1. Human-Machine Interaction(HMI)
인간과 기계가 협동을 함에 있어서 사람의 의도를 파악하는 것은 중요한 문제다.
Task를 수행할 수 있도록 보상함수를 설계하는 과정이 사람의 의도를 반영하는 것과 같다.

2. GAIL의 등장 배경
전문가는 보상함수로부터 얻어지는 보상을 최대로 하는 행동[최적 정책]만 한다고 가정한다.
전문가의 행동을 최대의 보상으로 평가하는 보상함수를 찾으면? 그것이 전문가의 의도.

IRL은 Reward function의 구조를 정의하고, weight를 업데이트한다.
-> 보상함수가 선형조합이라고 가정하는 제한
3. GANs
생성 모델(G)과 식별 모델(D)로 구성.
두 모델이 적대적인 경쟁적 학습을 통해 실제와 유사한 데이터를 생성하는 것을 목표로 한다.
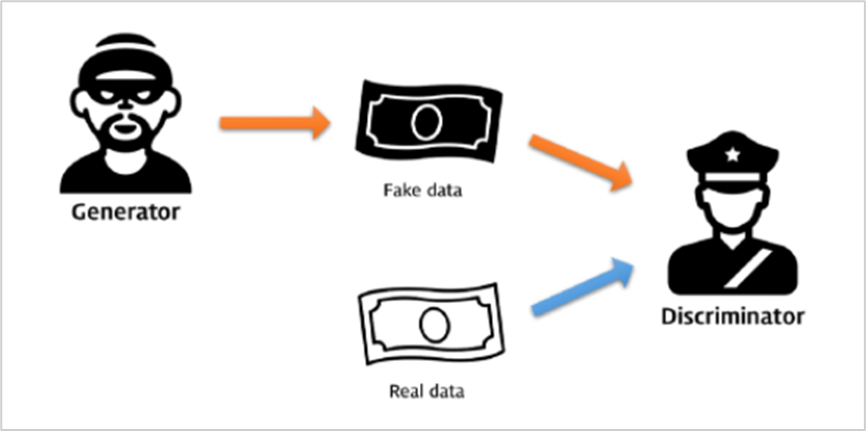
(1) Generator : 위조지폐 생산 -> D를 속일만큼 Real과 유사하게 생산
(2) Discriminator : 실제 지폐와 위조지폐 구별 -> Real과 Fake 사이를 구분하는 기준 찾기
4. GAIL의 보상 함수
전통적인 강화학습해선, 사람이 수동으로 보상 함수를 설계하고 정희한다.
(보상 함수는 학습 과정에 매우 중요한 역할을 수행하며, 알고리즘 성능에도 큰 영향을 미친다.)
그러나 수동 설계는 어렵고 복잡하다. 또한 보상 함수의 구조가 고정되어 있어 일반화에 제약이 있다.
GAIL은 신경망을 사용하여 보상 함수를 복원한다.
즉, 구조적 제한 없이 보상 함수를 학습할 수 있다. 일반화, 적응성이 향상된다.
5. 코드 실행
아직 ing 중이다. 우리가 코드에 손을 대야만 하는 오류여서 좀 더 고민이 필요하다. 다른 깃허브 파일을 찾아야할 듯.
https://ufubbd.tistory.com/147
'LAB > RL, IRL' 카테고리의 다른 글
| 강화학습(3) 코드 실습 : Q-learning, DQN (0) | 2024.01.30 |
|---|---|
| 강화학습(2) DQN, Double DQN, Deuling DQN (1) | 2024.01.30 |
| 강화학습(1) 강화 학습 개념 정리 (1) | 2024.01.29 |
| DGAIL 코드 분석(DDPG.py) (0) | 2023.07.17 |
| 역강화학습(1) 역강화학습 기술 동향 (0) | 2023.06.22 |



