1. 강화학습
(1) 강화학습이란?
강화학습은 기계학습의 한 분야다. 보상을 통해 학습하는 알고리즘이다. 다른 기계학습과 다르게 경우의 수가 많고, 정답이 하나가 아니다. 또한 강화학습에서 '보상'이란 행동의 좋고 나쁜 정도를 나타내는 지표다.
[1] 환경 : 강화학습을 통해 해결하고자 하는 문제, [2] 에이전트 : 행동을 결정하는 주체, [3] 상태 : 환경을 표현하는 정보, [4] 행동 : 에이전트와 환경 사이의 상호작용, [5] 보상 : 행동의 가치를 나타내는 값이다.
강화학습의 학습 과정은 다음과 같다. 에이전트가 상태를 입력받는다. 에이전트가 상태에 따라 특정 행동을 수행한다. 그 행동에 따라 환경이 변한다. 에이전트가 행동 가치에 따라 보상을 받는다. 보상을 보고 행동이 좋은지, 나쁜지를 배운다. 에이전트가 해야 하는 행동을 학습한다. 새로운 상태를 입력받고 해당 과정을 반복한다.
리턴은 현 시점부터 에피소드가 끝나는 시점까지 누적된 보상의 합이고, 정책(policy)은 주어진 상태에 따라 행동을 선택하는 규칙이다. 강화학습의 목표는 리턴을 최대화하는 정책을 학습하는 것이다.
(2) MDP
MDP(Markov Decision Process)란 미래 상태는 현재의 상태에만 영향을 받는다 ! 과거의 상태와는 독립적이다 ! 의 특성을 갖는다.
상태, 행동, 보상 함수, 상태 전이 확률(P), 감가율(γ)로 구성된다. [1] 상태 : 확률 변수이며, 다음 상태 St+1은 이전 상태 St와 행동 At에만 영향을 받는다. [2] 행동 : 확률 변수이며, 이산 행동과 연속 행동으로 나뉜다. 이산 행동은 정해진 행동 집합 내에서 선택하는 경우며, 연속 행동은 선택지가 무수히 많은 경우를 의미한다. [3] 보상 : 에이전트가 취한 행동에 대한 환경의 피드백이라 할 수 있다. [4] 상태 전이 확률(P) : 상태 s에서 행동 a를 할 때 다음 상태 s'가 될 확률을 의미한다. 실생활에서 예를 들자면, 네비게이션이 우회전(다음 상태)을 가리켜도 내 차가 고장나 있다면 상태 전이 확률은 0인 것이다. 이처럼 환경에 의해 행동 a를 선택해도 s'로 바뀌지 않는 경우가 존재한다. [5] 감가율(γ) : 미래의 보상을 감가하는 비율이다. 시간이 무한대일 때 감가율이 없으면, 보상의 총합인 리턴값은 발산하게 된다. 이를 방지하고자, 리턴 값 수렴을 위해 감가율이 필요하다.
(3) 가치함수
리턴 값은 에피소드가 끝날 때까지는 구할 수 없다. 그러나 기댓값 개념을 적용하여 에피소드 중간에도 리턴 값을 추정할 수 있다.
가치함수란 현재 상태에서 기대되는 return 값이다. 가치함수는 크게 두 가지로 나뉜다. [1] 상태 가치 함수(V) : 현재 상태에서 기대되는 return 값이다. s 넣어서 return 값을 반환한다. [2] 상태-행동 가치 함수(Q) : 현재 상태에서 특정 행동을 선택했을 때 기대되는 return 값이다. s, a를 넣어서 return 값을 반환한다.

위는 가치 함수와 Q함수의 상관 관계식이다. 동일 시간 t에서의 가치 함수는 각 행동에 대한 Q 함수와 각 행동을 선택할 확률을 곱한 값들에 적분한 것과 동일하다. (이산 공간일 때는 다 더한 것과 동일하다.)
(4) 다이나믹 프로그래밍과 벨만 방정식
벨만 기대 방정식이란 가치 함수를 계산 가능하게 만들기 위한 방정식이다. 효율적인 기댓값 연산이 가능하다. 여기서 기댓값이란 각 사건과 사건이 일어날 확률읙 곱들의 총합이다. 벨만 최적 방정식은 최적 가치 함수와 최적 정책 식이 있다. [1] 최적 가치 함수는 최적 정책을 사용하는 가치함수다. [2] 최적 정책은 최대의 Q함수를 통해 결정된다.
다이나믹 프로그래밍이란 순차적 행동 문제를 푸는 알고리즘으로, 전체의 큰 문제를 작은 문제로 쪼개서 푸는 방식이다. 재귀함수 프로그래밍과 비슷한 원리다.
2. Monte Carlo 및 Temporal Difference
(1) 탐험과 활용
최대 보상만을 쫒는 greedy-policy는 편향된 결과를 초래할 수 있다. 탐험과 활용의 tradeoff가 적절히 이뤄져야 한다. [1] 탐험(Exploreation) : 랜덤한 선택을 통해 refresh를 주는 정책이다. [2] 활용(Exploritation) : 높은 보상을 추구하는 탐욕 정책을 따르는 방식이다. 아래는 Epsilon-greedy 정책이다. (1 - ε)의 확률로 최대 큐 합수를 선택, (ε)의 확률로 랜덤 선택을 한다.
(2) Monte Carlo 알고리즘
샘플링 평균을 통해 가치함수와 정책을 업데이트하는 방식이다. 마지막 에피소드까지 진행한 후, 누적된 return 값의 평균을 통해 가치 함수를 추정한다. 즉, 한 에피소드마다 업데이트되는 방식이다. 편향은 낮지만, 분산이 높다는 단점이 있다. 즉 overfitting 문제가 있다.
(3) TD 알고리즘
이전 정책으로 예측한 가치 함수를 토대로 다음 스텝의 가치 함수를 예측하는 부트스트랩 방식이다. 상태를 받아 행동을 취하고, 보상을 받는 매 timestep마다 예측을 진행한다. 즉, 매 스텝마다 업데이트된다. 실시간으로 가치함수가 업데이트된다. 초기 가치 함수가 중요한 역할을 한다.
SARSA 알고리즘의 업데이트 요소는 [St, At, Rt, St+1, At+1]이다. 다음 상태 뿐만 아니라, 다음 행동까지 고려하기 때문에 Q함수로 표현된다. 시간차 에러값을 TD error라고 한다.
3. Q-learning
(1) Model-free, Model-based
[1] Model-free 방식이란 환경이 어떻게 동작되는지 모르는 상태에서, 학습된 데이터를 통해 행동을 선택하고 환경으로부터 다음 상태와 보상을 얻는 방식이다. [2] Model-based 방식은 에이전트가 행동하는 모델에 대한 정의가 되어 있는 상태에서 학습을 진행한다.
(2) Model-free RL
[1] Value-based : 가치 함수만 학습하고, 정책은 암묵적으로 갖는 방식이다. 주로 이산 행동 집합일 때 많이 사용한다. [2] Policy-based : 가치 함수를 업데이트하지 않고 정책만을 업데이트한다. 정책을 직접 최적화하기 때문에 안정적인 학습이 가능하다. 연속 행동 집합일 때 많이 사용한다. [3] Actor-based : 정책과 가치 함수를 모두 업데이트한다.
(3) On-policy, Off-policy
[1] On-policy : 행동 정책과 타겟 정책이 같다. agent가 선택한 행동에 의해 기대되는 반환값으로 Q함수를 업데이트한다. 즉, agent가 선택한 행동이 정책에 바로 반영된다. 직접 경험을 토대로 선택된다. SARSA 알고리즘이 여기에 해당한다. [2] Off-policy : 행동 정책과 타겟 정책이 다르다. agent가 다음 상태에서 최적 정책을 통해 얻을 수 있는 반환값으로 Q함수를 업데이트한다. expert data과 같은 간접 경험을 토대로 선택된다. Q-learning 알고리즘이 여기에 해당한다.
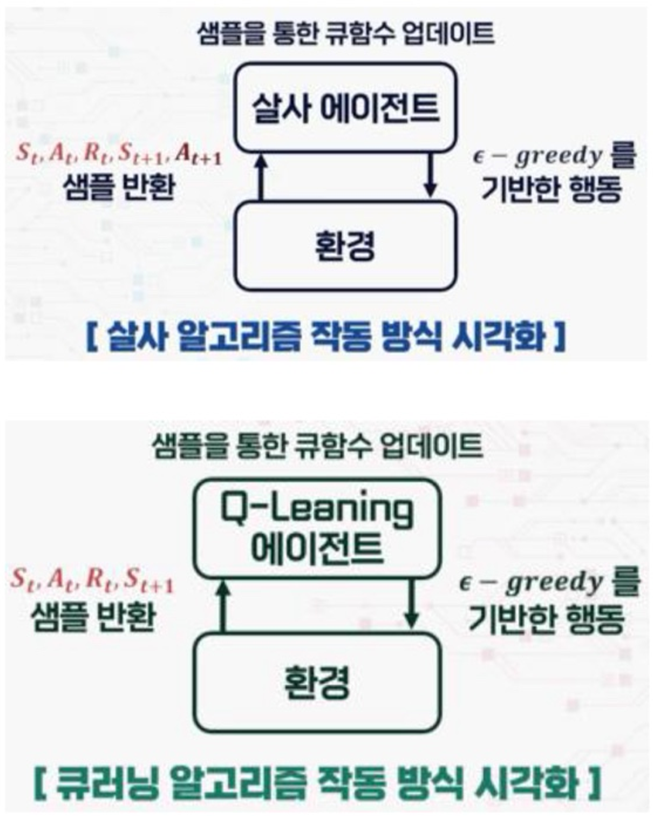

(4) Q-learning

4. RL AlGORITHM
(*) 강화학습 알고리즘 중에서 DQN, A2C, PPO를 위주로 간략하게 !! 살펴볼 것입니다.
그리고 최종적으로 TD3도 !!!!! 할 예정입니다.
(1) DQN
Off-policy 알고리즘은 간접 경험을 통해 나의 잘못된 학습으로 치우쳐진 결과에 도달하는 것을 막아준다. DQN은 Q-table을 딥러닝 방식으로 대체한 알고리즘이다. 상태와 행동에 따른 Q값을 업데이트할 때 Q값의 파라미터를 업데이트하는 식으로 학습이 진행된다.
강화학습에 딥러닝을 적용할 시의 문제점은 크게 4가지다. [1] 데이터 지연 문제 : 강화학습은 일련의 과정 후에 레이블이 지정되기 때문에 지연이 된다. 즉 보상이 바로 주어지지 않는다. [2] 데이터 Correlation : 딥러닝에선 편향되면 안되므로 무작위 데이터 추출을 한다. 그러나 강화학습의 경우 시간 순대로 데이터 수집 시 데이터 간의 높은 상관관계를 유발한다. [3] 데이터 분포 문제 : 딥러닝 학습 시에는 데이터 분포가 변하지 않지만, 강화학습 과정에서는 Q값이 계속해서 변한다. 즉 데이터의 분포가 변한다. [4] Target value가 움직임. 타겟을 뽑는 네트워크도 변동이 되므로 학습의 안정성이 떨어진다.
DQN은 두 가지 해결 방안을 제시한다. [1] Experience Replay 기법 사용 : 경험을 리플레이 버퍼에 저장한다. 학습은 미니배치 단위로 한다. 리플레이 버퍼에서 학습에 사용할 데이터를 랜덤으로 추출한다. [2]의 문제를 해결한다. [2] Q-network와 Target-network를 분리 : 메인 Q-network는 현재 행동에 대한 Q값을 얻는 데 사용된다. Target-network는 타겟 값을 얻는 데에 이용된다. 이러면 [4]의 문제를 해결할 수 있다.
식 사진 첨부하자 ~ 블록도 첨부 ~.
(2) A2C
내용
(3) PPO
내용
5. ㅇㅇ
내용
출처1 : k-mooc '한양대 강화학습'
출처2 : 강화학습 이론&실습 : 기초 수학부터 강화학습 알고리즘까지 (황현석 지음)
'LAB > RL, IRL' 카테고리의 다른 글
| 강화학습(8) GAIL 실행하기 (LINUX) (1) | 2024.02.01 |
|---|---|
| 강화학습(5) PPO, DDPG, TD3, and so on.. (0) | 2024.01.30 |
| 강화학습(4) Actor-critic, A2C, A3C, SAC (0) | 2024.01.30 |
| 강화학습(3) 코드 실습 : Q-learning, DQN (0) | 2024.01.30 |
| 강화학습(2) DQN, Double DQN, Deuling DQN (1) | 2024.01.30 |



