해당 논문 링크 : https://arxiv.org/abs/1803.10122
World Models
We explore building generative neural network models of popular reinforcement learning environments. Our world model can be trained quickly in an unsupervised manner to learn a compressed spatial and temporal representation of the environment. By using fea
arxiv.org
0. Abstract
널리 사용되는 강화 학습 환경의 생성 신경망 모델을 구축하는 방법을 살펴보자. 월드 모델은 비지도 방식으로 빠르게 훈련하여, 환경의 압축된 공간 및 시각적 표현을 학습할 수 있다. 월드 모델에서 추출한 특징을 에이전트의 입력으로 사용하면, 필요한 작업을 해결할 수 있는 매우 간결하고 간단한 정책이 학습 가능하다. 심지어 월드 모델에서 생성한 가상 환경 내에서 에이전트를 학습시키고, 이 정책을 다시 실제 환경으로 옮길 수도 있다.
1. Introduction
인간은 경험을 통해 학습을 한다. 또한 일상 생활에선 방대한 양의 정보가 존재하기에, 인간은 이러한 정보의 공간적, 시간적 측면을 추상적으로 표현하는 방법을 학습한다. 그 예시 중 하나로, 인간은 머릿속에서 모델을 만들어 시뮬레이션을 한다. 야구를 예로 들어보자. 우리가 시속 100km의 직구를 칠 수 있는 이유는 공이 언제 어디로 날아갈 지 본능적으로 예측할 수 있기 때문이다. 우리는 의식적으로 행동 방침을 계획할 필요 없이, 본능적 그리고 반사적으로 예측에 따라 행동한다.
여러 RL problem에서 인공 에이전트는 '과거와 현재 상태를 잘 표현하고, 미래를 잘 예측하는 모델'을 보유해야 유리하다. 가급적이면 범용 컴퓨터에서 구현된 강력한 예측 모델인 순환 신경망(RNN) 말이다. 대규모 RNN은 풍부한 공간적, 시간적 표현을 학습할 수 있는 표현력이 뛰어난 모델이다. 그러나 RL 알고리즘은 종종 병목 현상이 발생하고, 이는 기존 RL 알고리즘이 수백만 개 가중치를 학습하기 어려운 환경을 조성한다. 그래서 RL 방법은 매개변수가 적은, 작은 신경망만 사용하는 경우가 많다.
대규모 RNN 기반 에이전트를 이상적으로, 효율적으로 훈련하는 방법은 없을까? backprogaration(역전파) 알고리즘은 효율적인 훈련에 사용될 수 있다. 이 작업에서는 먼저 대규모 신경망을 훈련하여 에이전트의 world model을 비지도 방식으로 학습한다. 다음 월드 모델을 활용하여 소규모 컨트롤러 모델의 작업 수행 방법을 훈련한다.
-> 작은 컨트롤러를 사용하면, 훈련 알고리즘이 더 큰 월드 모델을 통해 (1) 용량과 표현력을 낭비하지 않으면서도, (2) 작은 검색 공간에서 신용 할당 문제에 집중할 수 있다.
또한 기존의 대부분 RL 접근 방식은 RL 환경의 모델을 학습하지만, 여전히 실제 환경에서 훈련한다. 해당 논문에서는 실제 RL 환경을 생성된 환경으로 완전히 대체하여, 에이전트의 컨트롤러를 자체 내부 세계 모델에 의해 생성된 환경 내에서만 학습시키고, 이 정책을 다시 실제 환경으로 옮기는 방법을 살펴본다. 또한 에이전트가 '생성된 환경의 불완전성을 악용하는 문제'를 극복하기 위해 내부 세계 모델의 온도 파라미터를 조정하여, 생성된 환경의 불확실성을 제어한다.
2. Agent Model
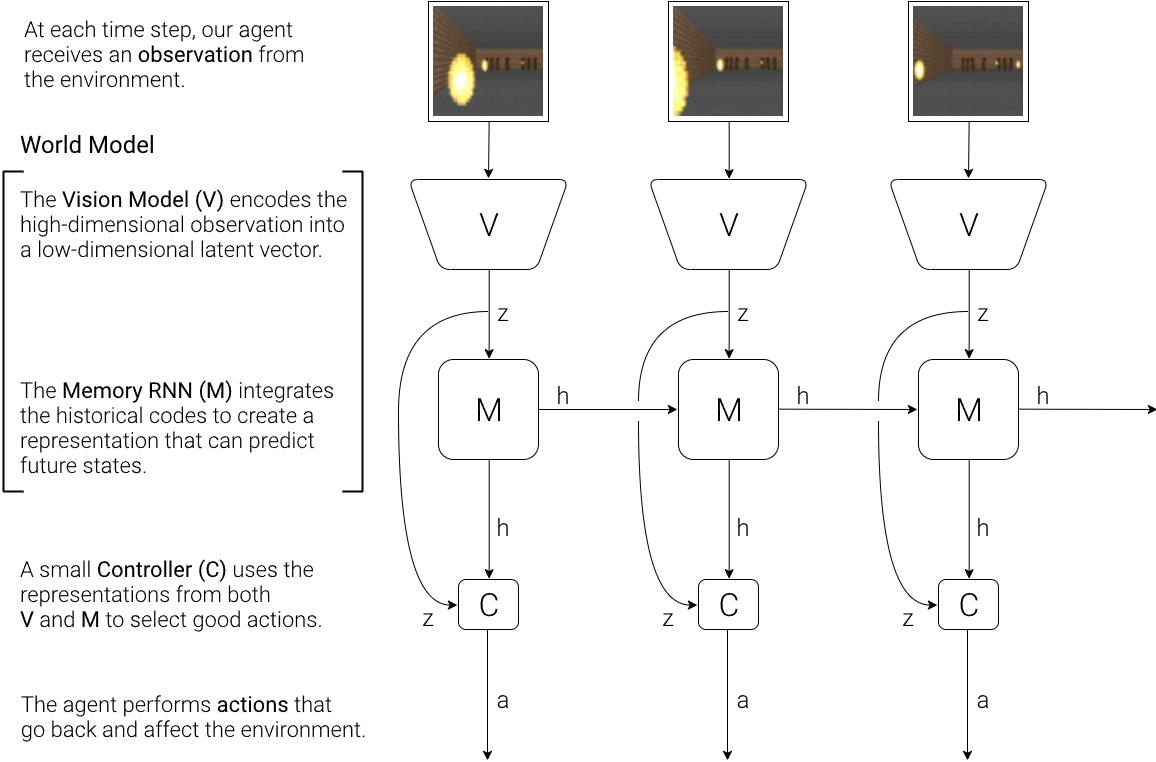
월드 모델은 위의 그림과 같이 비전(Vision), 메모리(Memory), 컨트롤러(Controller)의 세 부분으로 이루어져 있다. 비전은 화면 인식, 메모리는 기억 및 예측, 컨트롤러는 행동 및 학습을 수행한다.
(1) Vision - VAE

V model의 역할은 입력 프레임에서 관찰된 각 입력을 추상적이고, 압축적으로 표현하는 것이다. 저차원 잠재 벡터로 압축된 이 표현은 원본 이미지를 재구성하는 데 사용된다.
(2) Memory - RNN

RNN은 시간적인 순서가 중요한 신경망이다. 위의 그림처럼, VAE에서 현재 화면을 압축한 z값과 행동 a를 입력으로 받는다. 그리고 새로운 z값을 출력한다. 벡터인 z값을 VAE에서 디코드하면, 바로 다음 단계에 나타날 화면을 볼 수 있다. 간단히 말해서 과거와 현재의 경험을 통해 앞으로 일어날 일을 예상할 수 있다. M 모델은 미래 예측 모델 역할을 한다.
많은 복잡한 환경들은 본질적으로 확률적이다. 따라서 결정론적 예측(deterministic prediction, z) 대신 확률 밀도 함수 p(z)를 출력하도록 RNN을 훈련시킨다. 우선 p(z)를 가우스 분포의 혼합으로 근사화한다. 현재 및 과거 정보가 주어졌을 때 다음 단계 잠재 벡터 z의 확률 분포를 출력하도록 RNN을 훈련시킨다.
구체적으로, RNN은 P(zt+1 |at, zt, ht)를 모델링할 것이다. 여기서 at 는 t 시점에 수행된 작업이고, hat 는 t 시점에 RNN의 숨겨진 상태다. 또한 샘플링 중에 온도 매개변수 τ를 조정하여 모델 불확실성을 제어할 수 있으며, τ를 조정하면 나중에 컨트롤러를 훈련하는 데 유용하다. 이러한 접근 방식은 혼합 밀도 네트워크와 RNN을 결합한 것, MDN-RNN으로 잘 알려져 있다. 시퀀스 생성 문제에 성공적으로 사용되었다.
(3) Controller - Linear & Evolution Strategies

컨트롤러는 예산 누적 보상을 최대화하는 행동(action)을 결정하는 부분으로, 간단한 선형 모델이다.
각 시간 단계에서 zt와 ht를 행동 at에 직접 매핑한다. 이 선형 모델에서 Wc와 bc는 연결된 입력 벡터 [zt ht ]를 출력 행동 벡터 at에 매핑한다. Wc는 가중치 행렬, bc는 바이어스 벡터이다. zt는 현재 화면의 압축된 정보다. ht는 RNN의 히든 상태로 미래의 정보를 나타낸다. 또한 파라미터 Wc는 CMA-ES라는 진화 전략을 사용해서 결정한다.
-> CMA-ES란? 수치 최적화 알고리즘 중 하나,함수의 최적점을 찾는 데 사용된다. 특히 연속적인 비선형 문제에서 효과적으로 작동한다. 크게 3가지 특징을 가진다. (1) 직접적인 전략 : 파라미터 공간을 직접 탐색하고 기존 해를 업데이트하는 방식을 취한다. (2) 공분산 행렬 적응 : 해의 분포를 모델링하기 위해 공분산 행렬을 사용한다. (3) 적응적인 스텝 사이즈 : 해의 탐색 거리를 적응적으로 조정하여 다양한 지형에 적합하도록 한다. CMA-ES는 다양한 문제에 사용될 수 있으며, 전역 최적점을 찾기 위해 지역 최적점에 빠질 위험이 적다.
(4) Putting V, M and C Together
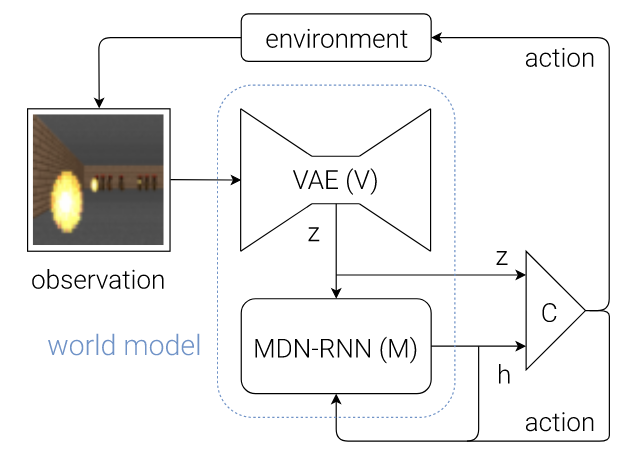
월드 모델에서 비전, 메모리, 컨트롤러는 위와 같은 흐름으로 동작한다. 먼저 각 시간 단계 t에서 V 모델에 의해 처리되어 zt를 생성한다. 이 잠재벡터 zt는 각 시간 단계마다 M 모델의 hidden state ht와 연결되어 있고, C 모델의 입력이다. 그런 다음 C 모델은 모터 제어를 위한 동작 벡터 at를 출력하고, 환경에 영향을 미친다. M 모델은 현재 zt와 동작 at를 입력으로 받아 자신의 hidden state를 업데이트하여, t+1 시점에 사용할 ht+1를 생성한다.
V 모델, M 모델은 최신 GPU 가속기를 사용하는 backpropagation 알고리즘으로 효율적인 학습이 가능하다. 그래서 대부분의 모델 복잡도와 모델 파라미터는 V와 M에 있으며, 선형 모델인 C의 파라미터 수는 이에 비해 최소화되어 있다. C의 파라미터를 최적화하기 위해 최대 수천 개의 파라미터로 구성된 솔루션 공간에서 잘 작동하는 CMA-ES를 최적화 알고리즘으로 선택했다.
def rollout(controller):
''' env, rnn, vae are '''
''' global variables '''
obs = env.reset()
h = rnn.initial_state()
done = False
cumulative_reward = 0
while not done:
z = vae.encode(obs)
a = controller.action([z, h])
obs, reward, done = env.step(a)
cumulative_reward += reward
h = rnn.forward([a, z, h])
return cumulative_reward
이를 OpenAI Gym 환경에서, pseudocode로 구현하면 위와 같다.
3. Car Racing Experiment
생략하겠습니다.
4. Vizdoom Experiment
생략하겠습니다.
5. Iterative Training Procedure
실험에선 작업이 매우 간단하기 때문에, 수집된 데이터 세트와 정책을 사용하여 합리적인 세계 모델을 훈련할 수 있다. 그러나 환경이 더 복잡해지면 어떻게 될까? 어려운 환경에서는 에이전트가 세계를 전략적으로 탐색하는 방법을 배운 후에야 세계의 일부만 사용할 수 있다. 더 복잡한 작업의 경우, 반복적 훈련 절차가 필요하다.

어려운 Task를 형성하려면, 2단계의 C 모델이 환경의 일부를 적극적으로 탐색해야 한다. 현재의 접근 방식에서, M 모델은 다음 프레임에 대한 확률 분포를 모델링하는 MDN-RNN이기 때문에, 에이전트가 익숙하지 않은 부분을 만났다는 것을 의미한다. 따라서 우리는 M 모델의 훈련된 손실 함수를 조정하고 재사용할 수 있다. 실제 환경에서 M 모델의 손실 함수를 뒤집음으로써 에이전트는 익숙치 않은 부분을 탐색하도록 장려한다. 그렇게 수집된 새로운 데이터는 월드 모델을 더욱 향상시켜줄 것이다.
반복적인 훈련 과정에서는 M 모델이 다음 관찰과 완료를 예측할 뿐만 아니라 다음 단계의 행동과 보상도 예측해야 하며, 이를 위해 어려운 과제를 수행해야 할 수도 있다. 예를 들어, 에이전트가 주변 환경을 돌아다니기 위해 복잡한 운동 기술을 학습하는 경우, 월드 모델은 이미 학습한 걷기를 모방하도록 학습할 것이다. 걷기와 같은 어려운 운동 기술이 '많은 용량을 가진 더 큰 세계 모델'에 흡수된 후, 더 작은 C 모델은 이미 세계 모델에 흡수된 기술에 의존하며 이미 학습한 운동 기술을 사용한다. 그렇게 스스로 이동하는 더 높은 수준의 기술을 배울 수 있다.

6. Related Work
다양한 관련 연구가 펼쳐져 왔다. 그 중 일부만 요약하자면...
(1) Gaussian process는 소량의 저차원 데이터 세트에서는 잘 작동하지만, 계산 복잡성으로 인해 대규모 고차원 관측 기록을 모델링하기엔 어렵다. 최근 다른 연구에서는 GP 대신 Bayesian neural networks를 사용하여 동역학 모델을 학습하기도 한다. 이러한 방법은 관측이 상대적으로 까다로운 저차원 제어 작업에서도 유망한 결과를 보인다.
(2) robotic control application에서, 카메라 기반 비디오 입력만을 관찰하여 시스템의 역학을 학습하는 Task는 어렵지만 중요한 문제다. 능동형 비전을 위한 RL 초기 연구에서는 신경망을 사용하여 먼저 비디오 프레임의 압축된 표현을 학습하는 방법을 모색했다. 최근의 연구에서는 autoencoder의 bottleneck hidden layer를 저차원 특징 벡터로 사용하여, 픽셀 입력에서 pendulum을 제어하는 제어기를 학습할 수 있다. 이처럼 압축된 잠재 공간에서 동역학 모델을 학습하면 RL 알고리즘이 훨씬 더 데이터 효율적이 될 수 있다.
(3) 비디오 게임 환경은 모델 기반 RL 연구에서도 인기가 있다. CNN을 사용하여 비디오 게임을 순방향 시뮬레이션 모델을 학습했었다. 또한, 다음 비디오 프레임을 예측하기 위해 FNN을 사용하기도 했다. 그러나 장기적인 시간을 포착할 수 있는 모델, RNN을 사용할 수도 있다. 후속 연구에서는 RNN 기반 모델을 사용하여 미래에 대한 많은 프레임을 생성하고, 미래 추론을 위한 내부 모델로도 사용했다.
7. Discussion
(1) 우리는 에이전트가 시뮬레이션된 잠재 공간 세계 내에서만 작업을 수행하도록 훈련할 수 있는 가능성을 입증했다. 이 접근 방식은 많은, 실질적인 이점을 제공한다. 실제 환경에서 에이전트를 훈련하는 데 시간을 낭비할 필요 없이 시뮬레이션 환경에서 원하는 만큼 에이전트를 훈련할 수 있기 때문이다.
(2) 또한 딥러닝 프레임워크를 활용하여 분산 환경에서 GPU를 사용하여 세계 모델 시뮬레이션을 가속화할 수 있다. 월드 모델을 완전 미분 가능한 반복 계산 그래프로 구현하면, backpropagation 알고리즘을 사용하여 에이전트(in the dream)를 직접 훈련하여 목적 함수를 최대화하도록 정책을 미세 조정할 수 있다는 이점을 가진다.
(3) V 모델을 VAE로 구현하고, 독립적으로 사용하면 작업과 관련이 없는 관찰의 일부를 인코딩할 수 있기 때문에 한계가 있다. 보상을 예측하는 M 모델과 함께 학습하면 VAE가 이미지의 작업 관련 영역에 집중할 수 있지만, 재학습 없이는 새로운 작업에 VAE를 재사용하지 못할 수 있다는 단점이 있다. 또다른 우려 사항은 월드 모델의 제한된 용량이다. LSTM 기반 월드 모델은 가중치 연결 내부에 기록된 모든 정보를 저장하지 못할 수 있다. 향후 연구에서는 에이전트가 더 복잡한 세계를 탐색하는 방법을 학습하도록 하기 위해 VAE와 MDN-RNN을 더 큰 용량의 모델로 대체하거나, 외부 메모리 모듈을 통합하는 방안을 모색할 예정이다.
* Deep Q-Networks와의 차이
월드 모델은 DQN과 상당히 다른 접근 방법을 가지고 있다.
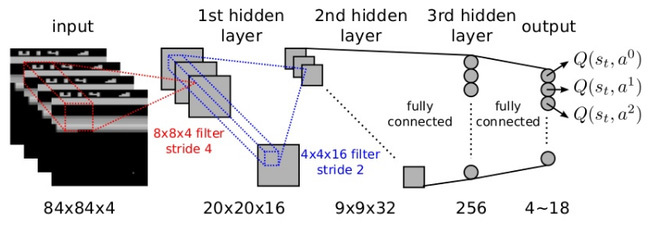
DQN에서 입력은 과거, 현재 화면만 사용한다. 즉, 미래의 일은 알지 못한다. 이전에 했던 반복적인 경험을 통해, 지금 상태에서 어떤 행동이 최선인지를 알고 있을 뿐이다. 예를 들어, 갈증 상태에서 내 눈 앞에 물병이 놓여 있다고 가정하자. 인간은 보통 미래를 예측하고 행동한다. 즉 물을 마시면 병 안의 물이 사라지고, 갈증이 해소될 것이라는 것을 상상하고 자연스럽게 실천한다. DQN의 경우 물을 마시는 것이 갈증 해소라는 '목표'를 달성하는 데 옳은 행동임을 알지만, 구체적으로 병 안의 물이 어떻게 될 지 인지하지 못한다. 인간의 무의식처럼 행동한다.
예시를 들어보자. DQN은 기본적으로 Q-learning을 기반으로 한다. Q(s,a)는 현재 상태 s에서 어떤 행동 a가 가장 좋은 것인지 알려주는 함수다. 목표 G를 찾는 길찾기의 경우, G에 도착하는 행동을 하면 보상값으로 100을 얻는다. 그리고 계속 반복적인 경험을 통해, 보상값이 조금씩 주변 상태로 감소되면서 퍼져 나간다. 그래서 멀리 떨어진 위치에서도 목표를 향해 어떤 행동을 해야하는지 알 수 있다.
월드 모델은 바로 다음에 일어날 화면을 예측하고, 예측을 근거로 행동을 결정한다. 위와 같이 그림을 그릴 때 머릿속으로 내가 그린 선이 어떻게 나타날 지 상상을 한다. 그다음 실제 행동으로 옮기게 된다. 미래를 예측하고, 보다 복잡한 추론을 할 수 있다면 면에서 인간의 의식과 조금 유사하기도 하다.
예시를 들어보자. 월드 모델에서는 현재 화면 z와 미래의 화면 h를 입력으로 받아, 선형 함수로 행동을 결정한다. 이 함수의 파라미터는 진화 전략을 사용하여 최적화를 한다. 여기서 진화 전략은 환경에 살아남는 자손을 계속 번식하여 해를 구하는 '유전 알고리즘'과 비슷한 방식이다.
출처 : http://aidev.co.kr/deeplearning/4304
출처 : https://worldmodels.github.io/



