1. Q-learning in grid world
파이참의 가상 환경에서 실행한다. 새로운 프로젝트를 생성하여 'pip install numpy', 'pip install padas', 'pip install matplotlib'을 터미널 창에 입력한 후 설치를 완료한다. Run시키면 아래 코드가 수행된다.
(1) 코드 설명
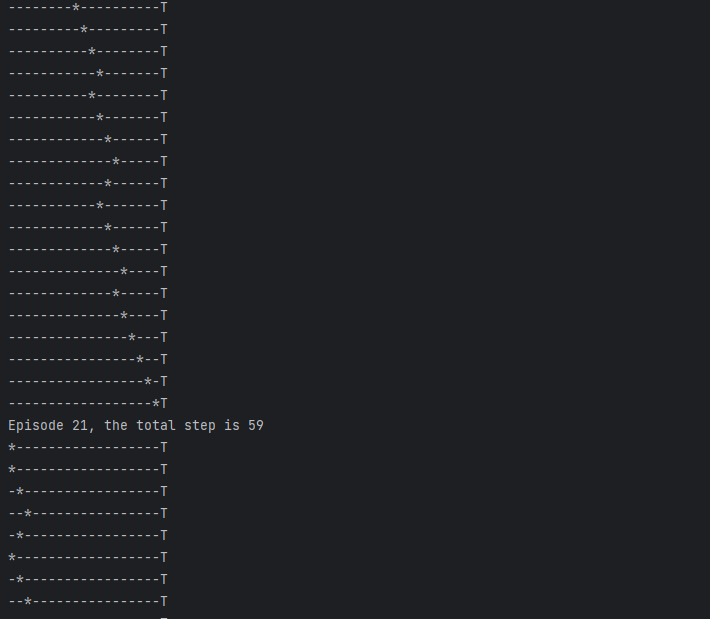
코드를 간단히 설명하겠다. 1차원으로 총 20개의 상태를 가지는 20x1 그리드 월드에서 에이전트는 'left' 혹은 'right', 2가지 행동을 취할 수 있다. 목표는 최적의 행동을 학습하여 'T'라는 종료 상태에 도달하는 것이다. 종료 상태에 도달하면, 다시 처음으로 돌아가 최적의 행동을 학습한다. 이러한 시행착오를 200번 겪은 후 코드는 종료된다. 전체 루프를 200번 반복, 즉 200개의 에피소드를 실행한 후 종료된다. 아래 그래프는 각 에피소드의 결과 및 성능을 출력한다.
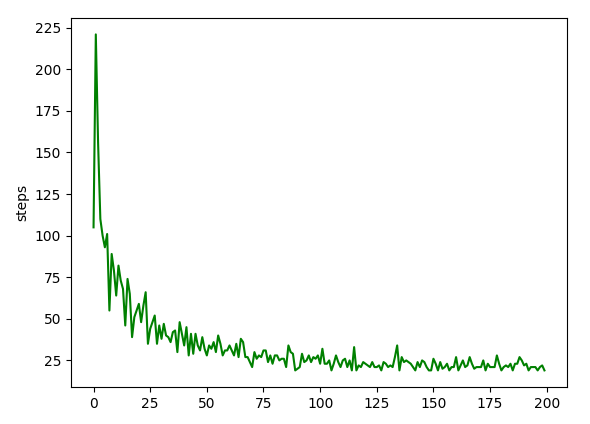
그래프를 보면 처음 'T'로 도달할 때는 105번이 걸린 것이고, 20번째로 'T'에 도달할 때는 55번이 걸렸으며, 90번째로 'T'에 도달할 때는 19번이 걸렸다. 이와 같이 학습을 통해 점차 시도 횟수를 줄여나가는 것을 알 수 있으며 성능이 높아짐을 알 수 있다.
(2) 코드 분석
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import time
# 상수 및 매개변수 정의
ALPHA = 0.1 # 학습률
GAMMA = 0.95 #
EPSILION = 0.9 # greedy 정책에서 사용되는 확률
N_STATE = 20 # 상태의 개수
ACTIONS = ['left', 'right'] # 가능한 행동 목록
MAX_EPISODES = 200 # 에피소드 수
FRESH_TIME = 0.1 # 화면을 갱신하는 간격
# Q-table 초기화 함수
# Q-table이란 상태와 가능한 행동에 대한 가치를 저장한 표.
def build_q_table(n_state, actions):
q_table = pd.DataFrame(
np.zeros((n_state, len(actions))),
np.arange(n_state),
actions
)
return q_table
# 에이전트가 상태에 따른 행동 선택을 결정하는 함수
# 기본적으로 Epsilon-Greedy Policy를 따른다.
def choose_action(state, q_table):
# epslion - greedy policy
state_action = q_table.loc[state, :]
if np.random.uniform() > EPSILION or (state_action == 0).all():
action_name = np.random.choice(ACTIONS)
else:
action_name = state_action.idxmax()
return action_name
# 보상, 다음 상태를 계산하는 함수
def get_env_feedback(state, action):
if action == 'right':
if state == N_STATE - 2:
next_state = 'terminal'
reward = 1
else:
next_state = state + 1
reward = -0.5
else:
if state == 0:
next_state = 0
else:
next_state = state - 1
reward = -0.5
return next_state, reward
# 환경 업데이트 및 현재 상태 출력 함수
# 출력값은 에피소드와 스텝 횟수이며, 에피소드 종료 시 'T'로 표시된다.
def update_env(state, episode, step_counter):
env = ['-'] * (N_STATE - 1) + ['T']
if state == 'terminal':
print("Episode {}, the total step is {}".format(episode + 1, step_counter))
final_env = ['-'] * (N_STATE - 1) + ['T']
return True, step_counter
else:
env[state] = '*'
env = ''.join(env)
print(env)
time.sleep(FRESH_TIME)
return False, step_counter
# Q-learning 알고리즘 구현 함수
def q_learning():
q_table = build_q_table(N_STATE, ACTIONS)
step_counter_times = []
for episode in range(MAX_EPISODES):
state = 0
is_terminal = False
step_counter = 0
update_env(state, episode, step_counter)
while not is_terminal:
action = choose_action(state, q_table)
next_state, reward = get_env_feedback(state, action)
next_q = q_table.loc[state, action]
if next_state == 'terminal':
is_terminal = True
q_target = reward
else:
delta = reward + GAMMA * q_table.iloc[next_state, :].max() - q_table.loc[state, action]
q_table.loc[state, action] += ALPHA * delta
state = next_state
is_terminal, steps = update_env(state, episode, step_counter + 1)
step_counter += 1
if is_terminal:
step_counter_times.append(steps)
return q_table, step_counter_times
# 메인 함수
def main():
q_table, step_counter_times = q_learning()
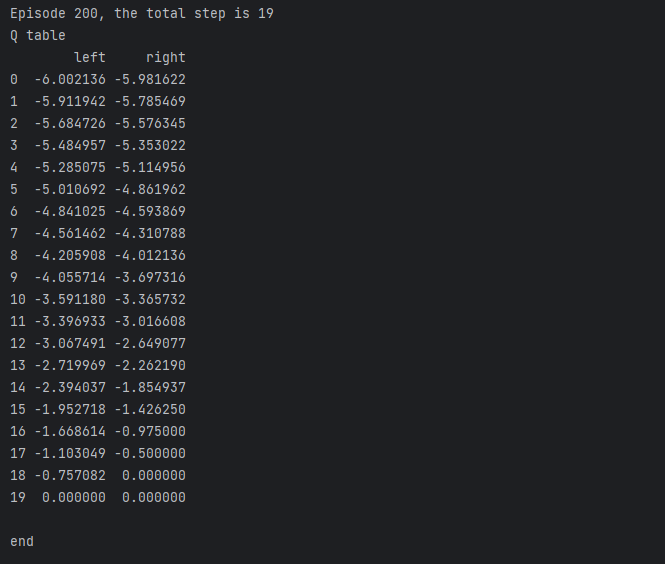
print("Q table\n{}\n".format(q_table))
print('end')
plt.plot(step_counter_times, 'g-')
plt.ylabel("steps")
plt.show()
print("The step_counter_times is {}".format(step_counter_times))
# 실행 시작 지점
main()
2. DQN in grid world
파이참의 가상 환경에서 실행한다. 새로운 프로젝트를 생성하여 'pip install numpy', 'pip install padas', 'pip install matplotlib'을 터미널 창에 입력한 후 설치를 완료한다. 추가로 'pip install gym', 'pip install torch', 'pip install tensorboardx'를 통해 모듈들을 설치한다. Run시키면 아래 코드가 수행된다.
(1) 에러 해결
버전 차이로 인해 에러가 발생하였으므로 'pip uninstall gym', 'pip install gym==0.25.2'를 통해 해결하자. 간단히 최신 버전의 gym을 지우고, 0.25.2 버전의 gym을 설치한 것이다.
-> 출처는 https://blog.csdn.net/dream6985/article/details/126847399
-> 기초 예제 중 하나라 그런지 다행히 Diffusion Q-learning할 때에 비해 버전 충돌 문제가 너무 쉽게 해결되었다. ㅎㅎ
(2) 코드 설명
코드를 간단히 설명하겠다. DQN 알고리즘을 사용하여 'CartPole-v0'라는 Gym 환경에서 학습하는 예제다. 'CartPole-v0' 환경은 물리학적 모델을 기반으로 한 간단한 시뮬레이션 환경으로, 연속적인 상태 공간과 이산적인 행동 공간을 가진다. 목표는 막대가 쓰러지지 않고 가능한 오랜 시간 동안 유지하는 것으로, 이를 위해 에이전트는 환경으로부터 상태 정보를 받아서 막대를 'left' 또는 'right'로 움직이는 행동을 선택한다. num_episode에 지정된 에피소드 횟수만큼 학습을 반복한 후 종료된다.
(3) 코드 분석
import argparse
import pickle
from collections import namedtuple
from itertools import count
import os, time
import numpy as np
import matplotlib.pyplot as plt
import gym
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Normal, Categorical
from torch.utils.data.sampler import BatchSampler, SubsetRandomSampler
from tensorboardX import SummaryWriter
# 상수 정의
seed = 1
render = False # 학습 환경을 시각적으로 표시
num_episodes = 2000 # 학습 에피소드 수
env = gym.make('CartPole-v0').unwrapped # Gym 환경 생성, 언래핑
num_state = env.observation_space.shape[0] # 환경의 상태 공간의 차원 수
num_action = env.action_space.n # 환경의 액션 공간에서 가능한 이산 액션의 수
torch.manual_seed(seed) # 파이토치의 랜덤 시드 설정
env.seed(seed) # Gym의 랜덤 시드 설정
# 강화 학습에 사용되는 경험 데이터를 표현하는 데이터 구조
# 기본적으로 상태, 행동, 보상, 다음 상태로 구성된다.
Transition = namedtuple('Transition', ['state', 'action', 'reward', 'next_state'])
# DQN 모델을 정의하는 클래스
# 신경망을 생성, 상태를 행동으로 매핑
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(num_state, 100)
self.fc2 = nn.Linear(100, num_action)
def forward(self, x): #Model Inference: During inference, when the network is used to make predictions, the forward method is called.
x = F.relu(self.fc1(x))
action_value = self.fc2(x)
return action_value
# DQN 알고리즘 구현 클래스
# 경험 리플레이, 타겟 네트워크를 사용하여 강화 학습을 수행한다.
class DQN():
capacity = 8000
learning_rate = 1e-3
memory_count = 0
batch_size = 256
gamma = 0.995
update_count = 0
def __init__(self):
super(DQN, self).__init__()
self.target_net, self.act_net = Net(), Net()
self.memory = [None]*self.capacity
self.optimizer = optim.Adam(self.act_net.parameters(), self.learning_rate)
self.loss_func = nn.MSELoss()
self.writer = SummaryWriter('./DQN/logs')
def select_action(self,state): # 행동 선택, 입실론-그리디 정책 사용
state = torch.tensor(state, dtype=torch.float).unsqueeze(0)
value = self.act_net(state)
action_max_value, index = torch.max(value, 1)
action = index.item()
if np.random.rand(1) >= 0.9: # epslion greedy
action = np.random.choice(range(num_action), 1).item()
return action
def store_transition(self,transition): # 경험 데이터를 메모리에 저장
index = self.memory_count % self.capacity
self.memory[index] = transition
self.memory_count += 1
return self.memory_count >= self.capacity
def update(self):
if self.memory_count >= self.capacity:
state = torch.tensor([t.state for t in self.memory]).float()
action = torch.LongTensor([t.action for t in self.memory]).view(-1,1).long()
reward = torch.tensor([t.reward for t in self.memory]).float()
next_state = torch.tensor([t.next_state for t in self.memory]).float()
reward = (reward - reward.mean()) / (reward.std() + 1e-7)
with torch.no_grad():
target_v = reward + self.gamma * self.target_net(next_state).max(1)[0]
#Update...
for index in BatchSampler(SubsetRandomSampler(range(len(self.memory))), batch_size=self.batch_size, drop_last=False):
v = (self.act_net(state).gather(1, action))[index]
loss = self.loss_func(target_v[index].unsqueeze(1), (self.act_net(state).gather(1, action))[index])
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
self.writer.add_scalar('loss/value_loss', loss, self.update_count)
self.update_count +=1
if self.update_count % 100 ==0:
self.target_net.load_state_dict(self.act_net.state_dict())
else:
print("Memory Buff is too less")
# main, 주요 학습 루프를 실행
# 환경 초기화, 에이전트가 행동 선택, 경험 데이터 수집, 모델 업데이트 등
def main():
agent = DQN()
for i_ep in range(num_episodes):
state = env.reset()
if render: env.render()
for t in range(10000):
action = agent.select_action(state)
step_result = env.step(action)
next_state, reward, done, info = step_result[:4]
#next_state, reward, done, info = env.step(action)
if render: env.render()
transition = Transition(state, action, reward, next_state)
agent.store_transition(transition)
state = next_state
if done or t >=9999:
agent.writer.add_scalar('live/finish_step', t+1, global_step=i_ep)
agent.update()
if i_ep % 10 == 0:
print("episodes {}, step is {} ".format(i_ep, t))
break
if __name__ == '__main__':
main()
Grid world에서 수행한 것은 아니지만, 그래도 난이도가 낮은 예제로 들고 왔다.
'LAB > RL, IRL' 카테고리의 다른 글
| 강화학습(5) PPO, DDPG, TD3, and so on.. (0) | 2024.01.30 |
|---|---|
| 강화학습(4) Actor-critic, A2C, A3C, SAC (0) | 2024.01.30 |
| 강화학습(2) DQN, Double DQN, Deuling DQN (1) | 2024.01.30 |
| 강화학습(1) 강화 학습 개념 정리 (1) | 2024.01.29 |
| GAIL (0) | 2023.07.18 |



