가 잘 갖추어져 있다.
월드 모델에 대해서도 살펴보자. 월드 모델은 시뮬레이션된 환경보다 개발 시간 및 비용이 적게 든다. 이 시스템은 인코더 신경망을 사용해 지도 센서 데이터를 더 작은 차원 표현, 동적 네트워크로 변환한다. 네트워크는 운동 동작들이 이 작은 표현들을 바꾸는 방법을 예측하고, 보상 신경망은 과제 달성 여부에 따라 어떤 운동 동작이 가장 좋은지를 결정한다. 강화학습 액터(Actor) 비판 알고리즘은 그 결과로 나오는 월드 모델을 사용해 제어 동작을 학습한다. 여기를 클릭하여 참고하시오.
실제로 해당 모델은 중국 유니트리 로보틱스의 4족 보행 로봇 A1을 한 시간 만에 훈련시켰고, 유니버설 로봇의 협동로봇 UR5의 매니퓰레이터 그리고 U팩토리의 xArm 6을 약 10시간 만에 훈련시켰다. 또한 스피로의 올리 이동로봇이 2시간 만에 내비게이션 작업을 완료할 수 있도록 가르쳤다.
(2) Abstract
복잡한 환경에서 작업을 해결하려면, 로봇은 경험을 통해 학습해야 한다. 심층 강화 학습은 로봇 학습에 대한 일반적 접근 방식이지만, 학습에 많은 시행착오가 필요하므로 실제 환경에 적용하는 데 한계가 있다. 그 결과, 로봇 학습의 많은 발전은 시뮬레이터에 의존하고 있다. 반면, 시뮬레이터 내부에서의 학습은 실제 세계의 복잡성을 포착하지 못하고, 부정확성이 발생하기 쉬우며, 결과 action이 현실 세계의 변화에 적응하지 못한다.
드리머 알고리즘은 월드 모델 내에서 계획을 세워, 소량의 상호작용을 학습하는데 큰 가능성을 보여주며, 뛰어난 성능을 보여준다. 잠재적 행동의 결과를 예측하기 위해 월드 모델을 학습하면, 상상 속에서 계획을 세울 수 있어 실제 환경에서 필요한 시행착오를 줄일 수 있다. 하지만 드리머가 실제 로봇의 학습 속도를 높일 수 있는지는 아직 알려지지 않았다.
이 논문에서는 드리머를 4대의 로봇에 적용하여 시뮬레이터 없이 온라인 그리고 실제 환경에서 직접 학습한다. (1) 드리머는 네 발로 걷는 로봇을 처음부터 굴린 후 일어서서 걷도록 훈련한다. 1시간의 훈련 후 로봇을 밀면, 드리머가 10분 이내에 적응하여 흔들림을 견디거나 빠르게 넘어졌다 다시 일어서는 결과를 보였다. (2) 2개의 로봇팔로 드리머는 카메라 이미지와 희박한 보상을 통해 여러 개의 물체를 골라 배치하는 방법을 학습했다. (3) 바퀴 달린 로봇에서 드리머는 카메라 이미지만으로 목표 위치로 이동하는 방법을 학습한다. 로봇의 방향에 대한 모호함을 자동으로 해결한다.

1. Introduction
로봇에게 현실 세계의 복잡한 작업을 해결하도록 가르치는 것은 로봇 연구의 기초적인 문제다. RL은 시행착오를 통해, 로봇이 시간이 지남에 따라 행동을 개선하도록 하는 대중적인 접근 방식을 취한다. 그러나 현재의 알고리즘은 성공적인 행동을 학습하기 위해 환경과의 너무 많은 상호작용이 필요하기 때문에, 비현실적이다.
최근, 월드 모델은 시뮬레이션된 도메인 및 비디오 게임에서 데이터 효율적인 학습에 큰 가능성을 보여주었다. 과거의 경험으로부터 월드 모델을 학습하면, 로봇이 잠재적인 행동의 미래 결과를 상상할 수 있으므로, 성공적인 행동을 학습하는 데 필요한 실제 환경에서의 시행착오를 줄일 수 있다. 월드 모델은 환경에 대한 지식을 요약한다. 이와 같이 한 번 학습된 지식은 다양한 작업에 재사용할 수도 있다. 또한 월드 모델은 여러 센서 모달리티를 융합하고, 이를 잠재 상태로 통합하여 수동 상태 추정이 필요하지 않다. 마지막으로, 이 모델은 사용 가능한 오프라인 데이터로부터 잘 일반화되어, 실제 세계의 학습을 더욱 가속화할 수 있다.
월드 모델의 장점에도 불구하고, 실제 세계에 대한 정확한 월드 모델을 학습하는 것은 큰 도전 과제다. 이 논문에서는 최근 발전한 드리머 월드 모델(Dreamer world model)을 활용하여 가장 간단하고 기본적인 문제 설정인 온라인 강화학습을 통해 다양한 로봇을 훈련한다. 시뮬레이터나 데모 없이 실제 세계에서 학습하는 것이다.
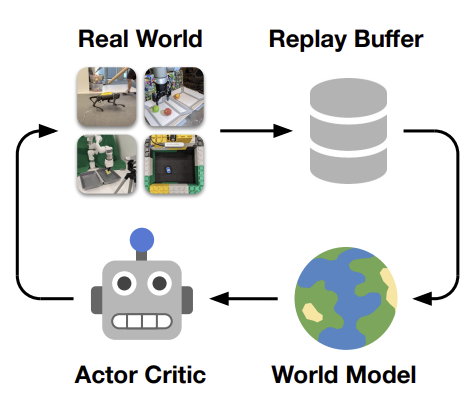
윗 그림에서, Dreamer는 시뮬레이터 없이 로봇 하드웨어에서 온라인 학습을 위한 간단한 파이프라인을 따른다. 현재 학습된 정책은 로봇에 대한 경험을 수집한다. 수집된 경험은 리플레이 버퍼에 추가된다. 월드 모델은 지도 학습을 통해 재생된 정책 외 시퀀스에 대해 학습된다. actor critic 알고리즘은 월드 모델의 잠재 공간에서 상상된 롤아웃을 통해 신경망 정책을 최적화한다. 우리는 데이터 수집과 신경망 학습을 병렬화하여, 로봇이 이동하는 동안에도 학습 단계를 계속하고 지연 시간이 짧은 행동 계산을 가능하게 한다.
Dreamer는 과거 경험의 replay buffer에서 월드 모델을 학습하고, 월드 모델의 잠재 공간에 상상된 롤아웃에서 동작을 학습하며, 환경과 지속적으로 상호작용하여 동작은 탐색 및 개선한다. 우리의 목표는 실제 세계에서 직접 로봇 학습의 한계를 뛰어넘고, 로봇 학습을 위한 월드 모델의 이점을 개발하는 강력한 플랫폼을 제공하는 것이다.

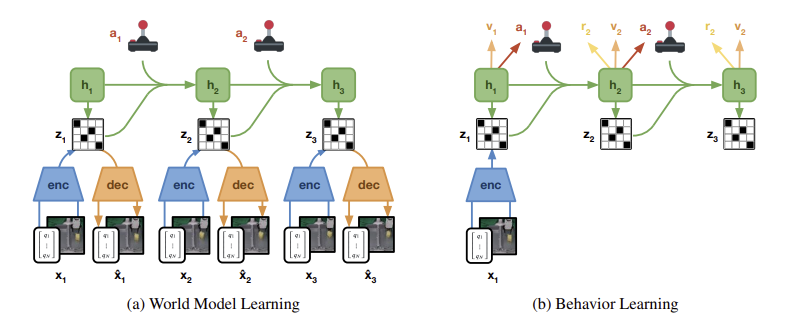
Dreamer는 2가지 신경망 구성 요소로 이루어져 있다.
왼쪽의 월드 모델은 리플레이 버퍼에서 가져온 시퀀스에 대해 훈련되는 deep Kalman filter의 구조를 따른다. Encoder는 모든 감각적인 모달리티를 개별 코드로 융합한다. Decoder는 코드의 입력을 재구성하여 풍부한 학습 신호를 제공하고, 사람이 모델 예측을 검사할 수 있도록 한다. recurrent state-spce model(RSSM)이 학습되어 입력을 관찰하지 않고도, 주어진 미래 코드를 예측하도록 훈련된다.
오른쪽의 월드 모델은 sensory input을 구성할 필요 없이, 밀집한 잠재 공간에서 상상된 롤아웃으로부터 대규모 병렬 정책 최적화를 가능하게 한다. Dreamer는 상상된 롤아웃 그리고 획득한 보상 함수에서 정책 네트워크와 가치 네트워크를 훈련한다.
2. Approach
우리는 시뮬레이터 없이도 실제 로봇에 대한 온라인 학습을 위해 Dreamer 알고리즘을 활용한다. Dreamer는 과거 경험의 replay buffer에서 월드 모델을 학습하고, actor critic algorithm을 사용하여 학습한 모델이 예측한 궤적에서 행동을 학습한 후, 그 행동을 환경에 배포하여 replay buffer를 지속적으로 증가시킨다. 우리는 데이터 수집에서 학습 업데이트를 결합하여, 환경을 기다리지 않고도 빠른 학습을 가능하게 한다. 구현에서 learner thread는 world model과 actor critic behavior를 지속적으로 학습하고, 다른 스레드는 환경 상호 작용을 위해 병렬로 동작을 계산한다.
(1) World Model Learning
월드 모델은 environment dynamics를 예측하기 위해 학습하는 심층 신경망이다. sensory inputs이 큰 이미지가 될 수 있기 때문에, 우리는 future inputs이 아닌 future representations를 예측한다. 이는 누적 오류를 줄이고, 대규모 배치 크기로 대규모 병렬 학습을 가능하게 한다. 그러므로 월드 모델은 로봇이 자율적으로 학습하는 환경의 fast simulator가 될 수 있으며, 백지 상태에서 시작하여 그 모델이 real world를 탐험하는 만큼 지속적으로 모델을 개선할 수 있다. RSSM(반복 상태 공간 모델) 구성 요소로 구성된다.
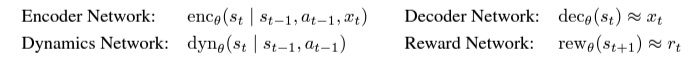
물리적 로봇은 종종 관절 판독, 힘 센서, 심도 카메라 이미지와 같은 고차원 입력 등 다양한 방식의 다중 센서를 갖춘다. Encoder Network는 모든 sensory inputs xt를 확률적 표현 zt로 융합한다. Dynamics Network는 반복 상태 ht를 사용하여 확률적 표현의 결과를 에측하도록 학습한다. Decoder Network는 학습 표현에 대한 신호를 제공하기 위해 sensory inputs를 재구성하고, 모델 예측을 인간이 검사할 수 있도록 한다. 그러나 latent rollout에서 동작을 학습하는 동안에는 그것이 필요하지 않다. 실험에서는 로봇이 (네트워크가 예측할 수 없는) 실제 세계와 상호작용하여, task rewards를 발견할 수 있다. 즉 디코딩된 sensory inputs의 기능으로 수동으로 지정된 보상을 사용하는 것이 가능하다. 우리는 stochastic backpropagation을 통해 월드 모델의 모든 구성 요소를 공동으로 최적화한다.
(2) Actor Critic Learning
월드 모델은 동역학에 대한 지식이 없는 작업을 나타내는 반면, Actor Critic 알고리즘은 작업 경로에 특정한 동작을 학습한다. 관찰을 디코딩하지 않고도 월드 모델의 공간에서 예측되는 롤아웃의 동작을 학습한다. 이를 통해 일반적인 배치 크기인 16K 단일 GPU로 대규모 병렬 행동 학습이 가능하다. Actor Critic 알고리즘은 2개의 신경망으로 구성된다.
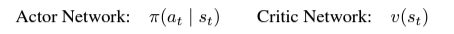
Actor Network는 예측된 task rewards를 최대화하기 위해 각각의 latent model state st마다, 성공적인 행동 at에 대한 분포를 학습한다. Critic Network는 시간차 학습을 통해, future task rewards의 총합을 예측하기 위해 학습한다. 이는 알고리즘이 (long-term strategies를 학습하기 위해) H=16 단계를 넘어서는 보상을 고려할 수 있게 해주기 때문에 중요하다. model state의 궤적이 주어지면, Critic은 궤적의 방향을 바꾸도록 훈련된다. 간단하게 next state에서의 Critic의 에측을 더한 중간값 N의 합계로 계산하자. N에 대한 임의의 값을 선택하지 않기 위해, 대신 전체 N ∈ [1, H-1]의 평균인 λ-returns를 계산하고, 아래와 같이 계산한다.
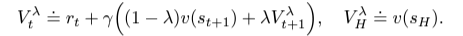
Critic Network는 λ-returns을 계산하기 위해 훈련되는 반면, Actor Network는 이를 최대화하기 위해 훈련된다. 액터 최적화를 위한 정책 기울기(policy gradient)를 계산하기 위해 다양한 기울기 추정기를 사용할 수 있다. Reinforce, reparameterization trick과 같이 서로 다른 dynamic 네트워크를 통해 직접 return gradients를 역전파하는 방법들이 있다. 우리는 연속 제어 작업을 위해 reparameterization 기울기를 선택하고, 이산 제어 작업을 위해 Reinforce 기울기를 선택한다. 수익을 극대화하는 것 외에도, 결정론적 정책에 대한 붕괴를 방지하고 훈련 내내 일정량의 탐색을 유지하도록 인센티브를 부여한다.
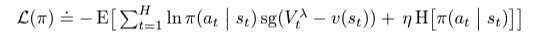
Adam optimizer를 사용하여 actor와 critic을 최적화한다. λ-returns를 계산하기 위해, 우리는 Critic network의 copt를 천천히 업데이트한다. actor와 critic의 기울기는 월드 모델에 영향을 미치지 않는다.
3. Experiments
생략하겠습니다.
4. Related work
로봇 학습에 대한 기존 연구는 (실제 세계에 배포하기 전에) 대량의 시뮬레이션된 경험을 활용하거나, 경험 데이터를 수집하기 위해 다양한 종류의 로봇을 활용하거나, 인간의 expert demonstrations과 같은 외부 정보에 의존하거나, 에제를 통한 효율적 학습을 위한 사전 작업을 실시하곤 했다. 그러나 시뮬레이션 작업을 설계하고 전문가 데모를 수집하는 데는 시간이 많이 걸린다. 또한 이러한 접근 방식 중 다수는 오프라인 경험, demonstrations 또는 simulator inaccurancies가 필요하다.
이와 대조적으로, 우리의 실험은 물리적 세계에서 보상을 통한 end-to-end 학습이 월드 모델을 통해 더 다양한 작업에서 실현 가능하다는 것을 보여준다. 물리적 세게에서 처음부터 end-to-end 학습을 시연하는 작업은 비교적 드물다. Visual Foresight는 온라인 플래닝으로 예측 모델을 학습하지만, 가로가 짧은 작업에는 제한이 있고 계산 비용이 많이 든다. Yang et al은 모델 기반 접근 방식을 통해 발 위치를 예측하고, 도메인별 제어를 활용하여 4중 위치 이동을 학습한다. SOLAR는 이미지에서 동역학 모드를 학습하고, 로봇팔로 reaching과 pushing을 시연한다. Nagabandietal은 상태 관찰로부터 학습된 동역학 모델을 통해 플래닝함으로써 외적 조작 정책(dexterous manipulation policies)를 학습한다.
우리의 실험은 작은 잠재 공간에서 대규모 배치 크기로 효율적인 정책 최적화를 가능하게 하는 잠재 동역할을 학습한다. 또한 우리는 학습 알고리즘과 하이퍼파라미터 설정을 통해 광범위한 도전, sensory modalities를 포괄하는 4가지 도전적인 로봇 과제에서 성공적인 학습을 보여준다.
5. Discussion
우리는 Dreamer를 물리 로봇 학습에 적용하여, modern world models이 시뮬레이터 없이도 실제 세계에서 다양한 작업에 대해 효율적인 로봇 학습을 할 수 있다는 것을 발견했다. 또한 이 접근 방식은 하이퍼파라미터를 변경하지 않고도 로봇의 위치 이동, 조작, 내비게이션 작업을 해결할 수 있다는 점에서 일반적으로 적용 가능하다. Dreamer는 4족 보행 로봇이 처음부터 1시간 만에 앉았다 일어서고 걷는 데 성공했다. (이전에는 광범위한 훈련이 필요했던 작업이다.)
한계 : Dreamer는 유망한 결과를 보여주지만, hardware로 오랜 시간 동안 학습하면 로봇은 사람의 개입이나 수리가 필요하다. 또한 Dreamer의 한계, 그리고 우리의 baseline을 탐구하기 위해 오랜 시간 훈련을 비롯한 더 많은 작업이 필요하다. 마지막으로, 우리는 더욱 더 도전적인 과제에 도전하고 있다.
* 약간의 요약..? (feat. chat gpt)
월드 모델은 강화 학습 에이전트가 환경과 상호작용하며 학습하는 동안, 실제 환경의 동역학을 모방하는 모델을 의미한다. 가제보와 같은 시뮬레이션 환경에서 월드 모델을 실행시키는 것은 가능하다. 또한 월드 모델은 로봇팔과 같은 로봇 시스템에 대한 제어와 경로 계획을 개선하거나 테스트하는 데 활용될 수 있다. Franka Emika에도 적용될 수 있을꺼라 본다.
월드 모델은 Critic-Actor 알고리즘과 같이 사용하면 (1) 경험 데이터 증강, 월드 모델을 활용하여 에이전트가 아직 시도해보지 않은 행동을 시뮬레이션하고 이에 대한 예측된 결과를 학습에 활용 가능, (2) 정책 평가 및 개선, Critic-Actor 구조에서 Critic은 가치 함수 추정, Actor는 정책 개선 역할인데 원드 모델이 Critic에 사용될 수 있는 보조적인 정보를 제공하며 보다 정확한 가치 함수 추정이 가능, (3) 평가 및 탐사 : 월드 모델을 사용하여 다양한 정책을 시뮬레이션 및 평가함으로써 탐사적인 정책을 발견하거나 평가하는데 도움줄 수 있음 과 같은 3가지 장점을 가진다.



