generative model
<generative model의 정의>
주어진 학습 데이터를 학습하여 학습 데이터의 분포를 따르는 유사한 데이터를 생성하는 모델
-> 학습 데이터와 유사한 샘플을 뽑아햐 한다.
-> 학습 데이터의 분포를 어느 정도 안 상태거나(Explicit) 잘 모름에도 생성(Implicit)함
-> 생성 모델에서 가장 중요한 것 : 학습 데이터의 분포를 학습하는 것
<generative model의 목적>
관측값 혹은 data sample x를 알 때,
이런 관측값이 가장 높은 확률로 나올 수 있는 모델 파라미터 θ 혹은 latent vaiable z를 찾는 것
generative model의 분류
큰 범주에서 generative model이 하고자 하는 것은 MLE의 원리를 바탕으로 학습하는 것 !
어떤 식으로 likelihood를 다루느냐(근사를 할 것이냐 or 정확히 나타낼 것이냐)에 따라 유형 분류
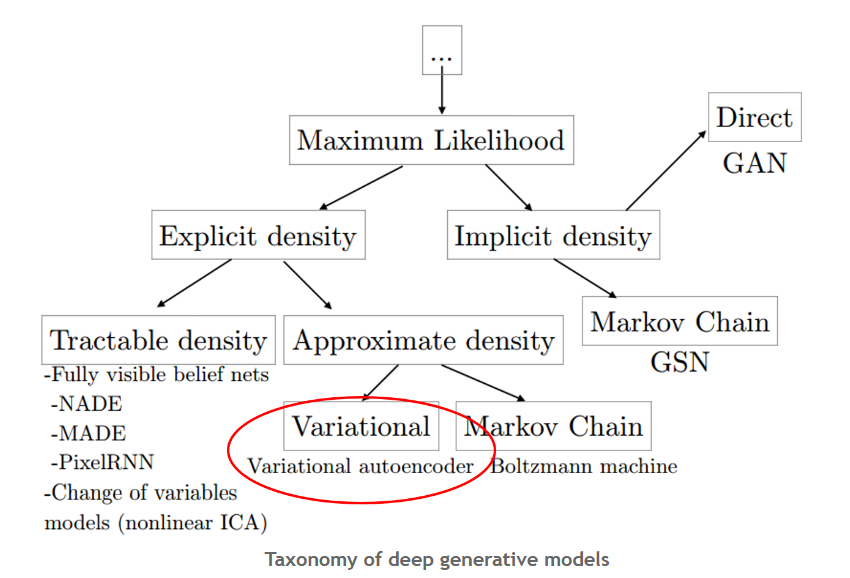
1) Explicit density(명확) : model을 명확히 정의하여 이를 최대화하는 전략
다루기가 비교적 편하고, 모델의 움직임이 예측 가능하다. 그러나 아는 것 이상의 결과를 낼 순 없다.
1) tractable(계산 가능) : 모든 변수를 다룰 수 있어 세밀한 조정 가능, 강력한 제약도 존재
2) intractable(계산 불가능) : density를 근사한다.
Monte Carlo approximations : 무작위로 많은 샘플 뽑아, 분포를 유추
VAE : variational inference(더 deterministic, 예측대로 동작하는 방식)을 사용하여 density를 근사
2) Implicit density(간접) :
1) GSN : model의 확률 분포를 알기 위해 sample을 뽑는 방법 (ex) Markov chain rule
알고있는 or 이미 얻은 sample x와 transition operator q가 주어졌을 때, sample x'를 반복적으로 뽑으면
결국에는 x'이 pmodel(x)로부터 나온 sample로 수렴한다. -> x' ~ q(x'|x)
2) GAN : 어떤 확률 모델을 명확히 정의하지 않아도, 모델 자체가 만드는 분포로부터 sample 생성 가능
MCMC와는 달리 별다른 input이 없어도 한 번에 sample을 생성할 수 있다.
<다양한 유형의 생성모델>

각각 생성모델의 개념과 장단점은 아래와 같다.
1) GAN :
-> 데이터를 생성하는 생성자(generator) 존재
-> 주어진 데이터가 실제 값인지, 생성된 값인지 판별하는 판별자(discriminator) 존재
-> 생성자와 판별자를 동시에 학습시키는 방식, 학습 후에는 생성자를 이용하여 원하는 값 도출
-> 장점 : implicit하게 확률 분포를 모델링하므로 모델 구성에 제한이 없다. 결과물의 품질 good
-> 단점 : 생성자와 판별자가 같이 학습되어야 함, 모드 붕괴 등 학습에 어려움 존재
2) VAE :
-> 오토 인코더의 파생형
-> 인코더 : 입력 값을 특정 확률 분포 상의 한 점으로 만든다.
-> 디코더 : 해당 점으로부터 입력 값ㅇ르 생성
-> 장점 : 명시적인 확률 분포를 모델링한다.
-> 단점 : likelihood(가능도)가 아닌, ELBO를 통한 학습. 품질이 다소 떨어진다.
3) Flow-based models : specialized architectures to construct reversible transform(특수 아키텍쳐 사용)
-> 변환 함수를 파라미터화하여 딥러닝 모델로 학습하는 방식
-> 단순히 확률 분포에서 추출된 값에, 여러 단계의 변환을 거쳐 복잡한 분포를 만듦
-> (ex) 노이즈 데이터에서부터 개/ 고양이 사진 도출
-> 장점 : likelihood를 모델링함, 생성된 결과물의 품질이 좋음
-> 단점 : 변환 함수에 역함수가 존재해야 한다는 제한 존재 -> 모델링 시 연산자에 제한 존재
4) DDPM에 대한 정보는 여기를 클릭
MAP, 최대 사후 확률 추정법
MAP는 양방향을 다 하고싶을 때 사용하는 방식이다.
-> MAP : 데이터와 제일 잘 맞는 추정치를 찾고, 주어진 데이터 기반으로 확률이 최대인 파라미터 찾음
-> MLE 방식만으로는 x를 주고, 여기에 해당하는 latent variable z를 뽑거나 알 수 없다.
-> MAP는 MLE의 리스크를 해결해준다.
MLE가 f(X|𝜽)라면, MAP는 f(𝜽|X)이다.
MAP와 MLE를 구별하기 위해 예시를 사용해보자.
바닥에 떨어진 머리카락의 길이 x를 보고, 그 머리카락이 남자 것인지 여자 것인지 성별 z를 판단하는 문제

-> 특히 인구의 90%가 남자이고, 10%가 여자인 경우 MAP가 더 효과적임을 알 수 있다.
-> MLE와 달리, MAP는 남녀의 성비까지 고려해서 최종 클래스를 결정하므로 좀 더 정확한 모델 파악 가능

** MLE와 MAP는 베이지안의 근간 ! 다음엔 베이지안이 뭔지 해보장 ~
** 딥러닝 : 결국 데이터의 분포에 모델 파라미터를 근사시키는 과정
** 출처 : https://jaejunyoo.blogspot.com/2017/04/auto-encoding-variational-bayes-vae-1.html
초짜 대학원생의 입장에서 이해하는 Auto-Encoding Variational Bayes (VAE) (1)
Machine learning and research topics explained in beginner graduate's terms. 초짜 대학원생의 쉽게 풀어 설명하는 머신러닝
jaejunyoo.blogspot.com
생성 모델의 새로운 흐름 확산 모델(Diffusion model)에 관하여
인공지능 확산(diffusion) 모델 글
blog.est.ai
'LAB > 생성형 AI' 카테고리의 다른 글
| 생성모델(5) conditional generation (0) | 2023.12.28 |
|---|---|
| 생성모델(4) Score-based generative models (2) | 2023.12.28 |
| Diffusion_Toy Simulation code 분석 (0) | 2023.07.12 |
| VAE (0) | 2023.06.22 |
| diffusion model 정리 자료 (0) | 2023.02.22 |



