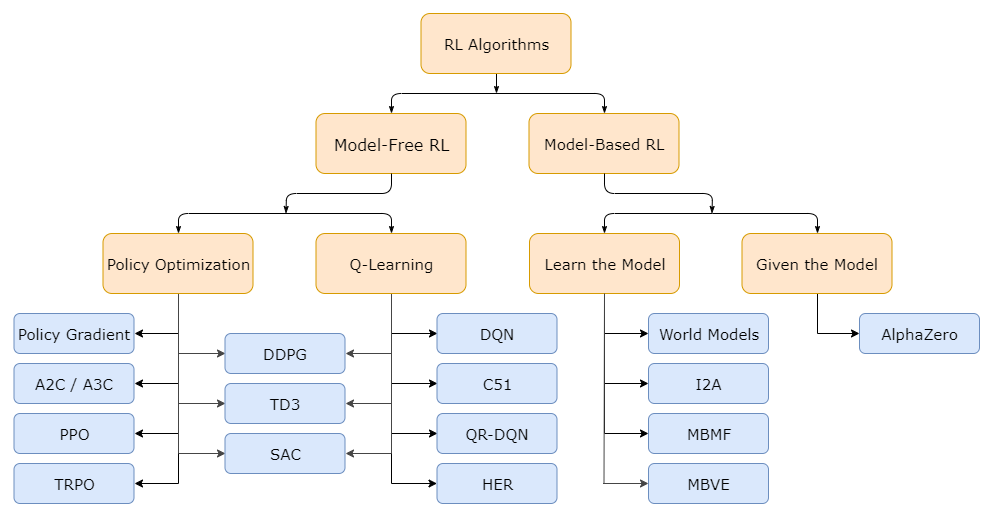
DQN(2013) -> DDPG(2015) -> A2C, A3C(2016) -> PPO(2017) -> TD3, SAC(2018) 순서.
1. Actor-Critic
(1) Actor-Critic, A2C
Acotr 네트워크, Critic 네트워크. 2개의 네트워크를 이용한다. Actor는 상태가 주어졌을 때 행동을 결정하고, Critic은 상태의 가치를 평가한다. 행동과 가치를 분리한다는 점에서 Dueling DQN과 유사하지만, Actor-critic은 마지막에 값을 합치지 않는다. 물론 Actor-critic은 replay buffer를 사용하지 않는다.
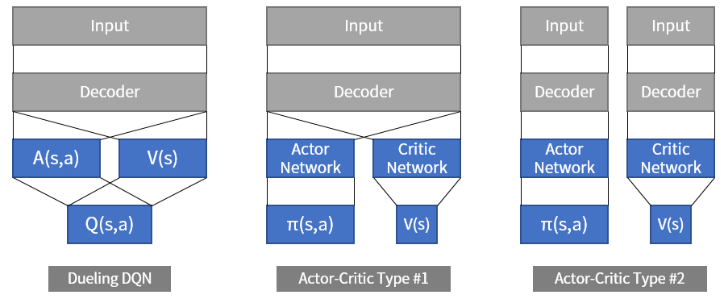

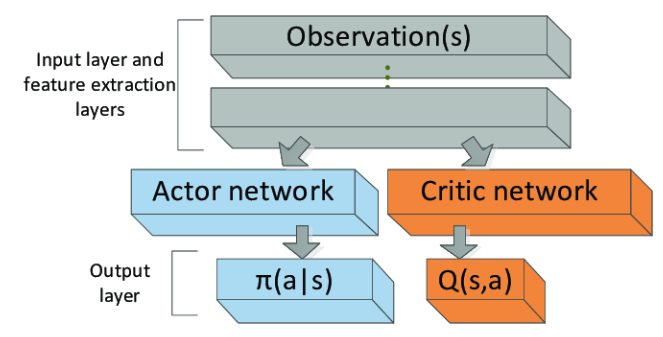
Actor-critic은 입력을 해석하는 파라미터(decoder)를 공유하느냐 그렇지 않느냐에 따라 2가지로 나뉜다. 그리고 Actor-critic은 Replay buffer를 사용하지 않고, 매 step마다 얻어진 상태(s), 행동(a), 보상(r), 다음 상태(s')를 이용해서 모델을 학습시킨다.
(2) A3C
Asynchronous Adbantage Actor-critic은 한 개가 아닌, 여러 개의 agent를 실행하며 주기적으로, 비동기적으로 공유 네트워크를 업데이트한다. 다른 agent의 실행과는 독립적으로, 자기가 공유 네트웤르르 업데이트하고 싶을 때 업데이트하기 때문에 비동기적이라 한다.

A2C agent 여러 개를 독립적으로 실행시키며, global network와 학습 결과를 주고받는 구조다. 이 경우의 장점은 다양한 환경에서 얻을 수 있는 다양한 데이터로 학습이 가능하다는 것이다. DQN 역시 replay buffer를 사용하므로 다양한 경험을 활용할 수 있으나, 오래된 데이터라는 단점을 가진다. A3C는 이를 보완하여 항상 최신 데이터만을 사용해서 학습한다.
좀더 퍼포먼스를 개선하고 싶다면, A3C agent에 메모리를 추가해도 된다. 과거에 봤던 상태를 LSTM 등으로 기억해서 현재의 행동을 정할 때 활용한다.
(3) Actor-critic code
Cartpole 환경에서의 Actor-critic 코드를 실행시켜 보자.
2. SAC
내용
출처1: https://greentec.github.io/reinforcement-learning-fourth/
출처3: https://velog.io/@chulhongsung/A2CAdvantage-Actor-Critic-%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98 (손으로 풀어보기 좋을 듯)
'LAB > RL, IRL' 카테고리의 다른 글
| 강화학습(8) GAIL 실행하기 (LINUX) (1) | 2024.02.01 |
|---|---|
| 강화학습(5) PPO, DDPG, TD3, and so on.. (0) | 2024.01.30 |
| 강화학습(3) 코드 실습 : Q-learning, DQN (0) | 2024.01.30 |
| 강화학습(2) DQN, Double DQN, Deuling DQN (1) | 2024.01.30 |
| 강화학습(1) 강화 학습 개념 정리 (1) | 2024.01.29 |



