본 코드는 DDPG(Deep Deterministic Policy Gradient) 알고리즘과 GAIL(Generative Adversarial Imitation Learning) 알고리즘을 조합하여, 강화학습을 수행하는 모델을 구현하였다.
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from utils import ExpertTraj
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
1. Actor 클래스
class Actor(nn.Module):
def __init__(self, state_dim, action_dim, max_action):
super(Actor, self).__init__()
self.l1 = nn.Linear(state_dim, 400)
self.l2 = nn.Linear(400, 300)
self.l3 = nn.Linear(300, action_dim)
self.max_action = max_action
def forward(self, state):
a = F.relu(self.l1(state))
a = F.relu(self.l2(a))
a = torch.tanh(self.l3(a)) * self.max_action
return a상태(state)를 입력으로 받아서, 행동(action)을 출력하는 신경망 모델이다.
__init__ 메서드는 신경망의 구조를 정의, 초기화한다. 상태의 차원, 행동의 차원, 행동의 최댓값을 입력으로 받는다. 초기화 과정에서는 선형 레이어('nn.Linear')를 사용하여 신경망을 구성한다. self.l1, selt.l2, selg.l3은 각각 첫 번째, 두 번째, 세 번째 선형 레이어를 나타낸다. 각각의 레이어에는 입력 차원과 출력 차원이 정의되어 있다. forward 메서드에선 주어진 상태를 입력으로 받아서 행동을 출력한다. state를 첫 번째 선형 레이어에 통과시키고, 활성화 함수 ReLU를 적용한다. 그 다음, 두 번째 레이어와 세 번째 레이어에도 순차적으로 통과시킨다. 출력 값을 [-1, 1] 범위로 조정 후, 최대 행동값을 곱하여 실제 행동을 얻는다.
2. Critic 클래스
class Critic(nn.Module):
def __init__(self, state_dim, action_dim):
super(Critic, self).__init__()
self.l1 = nn.Linear(state_dim + action_dim, 400)
self.l2 = nn.Linear(400, 300)
self.l3 = nn.Linear(300, 1)
def forward(self, state, action):
state_action = torch.cat([state, action], 1)
q = F.relu(self.l1(state_action))
q = F.relu(self.l2(q))
q = self.l3(q)
return q상태와 행동을 입력으로 받아서, Q값을 출력하는 신경망 모델이다.
__init__ 메서드는 신경망의 구조를 정의, 초기화한다. forward 메서드는 주어진 상태와 행동을 입력으로 받아서 가치(Q값)를 출력한다. torch.cat 함수를 사용하여 입력 상태와 행동을 결합한 후, 선형 레이어 통과 및 활성화 함수 ReLU 적용을 반복한다. DDPG 알고리즘에서는 Critic 신경망을 사용하여 현재 상태와 행동에 대한 가치를 평가한다.
3. Discriminator 클래스
class Discriminator(nn.Module):
def __init__(self, state_dim, action_dim):
super(Discriminator, self).__init__()
self.l1 = nn.Linear(state_dim + action_dim, 400)
self.l2 = nn.Linear(400, 300)
self.l3 = nn.Linear(300, 1)
def forward(self, state, action):
state_action = torch.cat([state, action], 1)
x = torch.tanh(self.l1(state_action))
x = torch.tanh(self.l2(x))
x = torch.sigmoid(self.l3(x))
return x상태와 행동을 입력으로 받아서, 해당 상태와 행동이 전문가(expert)의 것인지 정책(policy)의 것인지를 구분하는 신경망 모델이다.
__init__ 메서드는 신경망의 구조를 정의, 초기화한다. forward 메서드는 주어진 상태와 행동을 입력으로 받아서 이진 분류 결과를 출력한다. torch.cat 함수를 사용하여 입력 상태와 행동을 결합한 후, 선형 레이어 통과 및 활성화 함수 ReLU 적용을 반복한다. sigmoid 함수를 사용하여 0과 1 사이의 값으로 출력한다.
4. GAIL 클래스
class GAIL:
def __init__(self, env_name, state_dim, action_dim, max_action, lr, betas):
self.discriminator = Discriminator(state_dim, action_dim).to(device)
self.optim_discriminator = torch.optim.Adam(self.discriminator.parameters(), lr=lr, betas=betas)
self.max_action = max_action
self.expert = ExpertTraj(env_name)
self.loss_fn = nn.BCELoss()
def select_action(self, state):
state = torch.FloatTensor(state.reshape(1, -1)).to(device)
return self.actor(state).cpu().data.numpy().flatten()
def update(self, n_iter, batch_size=100):
for i in range(n_iter):
# sample expert transitions
exp_state, exp_action = self.expert.sample(batch_size)
exp_state = torch.FloatTensor(exp_state).to(device)
exp_action = torch.FloatTensor(exp_action).to(device)
#######################
# update discriminator
#######################
self.optim_discriminator.zero_grad()
# label tensors
exp_label = torch.full((batch_size, 1), 1, device=device)
policy_label = torch.full((batch_size, 1), 0, device=device)
# with expert transitions
prob_exp = self.discriminator(exp_state, exp_action)
loss = self.loss_fn(prob_exp, exp_label)
# with policy transitions
prob_policy = self.discriminator(state, action.detach())
loss += self.loss_fn(prob_policy, policy_label)
# take gradient step
loss.backward()
self.optim_discriminator.step()
################
# update policy
################
self.optim_actor.zero_grad()
loss_actor = -self.discriminator(state, action)
loss_actor.mean().backward()
self.optim_actor.step()GAIL 알고리즘을 구현한 클래스다.
-> IRL의 한 유형으로서, 생성적 적대 신경망(GAN)을 사용하여 전문가의 행동을 모방하고자 하는 강화학습 알고리즘
__init__ 메서드는 GAIL 클래스를 초기화한다. Discriminator 신경망과 옵티마이저를 초기화하고, 전문가(expert)의 데이터를 가져올 ExpertTraj 클래스를 생성한다. select_action 메서드는 주어진 상태에 대해 정책을 통해, 행동을 선택한다. 주어진 상태를 신경망에 입력하여 행동을 출력한다. update 메서드는 주어진 반복 횟수와 배치 크기에 따라 Discriminator 신경망을 학습하는 메서드다. 전문가의 transition 데이터, 정책의 transition 데이터를 사용하여 Discriminator를 업데이트한다. 이를 위해 각각의 레이블을 정의하고, 이진 교차 엔트로피 손실(BCELoss)를 계산한다. 그 후, 손실을 역전파하여 Discriminator를 학습한다.
-> 손실을 역전파한다는 것의 의미는? 신경망에서 손실 함수 값에 대한 기울기를 계산, 신경망의 가중치와 편향을 업데이트하는 것을 의미. 역전파는 경사하강법과 같은 최적화 알고리즘과 결합하여 모델을 학습하는 데 사용된다.
5. DDPG 클래스
class DDPG:
def __init__(self, lr, state_dim, action_dim, max_action, env_name, betas):
self.actor = Actor(state_dim, action_dim, max_action).to(device)
self.actor_target = Actor(state_dim, action_dim, max_action).to(device)
self.actor_target.load_state_dict(self.actor.state_dict())
self.actor_optimizer = optim.Adam(self.actor.parameters(), lr=lr)
self.critic = Critic(state_dim, action_dim).to(device)
self.critic_target = Critic(state_dim, action_dim).to(device)
self.critic_target.load_state_dict(self.critic.state_dict())
self.critic_optimizer = optim.Adam(self.critic.parameters(), lr=lr)
###GAN
self.discriminator = Discriminator(state_dim, action_dim).to(device)
self.optim_discriminator = torch.optim.Adam(self.discriminator.parameters(), lr=lr, betas=betas)
self.expert = ExpertTraj(env_name)
self.loss_fn = nn.BCELoss()
####
self.max_action = max_action
def select_action(self, state):
state = torch.FloatTensor(state.reshape(1, -1)).to(device)
return self.actor(state).cpu().data.numpy().flatten()
def update(self, replay_buffer, n_iter, batch_size, gamma, polyak, policy_noise, noise_clip, policy_delay):
for i in range(n_iter):
# Sample a batch of transitions from replay buffer:
state, action_, reward, next_state, done = replay_buffer.sample(batch_size)
state = torch.FloatTensor(state).to(device)
action = torch.FloatTensor(action_).to(device)
reward = torch.FloatTensor(reward).reshape((batch_size,1)).to(device)
next_state = torch.FloatTensor(next_state).to(device)
done = torch.FloatTensor(done).reshape((batch_size,1)).to(device)
####################GAN ###################
# Select next action according to target policy:
noise = torch.FloatTensor(action_).data.normal_(0, policy_noise).to(device)
noise = noise.clamp(-noise_clip, noise_clip)
next_action = (self.actor_target(next_state) + noise)
next_action = next_action.clamp(-self.max_action, self.max_action)
exp_state, exp_action = self.expert.sample(batch_size)
exp_state = torch.FloatTensor(exp_state).to(device)
exp_action = torch.FloatTensor(exp_action).to(device)
#######################
# update discriminator
#######################
self.optim_discriminator.zero_grad()
# label tensors
exp_label = torch.full((batch_size, 1), 1, device=device)
policy_label = torch.full((batch_size, 1), 0, device=device)
# with expert transitions
prob_exp = self.discriminator(exp_state, exp_action)
loss = self.loss_fn(prob_exp, exp_label)
# with policy transitions
prob_policy = self.discriminator(state, action.detach())
loss += self.loss_fn(prob_policy, policy_label)
# take gradient step
loss.backward()
self.optim_discriminator.step()
####################GAN ###################
reward = self.discriminator(state, action.detach())
#print(state, action.detach())
# Compute target Q-value:
target_Q = self.critic_target(next_state, next_action)
target_Q = reward + ((1-done) * gamma * target_Q).detach()
# Optimize Critic 1:
current_Q = self.critic(state, action)
loss_Q = F.mse_loss(current_Q, target_Q)
self.critic_optimizer.zero_grad()
loss_Q.backward()
self.critic_optimizer.step()
# Compute actor loss:
actor_loss = -self.critic(state, self.actor(state)).mean()
# Optimize the actor
self.actor_optimizer.zero_grad()
actor_loss.backward()
self.actor_optimizer.step()
for param, target_param in zip(self.actor.parameters(), self.actor_target.parameters()):
target_param.data.copy_((polyak * target_param.data) + ((1 - polyak) * param.data))
for param, target_param in zip(self.critic.parameters(), self.critic_target.parameters()):
target_param.data.copy_((polyak * target_param.data) + ((1 - polyak) * param.data))
def save(self, directory, name):
torch.save(self.actor.state_dict(), '%s/%s_actor.pth' % (directory, name))
torch.save(self.actor_target.state_dict(), '%s/%s_actor_target.pth' % (directory, name))
torch.save(self.critic.state_dict(), '%s/%s_critic.pth' % (directory, name))
torch.save(self.critic_target.state_dict(), '%s/%s_critic_target.pth' % (directory, name))
def load(self, directory, name):
self.actor.load_state_dict(torch.load('%s/%s_actor.pth' % (directory, name), map_location=lambda storage, loc: storage))
self.actor_target.load_state_dict(torch.load('%s/%s_actor_target.pth' % (directory, name), map_location=lambda storage, loc: storage))
self.critic.load_state_dict(torch.load('%s/%s_critic.pth' % (directory, name), map_location=lambda storage, loc: storage))
self.critic_target.load_state_dict(torch.load('%s/%s_critic_target.pth' % (directory, name), map_location=lambda storage, loc: storage))
def load_actor(self, directory, name):
self.actor.load_state_dict(torch.load('%s/%s_actor.pth' % (directory, name), map_location=lambda storage, loc: storage))
self.actor_target.load_state_dict(torch.load('%s/%s_actor_target.pth' % (directory, name), map_location=lambda storage, loc: storage))DDPG 알고리즘을 구현한 클래스다.
-> RL의 한 유형으로서, 연속적인 행동 공간을 다루는 문제에 적합하다. DQN 알고리즘을 기반으로 하며, 정책 신경망(Policy Network)을 사용한다. 정책과 가치 함수를 동시에 학습한다. Actor-Critic 구조를 사용하며, 두 개의 신경망을 사용한다. 또한 경험 재생 메모리를 사용하여 에이전트가 이전 경험을 저장, 재사용하게 한다. 타깃 네트워크를 사용하여 학습 과정을 안정화시키는 기법도 적용된다.
__init__ 메서드는 DDPG 알고리즘에 필요한 모델, 하이퍼파라미터를 초기화한다. select_action 메서드는 주어진 상태를 입력으로 받아, 액터의 행동을 결정한다. update 메서드(아래 세부 설명 참조)는 DDPG 알고리즘의 학습을 수행하는 메서드다. 주어진 replay_buffer에서 배치 데이터를 샘플링하고, 액터와 크리틱 신경망을 업데이트한다. 그리고, GAN 알고리즘에 기반한 판별자 신경망과 손실 함수를 업데이트한다. save 메서드는 학습된 액터, 크리틱 모델을 저장한다. load 메서드는 저장된 액터, 크리틱 모델을 로드한다. load_actor 메서드는 저장된 액터 모델을 로드한다.
-> update 메서드 세부 설명
(1) 배치 데이터 샘플링 : replay_buffer로부터 주어진 batch_size만큼의 배치 데이터를 샘플링한다.
(2) 판별자 신경망 업데이트 : GAN 알고리즘을 사용하여, 업데이트한다. [전문가의 상태-행동 쌍]과 [정책의 상태-행동 쌍]을 사용하여 판별자를 학습한다. 먼저 판별자의 옵티마이저를 초기화, 그다음 전문가 샘플과 정책 샘플을 판별자에 입력하여 출력을 계산. 계산된 출력, 정답 레이블을 사용하여 판별자의 손실을 계산. 역전파를 통해 판별자의 가중치를 업데이트.
(3) 크리틱 신경망 업데이트 : DDPG의 크리틱 신경망 업데이트. 먼저, 타깃 네트워클르 사용하여 다음 상태에 대한 타깃 Q-값을 계산. 현재 상태, 행동에 대한 현재 Q-값을 계산, 그것을 타깃 Q-값과 비교하여 크리틱의 손실을 계산. 계산된 손실을 사용하여 크리틱 신경망의 가중치 업데이트.
(4) 액터 신경망 업데이트 : DDPG의 액터 신경망 업데이트. 액터의 목표는 [크리틱의 Q-값을 최대화하는 정책을 학습하는 것]. 액터의 손실은 [크리틱의 출력에 대한 음수 평균]. 게산된 손실을 사용하여 액터 신경망의 가중치 업데이트.
(5) 타깃 네트워크 업데이트 : Polyak 평균을 사용하여 타깃 네트워크의 가중치를 업데이트. 액터, 크리틱의 타깃 네트워크는 주기적으로 메인 네트워크의 가중치를 업데이트함으로써 학습의 안정성을 향상시킨다.
6. Question
1) GAIL에서 GAN을 사용하는 이유는?
기존의 강화학습에서는 보상 함수를 직접 정의하고 사용했다. GAIL은 보상 함수를 직접 정의하지 않고도 학습할 수 있다. (GAN이 비지도 학습이기 때문) 또한 GAIL에서는 생성자가 정책 신경망이고, 판별자가 Discriminator 신경망이다. 생성자는 전문가의 행동을 모방하려 하고, 판별자는 전문가, 생성자의 행동을 구분하려 한다. GAN을 사용함으로써 더욱 정확한 보상 함수를 계산하고, 보다 우수한 정책을 학습할 수 있다.
2) 보상 함수 구현 부분은?
reward = self.discriminator(state, action.detach())DDPG 클래스의 update 함수 내부에 존재. 주어진 상태와 행동을 이용하여 보상을 계산하는 부분이다. 저 코드에서 state는 현재 상태를, action.detach()는 현재 상태에 대한 액터의 행동을 나타낸다. 그리고 self.discriminator는 GAIL에서 사용되는 판별자 신경망 모델이다. 판별자는 주어진 상태와 행동이 전문가(expert)의 것인지, 정책(policy)의 것인지를 판별하기 위해 사용된다. 판별자는 전문가의 행동에 대해 높은 값을, 정책의 행동에 대해 낮은 값을 가진다. 보상 = 판별자의 출력 = '전문가의 행동'일 확률이다.
-> 이렇게 계산된 'reward'는 DDPG 알고리즘의 크리틱 신경망을 학습하는 데 사용된다.
3) DDPG : 액터, 크리틱에 대해서
DDPG는 Actor-Critic 구조를 사용한다. 2개의 신경망을 사용한다. 액터는 입력 : 상태, 출력 : 행동인 신경망이다. 크리틱은 입력 : 상태와 행동, 출력 : 해당 행동의 가치인 신경망이다.
4) RAGAIL, DGAIL, TD3GAIL의 차이점은?
RAGAIL은 GAIL 알고리즘을 Rainbow 알고리즘과 결합한 형태이다. DGAIL은 GAIL 알고리즘을 분산 학습 환경에서 사용하기 위해 개발된 형태다. (여러 개의 에이전트와 학습 프로세스를 사용 -> 학습 속도 향상시킴) TD3GAIL은 GAIL 알고리즘을 TD3 알고리즘과 결합한 형태이다.
-> TD3은 DDPG 알고리즘의 변형으로, 크리틱 신경망에 대한 타깃 네트워크와 트윈 네트워크를 사용한다. 안정적인 학습을 목표로 한다.
-> 내가 분석한 코드처럼, DDPG와 GAN을 결합한 알고리즘은 DGAIL이다.
7. 알고리즘 요약
이건 내일 ~(논문 참조하기)
8. 코드 구현
(1) 화면 재현 후 python test.py 입력하기
DGAIL -- DDPG.py
test.py
utils.py
expert_traj -- BipedalWalker-v2 -- BipedalWalker-v2_expert_actions.dat
BipedalWalker-v2_expert_states.dat
LunarLanderContinuous-v2 -- LunarLanderContinuous-v2_expert_actions.dat
LunarLanderContinuous-v2_expert_states.dat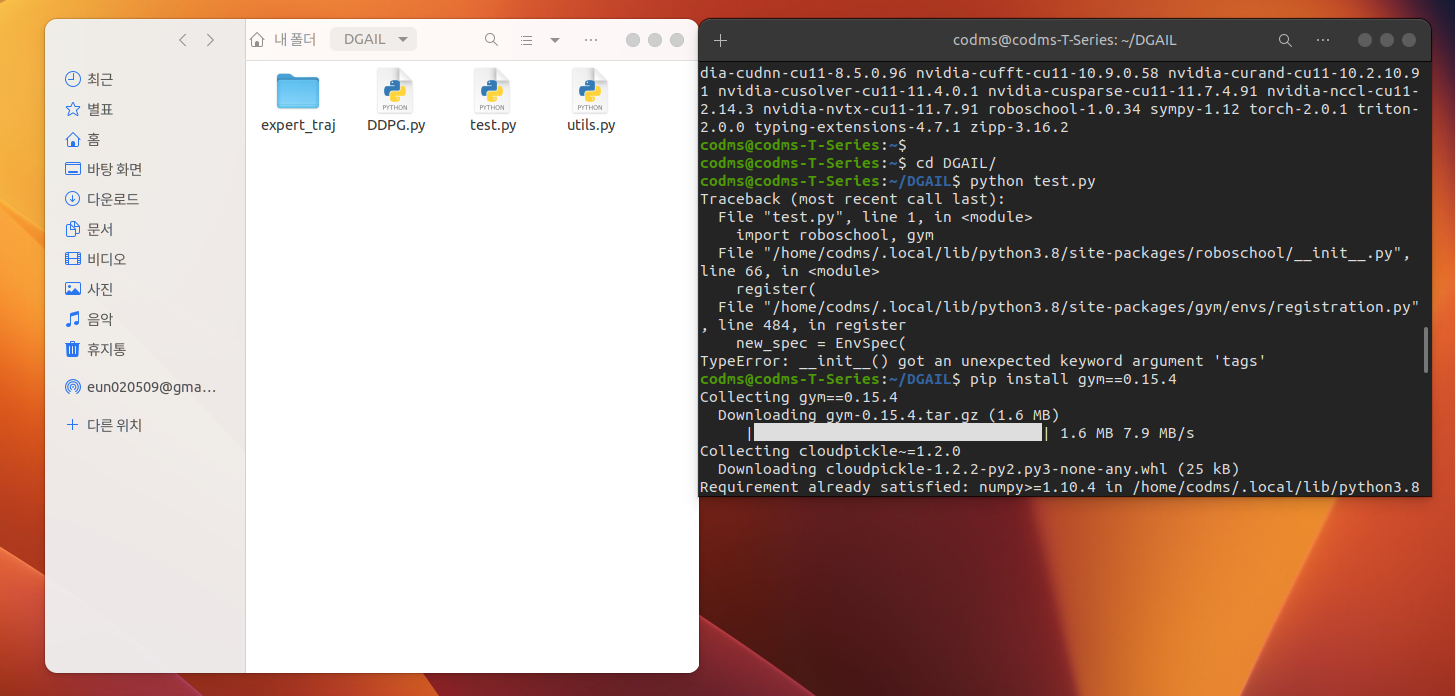
윈도우 폴더 속 내용물 그대로 재현했다.
오류 발생 : TypeError: __init__() got an unexpected keyword argument 'tags'
오류 해결 : pip install gym==0.15.4
(2) 오류 수정 후 python test.py 입력하기
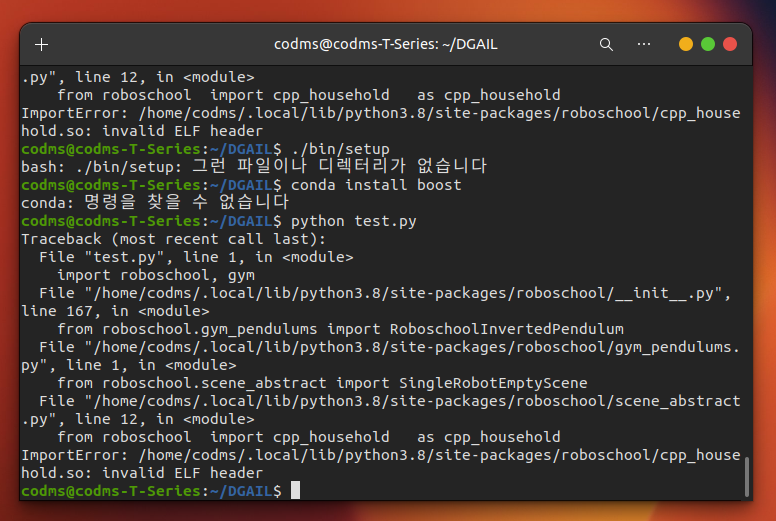
ㅇl야.. 해결이 안 됩니다.
-> 보상함수 구현 부분 찾기?
-> franka emika ROS 구현 코드? (IRL or 걍 간단한 시뮬)->
'LAB > RL, IRL' 카테고리의 다른 글
| 강화학습(3) 코드 실습 : Q-learning, DQN (0) | 2024.01.30 |
|---|---|
| 강화학습(2) DQN, Double DQN, Deuling DQN (1) | 2024.01.30 |
| 강화학습(1) 강화 학습 개념 정리 (1) | 2024.01.29 |
| GAIL (0) | 2023.07.18 |
| 역강화학습(1) 역강화학습 기술 동향 (0) | 2023.06.22 |



