드디어 코드 분석 시작! 바로 논문 코드를 분석하진 않았고, 쉬운 코드로 먼저 분석했다.
1. Package import & Device setting

딥러닝과 컴퓨터 비전 작업을 위한 다양한 라이브러리와 모듈을 가져오는 역할을 한다. 우선 PyTorch 라이브러리와 그 하위 모듈들을 가져오는 부분이다. 이에는 신경망 모듈('torch.nn'), 컴퓨터 비전 관련 모듈('torchvison'), 초기화 메소드('init'), 일반적인 연산에 대한 함수형 인터페이스('F') 등이 포함된다.
그 외에도 다양한 모듈을 활용한다. math 모듈은 연산을 수행한다. matplotlib.pyplot 모듈은 animation이라는 이름으로 가져오는데, 애니메이션을 생성한다. rotate 함수는 배열의 회전 변환을 수행한다. numpy 모듈을 np라는 이름으로 가져와, 다차원 배열과 수치 계산을 위한 함수를 제공받는다. Dataset와 Dataloader 클래스는 데이터셋을 관리하고 미니배치 학습을 위한 데이터 로딩을 지원한다. transforms는 이미지 전처리를 위한 다양한 변환 함수를 제공한다. HTML은 Jupyter Notebook에서 HTML을 표시하는 기능을 제공한다. clear_output은 Jupyter Notebook에서 출력을 지우는 기능을 제공한다. torch.nn모듈에서 신경망 구축에 사용되는 nn을 가져온다. 'F'라는 이름으로 가져온 모듈은 활성화 함수, 손실 함수 등의 신경망 함수를 제공한다. partial은 다른 함수를 호출할 때 일부 인수를 고정하는 데 사용된다. time 모듈은 시간 관련 작업을 수행한다. datetime 모듈은 날짜와 시간을 제공한다. cv2 모듈은 이미지 및 비디오 처리 작업을 수행한다. glob 모듈은 파일 패턴 매칭을 수행한다. os 모듈은 운영 체제와 상호 작용을 가능케 한다.
-> 컴퓨터 비전이란? 인공지능(AI)의 한 분야로, 컴퓨터와 시스템을 통해 디지털 이미지 , 비디오 및 기타 시각적 입력에서 의미 있는 정보를 추출한 다음, 이러한 정보를 바탕으로 작업을 실행 및 추천하는 것이다.
-> 전처리 과정이란? 이미지를 처리하는 알고리즘에서 효율적으로 활용할 수 있도록 유의미한 정보로 가공하는 과정이다. 본격적으로 알고리즘이 적용되기 전에, 이미지를 구성하고 있는 정보들을 가공하여 데이터를 간략화하여 알고리즘에 필요한 데이터만 남겨둔다. 탐지에 악영향을 주는 부분들을 최소화한다.

CUDA 디바이스 환경 변수를 설정하는 코드이다. 해당 코드는 환경 변수를 '0'으로 설정하여 첫번째 GPU 디바이스를 사용하도록 지정한다. CUDA 사용 프로그램에서 첫 번째 GPU 디바이스에만 액세스하게 된다.
-> CUDA란? NVIDIA에서 개발한 병렬 컴퓨팅 플랫폼, 프로그래밍 모델이다. GPU를 사용하여 고성능 병렬 컴퓨팅 작업을 수행한다. 높은 성능과 빠른 계산이 가능하다.
2. Dataset
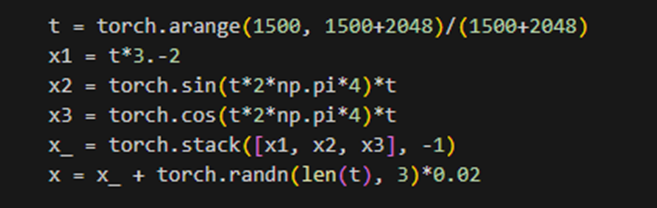
t : 1500부터 3548까지의 숫자를 생성한다. (torch.arange : 범위 내에서 일정 간격으로 정수를 생성하는 함수)
x1, x2, x3를 차원 '-1'을 기준으로 쌓아서 x_를 만든다. x_는 ( lent(t), 3 ) 크기의 텐서로 구성되며, 각 차원은 x1, x2, x3를 나타낸다. x는 x_에 평균이 0이고 표준편차가 0.02인 노이즈를 추가한 결과이다. 주어진 크기의 텐서를 생성한 후 정규 분포에서 무작위 값을 가지도록 샘플링하였다. x는 2048행 3열의 텐서다.
-> x는 노이즈가 있는 데이터로써, 시간에 따라 변하는 신호를 모사하는 용도로 사용될 수 있다.
-> 차원이 '-1'이란? 해당 차원의 크기가 다른 차원들을 기반으로 자동으로 추론되어 설정되는 방식을 의미한다. 예를 들어 크기가 (2, 3, -1)인 텐서가 있다면 '-1'이 사용된 차원은 추론할 크기를 나타낸다. 해당 차원의 크기는 다른 차원들의 크기와 남은 요소의 개수를 고려하여 자동으로 설정된다. 텐서의 크기를 유연하게 조정할 수 있다는 장점을 가진다.


x를 3D 산점도로 시각화한다. 전체 그림의 크기는 (20, 6)이다. 'fig' 객체에 3개의 서브플롯을 추가한다. 131, 132, 133은 각각의 서브플롯을 나타낸다. add_subplot 함수를 사용하여 3D 그래프를 생성한다. scatter 함수를 사용하여 ax0, ax1, ax2에 각각 3D 산점도를 그린다. 각각 x, y. z축의 레이블을 지정한다. 또한 view_init 함수를 사용하여 그래프의 시야를 설정한다. 각각의 서브플롯은 서로 다른 시야로 3D 산점도를 그린다. 즉, 3개의 서브플롯을 추가하였으므로 3개의 산점도가 그려진다. 이들은 형태 동일, 바라보는 각도(시야) 다름.
plot_3d 함수는 x_와 x를 3D 산점도로 시각화한다. x_를 입력으로 받아 3개의 서브플롯을 생성하고, 각 서브플롯에 x_의 데이터를 산점도로 표시한다. 각 서브플롯은 서로 다른 시야로 설정되어 데이터를 다른 각도에서 관찰할 수 있다. 아래의 그림처럼 출력이 될 것이다.

<Data Loader>


주어진 데이터 x에서 num_train 개수만큼의 무작위 인덱스를 선택하여, train_x로 저장한다. 이 코드의 경우, 256개의 훈련 데이터를 선택하도록 지정되어 있다. x가 몇 개든 상관없이, 무작위로 섞인 x에서 처음 256개의 인덱스만을 선택한다. 이렇게 선택된 인덱스는 rand_idx이고, x[rand_idx]가 train_x이다. 따라서 train_x는 x에서 무작위로 선택된 256개의 훈련 데이터로 구성된 텐서이다.

사용자 정의 데이터셋인 CustomDataset을 만드는 클래스이다. xs는 데이터셋에 포함된 입력 데이터로, 256행 3열의 텐서이다. '__init__' 메서드는 xs 인자를 받아서 객체의 xs 속성에 저장한다. '__len__' 메서드는 데이터셋의 샘플 수를 반환하고, '__getitem__' 메서드는 주어진 인덱스 idx에 해당하는 샘플을 반환한다.

CustomDataset 클래스를 사용하여 데이터셋을 생성하고, 이를 DataLoader로 래핑하여 미니배치 학습을 위한 데이터 로딩을 수행하는 과정이다. 256개의 element를 가진 dataset을 입력으로 받고, 미니배치 크기를 64로 지정한다. 'shuffle'을 True로 설정하여 데이터를 섞은 후 로딩하도록 한다. DataLoader를 사용하면 데이터셋을 미니배치 단위로 효율적으로 로딩할 수 있다.
-> 미니배치 학습이란? 전체 데이터셋을 한 번에 모델에 입력하는 대신, 작은 미니배치 단위로 데이터를 나누어 모델을 학습시킨다. 메모리 효율성, 계산 효율성 등등이 향상된다. 또한 확률적 경사 하강법(SGD)과 함께 자주 사용된다.
3. Model
(1) Configurations

주어진 파라미터를 사용하여 텐서 연산을 수행하는 과정이다. torch.linspace 함수를 사용하여 beta_1에서 beta_T까지 T개의 등간격 값을 생성한다. betas는 이를 저장한 것으로, 'T' 길이의 텐서로 구성된다. alphas 역시 'T' 길이의 텐서로 구성된다. torch.linspace 함수를 사용하여 alphas[0]에서 alphas[-1]까지 T개의 등간격 값을 생성한다. 등간격 값의 누적 곱을 수행한 다음 alpha_bars에 저장한다.
참고로 T = 500이다.
(2) Network
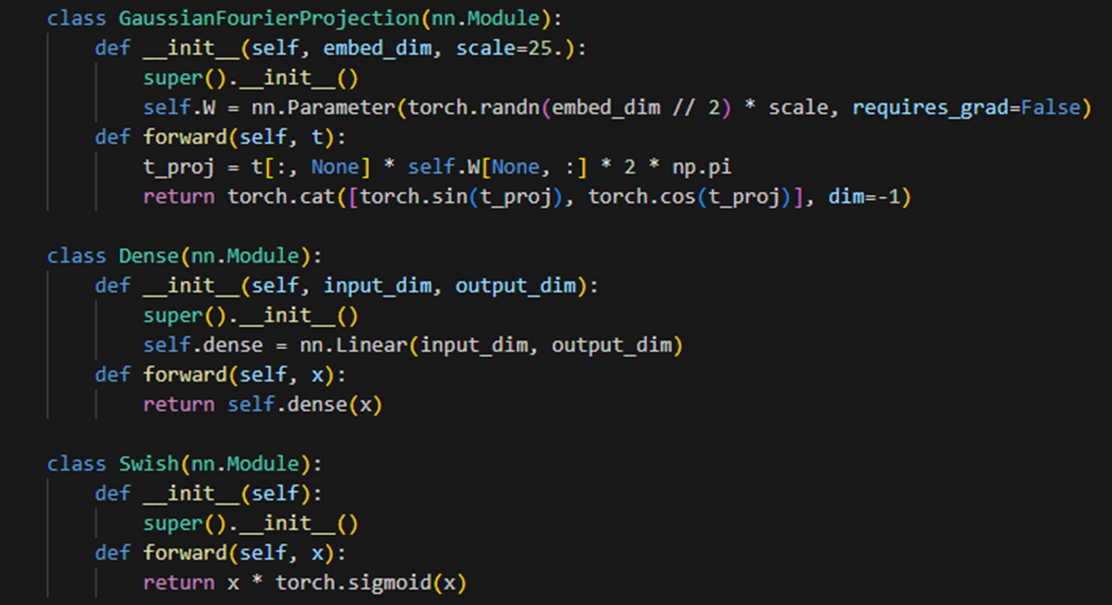
다층 퍼셉트론(MLP) 모델을 정의한다. 첫번째 클래스는 입력된 embed_dim 크기의 가우시안 퓨리에 투영을 수행한다. forward 메서드에서 입력 t를 통해 가우시안 퓨리에 투영을 계산하여 결과를 반환한다. 두번째 클래스는 입력된 input_dim 크기의 피드포워드 신경망 계층을 정의한다. Swish 클래스는 Swish 활성화 함수를 정의한다.
-> 가우시안 퓨리에 투영이란? 입력 신호를 주파수 도메인으로 변환하는 방법 중 하나이다. 차원 축소 기법으로 사용된다. 데이터의 특징을 추출하거나 데이터를 압축하는 데 사용될 수 있다. 가우시안 퓨리에 투영은 기본적으로 가우시안 함수와 삼각 함수의 곱으로 이루어진다. 입력 데이터에 가우시안 함수를 적용하고, 그에 따라 삼각 함수를 사용하여 주파수를 변조한다. 이렇게 변환된 데이터는 저차원의 주파수 공간에서 표현된다.
-> 활성화 함수란? MLP 모델에서 은닉층, 출력층의 출력을 변환하는 비선형 함수다. 모델이 비선형 관계를 학습할 수 있도록 도와준다. Swish 함수는 ReLU와 유사한 형태를 가진다. 참고로 렐루(ReLU) 함수는 입력이 0 미만이면 0을 출력, 0 초과면 입력 값을 그대로 출력한다. 장점 : 데이터의 복잡한 패턴을 학습할 수 있다.


MLP 클래스는 MLP 모델을 정의하는 모듈이다. T, h_channels, embed_dim 등의 인자를 받는다. forward 메서드에서 입력 x, t를 통해 MLP의 출력을 계산한다. MLP는 잔차 경로를 사용하여 입력 데이터와 가우시안 퓨리에 투영된 임베딩을 합산하고, 여러 개의 fully conneted layer를 거친 후 최종 출력을 반환한다.
-> 잔차 경로를 사용? forward 메서드 내부에서 사용되었다. h0, h1, h2, h3 변수들을 통해 보자면, h0는 입력 x를 선형 변환한 결과다. h1은 [h0에 (embed에 대한) 선형 변환 및 활성화 함수를 적용한 결과] + h0 이다. 이와 같은 방식으로 h2, h3까지 잔차 경로를 형성한다. 즉, 각 잔차 경로는 이전 잔차 경로와 이전 층의 출력을 더하여 형성된다. 잔차 경로를 통해 모델이 더 깊은 구조를 가질 수 있으며, 학습이 안정적으로 이루어질 수 있다.
-> 지금 저게 이 코드 특징인가? MLP특징인가?

MLP 모델을 생성하고, CUDA 디바이스로 이동시킨 후, Adam 옵티마이저를 설정하는 과정이다. MLP 클래스를 사용하여 model1 객체를 생성한다. 이때, T는 모델의 초기화에 사용된다. 모델 연산이 GPU에서 수행되도록 설정한 후, Adam 옵티마이저 객체 optim을 생성한다. 주어진 코드에서 optim 객체는 Adam 옵티마이저를 생성하고, 해당 옵티마이저를 사용하여 모델의 가중치를 업데이트하는 데 사용된다.
-> Adam이란? 딥러닝에서 사용되는 최적화 알고리즘으로, 경사 하강법 기반이다. 주어진 학습률에 따라 모델의 가중치를 업데이트하여 손실 함수를 최소화하는 방향으로 학습한다. 학습 과정에서 최적의 학습률을 찾을 필요가 없어 상대적으로 안정적인 학습을 제공한다. 딥러닝 모델의 학습 속도와 성능을 향상시킨다.
-> MLP(T)에서 T란? 모델에서 사용되는 변수로서, 데이터를 처리하는 과정에서 시간적인 흐름을 나타내기 위해 사용된다. 즉, T는 시간 정보를 나타내며, 입력 데이터가 시간에 따라 어떻게 변화하는지를 모델이 학습하게끔 돕는다.
(3) Functions


Loss and Prediction : 손실 함수는 입력으로 output(모델의 출력), epsilon, used_alpha를 받아 손실을 반환한다. MSE, 평균 제곱 오차와 유사한 개념을 가진다. pred_step 함수는 주어진 입력에 대해 모델의 예측을 수행한다. is_train이 True인 경우 학습을, False인 경우 추론을 한다. 마지막으로, model을 사용하여 x_tilde와 idx를 입력으로 받아 output을 계산한다. 참고로 pred_step_fn은 alpha_bars, device를 고정된 값으로 사용하여 인자를 재지정할 필요 없이 pred_step 함수를 사용하게 한다. 간편한 호출이 가능하다.
-> [1] True : 학습과정. alpha_bars에서 임의로 idx를 선택하여 used_alpha를 생성한다. epsilon은 (입력 x와 동일한 크기의) 랜덤 텐서로 생성한다. x_tilde는 used_alpha와 epsilon을 사용하여 계산된다. 출력으로 3가지, (output, epsilon, used_alpha)를 반환한다.
-> [2] False : 추론 과정. idx는 x.size(0)개의 원소를 갖는 텐서이다. x_tilde는 x와 동일하다. 출력으로 output만 반환한다.
-> epsilon은 평균이 0이고, 표준 편차가 1인 노이즈이다. 아니 epsilon = torah.randn_like(x)인데??

Diffusion process : diffusion_process 함수는 주어진 입력 x에 대해 denoising process를 수행하며, 알고리즘적으로는 확산을 사용하여 데이터를 변형시킨다. 그리고 iterator를 반환한다. alpha_bars의 값을 역순으로 반복하면서 가져온다. idx = 0인 경우, 노이즈를 x와 동일한 역행렬로 초기화한다. 그렇지 않을 경우, 노이즈를 표준 정규 분포로부터 생성된 랜덤한 텐서로 설정한다. 각각 변수를 연산한다. predict_epsilon은 pred_step_fn함수를 사용하여 x와 model을 기반으로 예측된 노이즈이다. x는 [mu_theta_xt] + [sqrt_tilde_beta] * [noise]로 업데이트된다. x를 반환하고, 반복문을 다시 돌린다.
sampling함수는 주어진 입력에 대해 확산 과정을 통해 샘플링을 수행한다. 먼저 크기가 [sampling_number, *shape]인 표준 정규 분포로부터 샘플을 생성한다. 그다음 diffusion_step함수를 통해 샘플에 대한 확산 과정을 수행한다. 각 단계에서의 샘플은 sampling_list에 추가되고, 최종 샘플은 final에 저장된다. only_final_out이 True인 경우 최종 샘플만 반환, False인 경우 샘플 리스트 전체를 반환한다. fn이 붙은 함수들은 인자 재지정 방지 및 함수 간편 호출을 목적으로 만들어졌다.
-> DDPM에서 샘플링 과정이 왜 필요한가? 첫째, 데이터 생성에 필요하다. DDPM은 샘플링을 통해 모델이 (학습한 데이터 분포를 따르는) 새로운 데이터를 생성할 수 있다. 둘째, DDPM은 노이즈가 포함된 입력 데이터를 이용하여 원본 데이터를 완성하는 데 사용된다. 샘플링을 통해 노이즈가 점차적으로 제거된 데이터를 얻을 수 있다. 셋째, 샘플링을 통해 모델이 생성하는 각 데이터 포인트의 불확실성을 모델링할 수 있다.
-> 샘플링 과정이란? 데이터의 공간 or 시간적인 특정 지점에서 값을 추출하는 과정을 의미한다. 디지털 시스템에서 신호를 처리하기 위해, 연속적인 아날로그 신호 값을 일정한 간격으로 샘플링하여, 디지털 신호로 변환한다.
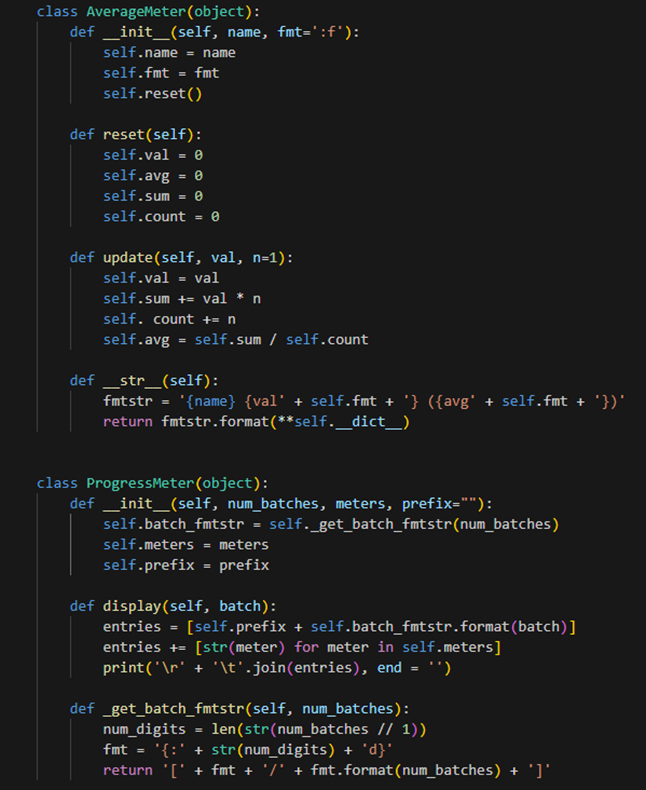
Utils : 학습 진행 상황을 기록하고 출력한다. AverageMeter 클래스는 평균 값을 계산, 출력한다. name, fmt를 인자로 받아 객체를 생성한다. 평균 값을 초기화하는 reset 메서드, 값을 업데이트한 후 그 값을 이용하여 평균 값을 계산하는 update 메서드, 객체를 문자열로 반환하여 출력 형식을 지정하는 __str__ 메서드가 있다.
ProgressMeter 클래스는 학습 진행 상황을 출력한다. num_batches, meters, prefix를 인자로 받아 객체를 생성한다. 학습 진행 상황을 출력하는 display 메서드, 배치 번호를 출력할 때의 형식을 반환하는 _get_batch_fmtstr 메서드가 있다.
이 두 클래스의 객체들을 함꼐 사용하여 학습 속도, 손실 값 등을 모니터링할 수 있다.
(4) Training


Training setting : 학습에 필요한 총 반복 횟수는 40만 번이다. 4만번 주기로 학습 진행 상황을 출력한다. 샘플링에 사용할 샘플 개수는 1024개다. 샘플링 결과로서 최종 출력만 나타낸다.
AverageMeter 객체 losses, ProgressMeter 객체의 progress를 생성한다. losses는 손실 값을 기록하고 출력하기 위한 도구로, 'loss'라는 객체를 생성한다. progress는 학습 진행 상황을 출력하기 위한 도구로 total_iteration 값과 [losses] 리스트를 인자로 전달하여 객체를 생성한다. 학습과정에서 손실 값을 기록하고, 학습 진행 상황을 출력하는 데 사용된다.

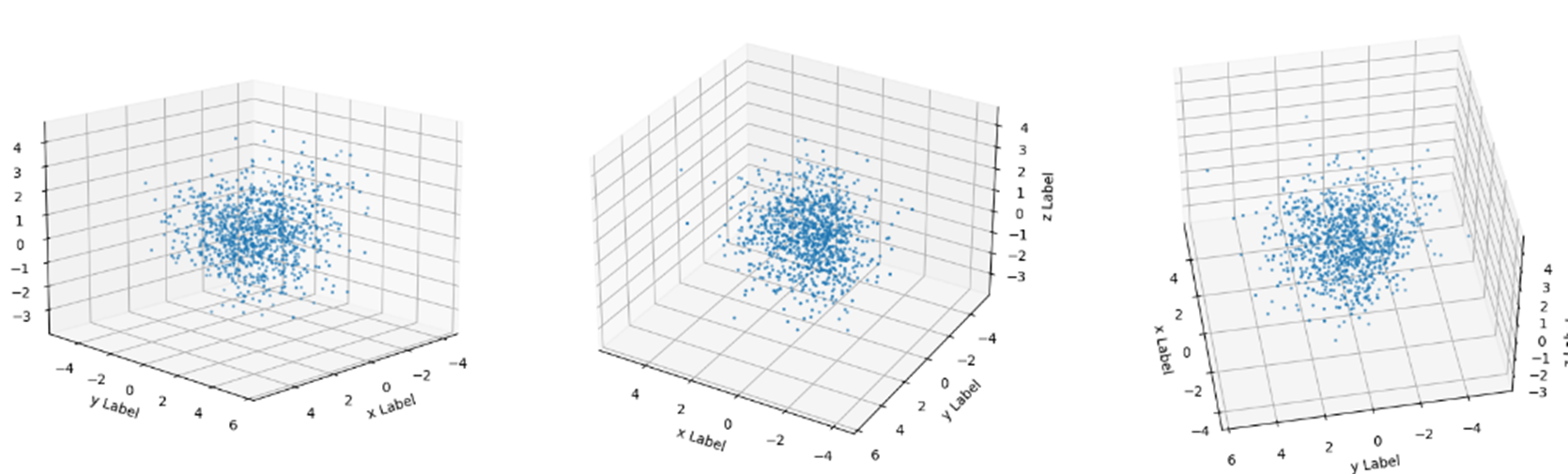
Before : 산점도로 나타낸 모습이다.
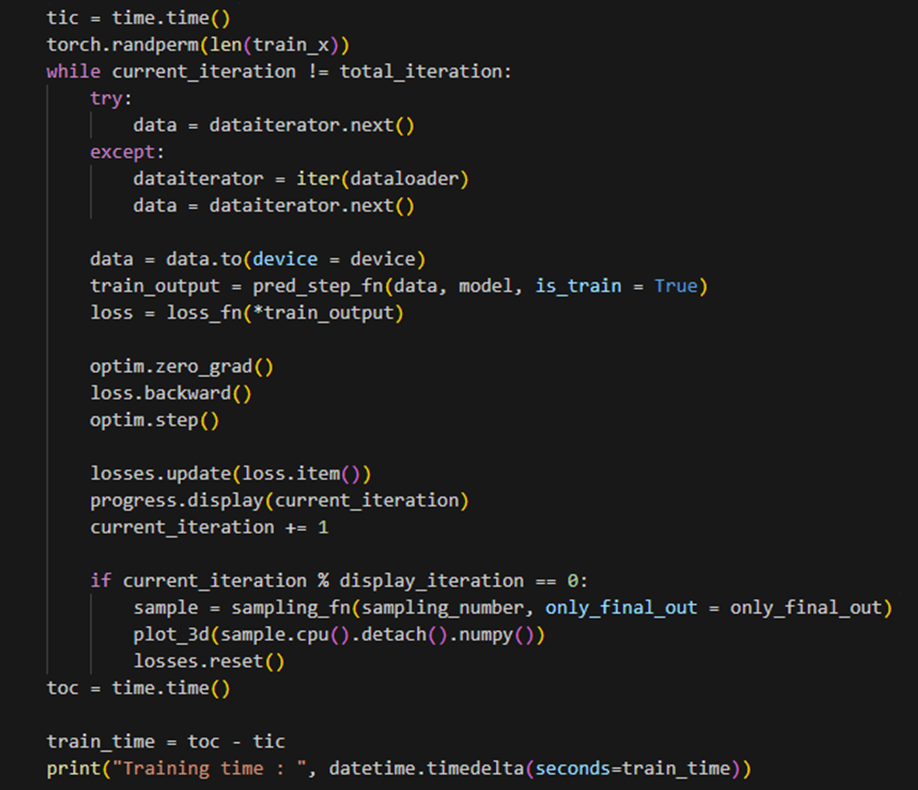
Training : 학습을 진행하는 과정이다. 학습 시간을 기록한다. train_x의 길이에 대한 무작위 순열을 생성한다.
try : data iterator에서 데이터를 가져온다. except : 데이터를 가져오는 과정에서 예외가 발생한 경우, data iterator를 다시 초기화하고 데이터를 가져온다. data를 지정한 디바이스로 이동시키고, pred_step_fn 함수를 호출하여 학습시키고, 예측 결과를 가져온다. 가져온 예측 결과를 loss_fn 함수에 입력하여 손실을 계산한다. 옵티마이저(optim)의 기울기를 초기화한다. 손실에 대한 기울기를 계산한다. 옵티마이저를 사용하여 모델의 매개변수를 업데이트한다. 손실 값을 losses 객체에 업데이트한다. 현재 학습 진행 상황을 출력하고, 총 반복 횟수(40만번)를 채우기 전까지 반복한다. 반복이 끝나면 학습 종료 시간을 기록하여, 학습에 걸린 시간을 계산 및 출력한다.
이러한 과정을 반복하여 총 반복 횟수만큼 학습을 진행하고, 손실 값과 학습 진행 상황을 모니터링하며 결과를 출력한다.


Model load, Model save : 각각은 학습된 모델의 가중치를 저장하는 부분, 저장된 가중치를 불러와서 모델에 적용하는 부분이다.
-> state_dict란? (모델의 매개변수와 버퍼를 포함한) 모델의 상태를 나타내는 딕셔너리다. 이를 저장하면 학습된 가중치를 보존하고, 나중에 불러올 수 있다. 저장된 가중치는 torch.load 함수를 사용하여 불러올 수 있다.
-> load_state_dict란? 모델에 가중치를 적용하는 함수, 이전에 저장한 학습된 모델의 가중치를 재사용할 수 있다.


Result : 3D 산점도 애니메이션을 생성하는 함수인 animate_scatters3d를 정의하는 부분이다. data는 3D 산점도의 데이터를 나타내는 배열로, [반복 횟수, 점 개수, 3]의 크기를 가진다. scatters는 3D 산점도의 점들을 나타내는 객체이다. data 배열을 사용하여 scatters의 점들 위치를 업데이트한다. 반복문을 통해 scatters의 각 점들의 위치를 현재 iteration에 해당하는 데이터로 업데이트한다. 마지막으로, 업데이트된 scatters 객체를 반환한다.
생성된 샘플을 이용하여 3D 산점도 애니메이션을 생성하고, GIF 파일로 저장하는 부분이다. 생성할 샘플의 개수를 2048로 설정한다. 주어진 개수의 샘플을 생성하고, 모든 샘플을 반환하도록 한다. 각각 시간을 기록하여 샘플링에 걸린 시간을 계산, 출력한다. show_sample이란 생성된 샘플 중에서 일부를 선택한 것으로, 이렇게 선택된 샘플을 정렬 순서로 재배열한다. 색상 맵 cmap을 생성할 떄도, show_sample과 동일한 개수의 색상을 생성한다. 3개의 서브플롯을 가진 fig, axs를 생성하고 각 서브플롯의 x, y, z축에 레이블을 설정한다. ax.view_init로 시야각을 설정한 다음 FuncAnimation 함수를 사용하여 3D 산점도 애니메이션을 생성한다. GIF 파일을 생성하기 위한 PiIlowWriter 객체를 생성한 후, 애니메이션을 'ddpm_toy.gif'라는 GIF 파일로 저장한다.
-> scatters를 리턴한다는 것은? scatters는 산점도 그래프에서 점을 나타내는 객체다. 각 반복(iteration)에서 점의 위치를 업데이터하여 애니메이션을 효과적으로 구현한다. 점을 출력한다는 의미로 보면 된다.
<추가 질문>
-> 여기 DDIM이 쓰였나? DDIM(Denoising Diffusion Implicit Models)에 대한 구현이 포함되어 있지 않다.
-> iterator란? 컬렉션(리스트, 튜플 등)을 반복할 수 있는 객체를 의미한다.
-> ㅇ
'LAB > 생성형 AI' 카테고리의 다른 글
| 생성모델(5) conditional generation (0) | 2023.12.28 |
|---|---|
| 생성모델(4) Score-based generative models (2) | 2023.12.28 |
| Generative Model(생성모델) (0) | 2023.06.22 |
| VAE (0) | 2023.06.22 |
| diffusion model 정리 자료 (0) | 2023.02.22 |



