
DQN(2013) -> A2C, A3C(2016) -> DDPG(2015) -> PPO(2017) -> TD3, SAC(2018) 순서.
1. DQN
(1) Deep Q-Learning
기존의 Q-learning은 state-action(s,a)에 해당하는 Q값을 테이블 형식으로 저장하여 학습한다. 상태 공간, 행동 공간이 커지게 되면 모든 Q값을 저장하기 어려워진다. (메모리 문제, 긴 탐험 시간 문제). Deep Q-Learning은 이를 딥러닝으로 해결한 알고리즘이다. Q-table에 해당하는 Q함수를 비선형 함수로 근사시키며, Q함수의 가중치 파라미터들을 θ로 표시하였다.
1. 파라미터를 초기화, 매 스텝마다 2~5를 반복한다.
2. Action at를 e-greedy 방식에 따라 선택한다.
3. Action at를 수행하여 transition et = (st, at, rt, st+1)을 얻는다.
4. target value yt = rt + rmaxa'A(st+1,a';theta)를 계산한다.
5. Loss function (yt-Q(st, at;theta)^2를 최소화하는 방향으로 theta를 업데이트한다.

(2) DQN
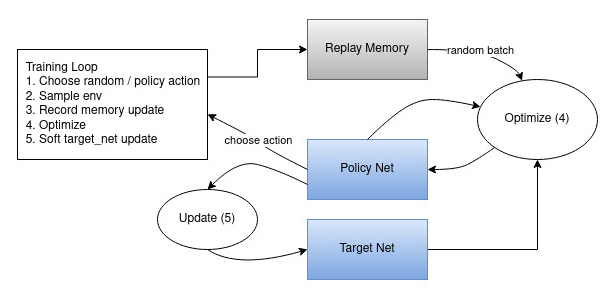
학습의 안정성 문제를 해결하기 위해 DQN은 CNN을 사용한다. 입력으로 state를 받고, 출력으로 action에 해당하는 여러 개의 Q-value들을 뽑는다. 리플레이 버퍼를 이용해 데이터 상관성 문제를 해결한다. 타겟 네트워크를 이용한다.

Experience replay에 대해 자세히 알아보자. Replay memory라는 버퍼를 하나 만들어 현재 생성된 샘플 et를 저장한다. 현재 선택된 action을 수행해 결과 값과 샘플을 얻는다. 그러나 이를 바로 평가에 이용하지 않고, 의도적으로 지연시켜준다. 이를 통해 기존 Deep Q-learning에서 학습 불안전성을 유발하는 요인들을 해결할 수 있다. replay memory를 이용해 랜덤하게 추출된 샘플들은 각각 다른 시간에서 수행된 샘플들이고, '랜덤' 추출에 의해 다양한 행동을 동시에 고려할 수 있어 데이터 분포가 편향되지 않게 나온다.
결론적으로 장점은 크게 3가지다. [1] Data effeciency가 증가, 하나의 샘플을 여러 번의 모델 업데이트에 이용할 수 있으므로 데이터의 효율이 증가한다. [2] Sample correlation 감소, 랜덤 추출로 update variance를 낮춘다. [3] 학습 안정성 증가, Behavior policy가 평균화되어 학습 시 파라미터의 진동, 발산을 억제한다.

Target network에 대해 자세히 알아보자. 기본적인 컨셉은 기존의 Q-network를 동일하게 복제하여 main Q-network와 target network의 이중화된 구조로 만든다. target value가 계속 움직여서 발생하는 학습 불안정성을 개선할 수 있다.기존의 Deep Q-Learning은 target value 역시 θ로 파라미터화되어 있어서 매 스텝마다 같이 움직였다. 이는 학습의 불안정성을 유발하였다.
[1] Main Q-network는 상태, 행동을 이용해 결과값이 되는 action-value Q를 얻는다. 매 스텝마다 파라미터가 업데이트된다. [2] Target network는 업데이트의 기준값이 되는 target value y를 얻는데 이용된다. 매번 업데이트되지 않고, C 스텝마다 파라미터가 main network의 파라미터와 동기화된다. 이처럼 target value를 C 스텝 동안 고정시켜두면, 해당 구간 동안은 원하는 방향으로 모델을 업데이트할 수 있으며 C 스텝 이후 target network와 main network를 동일화시켜 bias를 줄여주면 된다.
>> 타겟 네트워크는 Q-network가 몇 번 학습하는 동안 고정된 값으로 있다가, 주기적으로 원래 Q 네트워크 값으로 리셋된다. 이렇게 되면 고정된 타겟 네트워크로 Q 네트워크가 가까워질 수 있어서 효과적이다.


-> 훈련 중에 신경망을 지속적으로 업데이트해 타깃 값을 수정하기 때문에 타깃이 움직이는 문제가 발생한다. 이 문제를 해결하기 위해 DQN은 2개의 신경망을 사용했다. 하나는 online network로 끊임 없이 업데이트하는 신경망이고, 하나는 target network로 매 N회 반복마다 업데이트하는 신경망이다. 온라인 네트워크는 환경과 상호작용하는 데 사용되며, 타깃 네트워크는 대상값을 예측하는 데 사용된다.
(3) DQN code
Cartpole 환경에서의 DQN 코드를 실행시켜 보자.
2. Double DQN
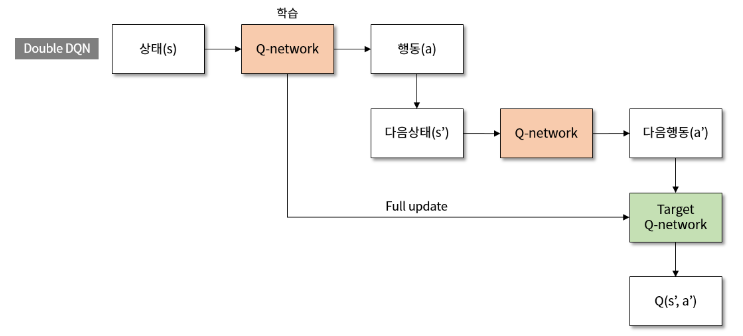
AI를 학습할 때, 목표값(target network)과 결과값(prediction network)의 차이를 줄이는 방법을 이용한다. 그러나 목표값(target network)이 처음부터 잘못된 값이라면, 네트워크는 제대로 된 결과를 학습할 수 없을 것이다. 기존 DQN의 목표값이 특정 조건에서 overestimate되므로, 해당 알고리즘이 제안되었다.
DQN과의 차이점은 target value yt 공식이다. Q-learning 기반 알고리즘은 TD target(Temporal Difference, 시간차 target)을 이용한다. 즉 직접적인 max Q를 통해 현재 상태의 가치를 추정한다. maxQ(s', a')는 상태 s'가 주어졌을 때 Q-network에서 가장 Q 값이 높은 a'를 선택한 다음, 그 Q값을 γ에 곱해줘서 Q(s,a)의 목표값을 만드는 것이다. 문제는 a'를 선택할 때와, Q 값을 가져올 때 둘다 동일한 Q 네트워크를 사용한다는 것이다. 이렇게 되면 max 연산이 계속되어 Q 값이 점점 커지게 되고, Q 네트워크의 성능은 떨어진다. 이 과정에서 DQN의 max operation이 target value의 overestimation을 일으킨다. Double DQN에서는 action의 선택과 평가를 분리하여 이를 방지한다.

위의 식에서 QA 네트워크가 a'를 선택하는 부분이고, QB 네트워크가 Q값을 가져오는 부분이다. 2개의 Q 네트워크를 사용하면 Q값이 불필요하게 커지는 것을 막을 수 있다.
아래의 식은 DQN과 Double DQN의 유일한 차이점인 target value 공식이다.

3. Dueling DQN
Q값을 구하기 전에, 네트워크의 결과값을 V과 A로 나눈 다음에 다시 합치는 아이디어다. V는 가치 함수, A는 advantage 값이다. (A는 각 스텝별로 계산되므로 Q값과 비슷한 값이다.) 아무튼 각 상태에 대한 V를 계산해서 Q에 아래와 같이 더해준다.
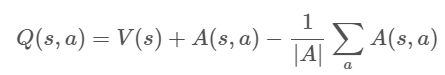
높은 V값을 가진 상태의 Q값은 높아질 것이고, V값이 낮다면 Q값도 낮아질 것이다. agent는 높은 Q값이 이끄는 상태로 이동하게 된다. 이처럼 가치와 행동에 대한 정보를 분리하여 계산한다. 그러나 결국엔 합쳐서 최종 Q값을 구한 후 행동을 선택한다.

출처2: https://greentec.github.io/reinforcement-learning-third/ (이거 진짜 굳, 이해하기 쉬움)
출처3:
'LAB > RL, IRL' 카테고리의 다른 글
| 강화학습(4) Actor-critic, A2C, A3C, SAC (0) | 2024.01.30 |
|---|---|
| 강화학습(3) 코드 실습 : Q-learning, DQN (0) | 2024.01.30 |
| 강화학습(1) 강화 학습 개념 정리 (1) | 2024.01.29 |
| GAIL (0) | 2023.07.18 |
| DGAIL 코드 분석(DDPG.py) (0) | 2023.07.17 |



