1. Introduction to memory hierarchy
(1) Review
Five classsic components of a computer는 아래와 같은 구조를 지닌다. Input, Output, Memory, Datapath, Control의 5가지 구성요소를 가진다. 참고로 Memory에는 [1] 실행되는 programs, [2] 프로그램 실행에 필요한 data가 보관된 저장 영역이다. 또한 Datapath와 Control을 합쳐서 Processor라고 부른다.

(2) Locality
도서관을 예시로 들어보자. 영희가 도서관에서 책을 찾아가며 보고서를 쓸 때, 몇 권의 책을 가져왔다면 영희는 그 책들을 다시 볼 가능성이 높다. (temporal locality) 또한 해당 주제와 관련된 책꽂이가 있다면 영희가 뽑은 책 외에도 주변의 책들이 주제와 관련된 책일 가능성이 높다. (spatial locality) 즉, 자신이 고른 책은 또다시 고를 확률이 높아지고, 자신이 고른 책 주변의 책들도 선택될 확률이 높아진다.
[1] Temporaal locality란 어떤 data item이 참조(reference)된다면 그 item은 다시 참조될 가능성이 높음을 의미한다. 예를 들어 프로그램에서 loops에 존재하는 명령어들은 반복적으로 실행된다. [2] Spatial locality란 어떤 data item이 참조된다면 그 item 주변의 item들이 곧 참조될 가능성이 높다. 예를 들어, 명령어는 보통 sequential하게 access된다. 또한 data array에 존재하는 elements에 대한 참조의 경우도 있다.
Memory hierarchy는 기본적으로 locality라는 원리를 이용하여 구축된 것이다. 아래 그림처럼 여러 level의 memory들로 구성된 구조를 memory hierarchy라고 한다. 이는 unlimited fast memory가 존재하는 듯한 착각을 만들어준다.

(3) Memory Hierarchy Terminology
통상적인 Memory hierarchy는 아래와 같다.
| Speed | Size | Cost ($/bit) | Current technology |
| Fastest (0.5-2.5ns) | Smallest | Highest | SRAM |
| (50-70ns) | DRAM | ||
| Slowest (5,000,000-20,000,000ns) | Biggest | Lowest | Magnetic disk |
Samll, fast, expensive memory와 large, slow, cheap memory를 사용하여 large, fast memroy를 가지고 있는 효과를 내기 위해 구성되었다.
[1] Block이란 Memory hierarchy의 각 level에 존재하는 data의 최소 단위를 의미하며, line이라고도 한다. Memory hierarchy에서 data는 인접한 levels 사이에서만 upper level의 Block 단위를 최소 단위로 복사된다. Block의 크기는 level에 따라 다르다. 또한 한 block에 속하는 data들은 전체가 모두 특정 level에 존재하거나, 존재하지 않거나 둘 중 하나다. 한 쪽 level에만 존재하는 경우는 없다. 또한 한 block에서 block address는 동일하다.
[2] upper level은 lower level의 subset이며, 이것을 memory hierarchy의 inclusion property라고 한다. level i에 존재하는 모든 data는 level i+1에도 존재하며, 결론적으로 lowest level에는 전체 data가 존재한다.
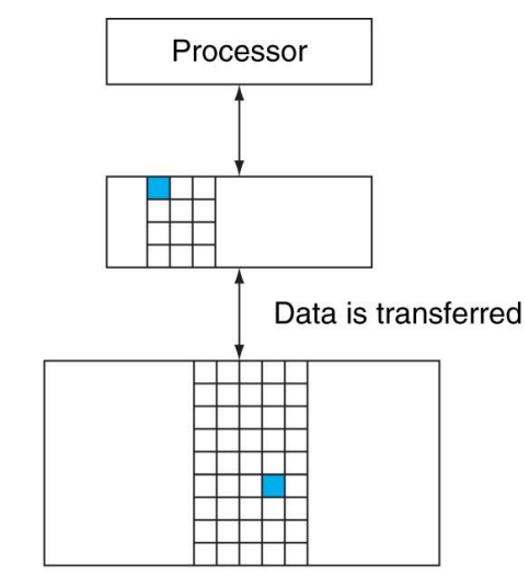
[3] Processor가 요청한 data가 upper level의 block 안에 있으면, 그것을 hit라고 한다. Memory accesses 중 hit인 accesss의 비율을 hit rate이라고 한다. 반대로 요청한 data가 upper level에 존재하지 않으면, 그것을 miss라고 한다. miss rate = 1 - hit rate이다.
[4] hit time은 upper level에서 hit가 난 data access에 소요되는 시간을 말하며, hit/miss 판별 시간까지 포함하여 계산한다. Miss penalty란 data access가 miss인 경우 추가적으로 소요되는 시간을 의미한다. miss가 나면 miss penalty를 부여한 다음 계속 lowet로 내려가서 요청한 data를 포함하는 block을 찾는다. 찾은 후 upper level의 block에 저장하고, 해당 datat를 processor로 전달한다. miss penalty = data access time - hit time이다. hit rate가 높으면, 높은 성능을 보일 것이다.
2. Cache
(1) Cache
Cache란 Processor와 main memory 사이의 memory hierarchy level로, 높은 속도를 보이는 메모리다. 넓은 의미로는 Locality를 이용하기 위한 any storage로 보면 된다.
아래는 간단한 cache의 예시다. (a) -> cache 발생 -> lower level(DRAM)으로 내려감 -> (b) cache에 Xn을 저장 -> 이 후 Xn access 시 hit가 됨, 의 순서를 가진다.

(2) Direct-mapped cache
Data item을 cache의 어느 block에 위치시키느냐에 따라 cache를 분류한다. Direct-mapped caches, set-accociative caches, fully-associative caches로 분류된다. Direct-mapped cache에서 각 data item은 cache의 특정 한 위치에만 존재할 수 있다. data item이 존재하는지 알기 위해선 그 영역만 확인하면 되므로 hit/miss를 판단하기 쉽다. cache의 word(block) 수가 2k라면, 할당된 cache index는 word address 중 하위 k bits다.
예를 들어, 8-entry(block) direct-mapped cache를 보자. Cache block의 수가 8=2의 3승이므로, word address 중 하위 3bits가 cache index로 사용된다.
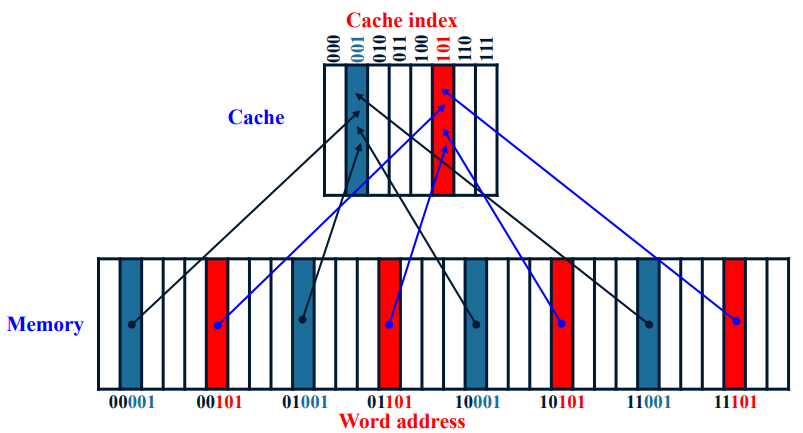
위의 그림에서 001이 00001인지, 01001인지, 10001인지, 11001에서 온 건지 어떻게 알까? 각 block에 존재하는 data가 어떤 것인지를 정확히 구분하기 위해서 tag라는 address information이 존재한다. tag는 해당 block이 존재하는 data의 word address 중 index로 사용되고 남은 bit들을 저장하고 있다. 예를 들어 word address 10001 중 001이 cache index라면, 나머지 10이 tag가 된다. 또한 Valid bit란 해당 block에 존재하는 data가 유효한 지 아렬주는 bit이고, block 수만큼 존재한다.
Data를 access할 때, cache에서는 [1] Cache hit, [2] Cache miss without block replacement, [3] Cache miss with block replacement 중 한 가지 동작이 이루어진다. [2]는 valid bit가 0인 경우여서, 원하는 data를 가져와 cache block에 저장하고 tag와 valid bit 값들을 조정하면 된다. [3]은 valid bit가 1이지만 tag가 data의 word address의 것과 불일치하므로 원하는 data와 이미 존재하던 data를 바꿔서 저장하면 된다.
(3) Block size
지금까지는 cache의 block size가 word라고 가정했다. data request가 word 단위로 이루어졌으므로, spatial locality를 사용하지 못한 셈이다. 물론 byte, halfword 단위의 data request 덕에 조금은 이용 가능했다. spatial locality를 이용하려면, Block size를 word보다 크게 해야 한다. 그리고 나서 특정 block에 속하는 data refenrece가 cache miss가 날 경우, memory에서 그 data가 속한 block 전체를 cache로 복사하여 spatial locality를 이용하면 된다.
block address는 아래의 공식으로 정의할 수 있다. block address가 같은 data들이 모여 하나의 block을 형성한다.

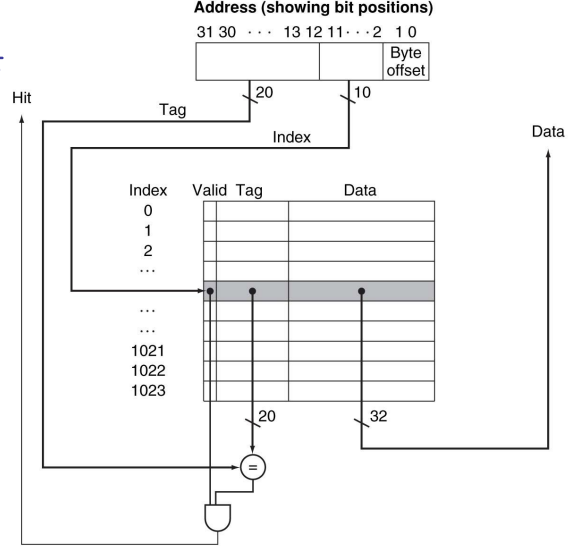
cache의 block size에 상관없이 항상 cache index가 cache의 block을 지정한다. cache의 block 수가 2k라면, 할당된 cache index는 block address 중 하위 k bits다. 예를 들어, block size가 8(=23)bytes(2words)이고 cache block 수가 16(=24)개인 경우, byte address = 1010010100인 data의 block address는 1010010이고, cache index = 0010, tag = 101, Byte offset = 100이다.
즉, Memory address(=byte address)는 cache과 관련하여 다음과 같이 3개의 fields로 나뉜다.

[1] Index는 할당되는 cache index를 지정하는데 사용되며, block의 개수에 의해 결정된다. [2] Tag는 Block address중 index를 제외한 bits에 해당되며, 같은 cache block에 할당된 memory block들을 구분하기 위해 사용된다. [3] Offset은 cache 내에서 원하는 block을 찾은 후 그 block의 data 중 원하는 data를 지정하는데 사용되며, block size에 의해 결정된다.

(4) Handling Cache miss
우리가 이전 강의에서 다룬 processor의 datapath에 존재하는 memory(instruction memory, data memory)는 cache들로 대체된다. 즉 Instruction cache, data cache가 된다. cache access가 hit인 경우엔 이전의 memory access와 비슷하게 동작한다. 그러나 cache miss가 발생할 수 있기에, 이에 대한 control이 필요하다. cache miss에 대한 control은 main control에 추가하는 것이 아닌, cache control리하는 별도의 ctrl unit을 사용하여 제어한다. 즉, hit/miss detect를 포함하여 cache operations를 담당하는 별도의 cache control이 존재한다.
Cache miss가 발생하면, 일반적으로 [1] Stall the pipeline, [2] miss가 난 block의 data를 main memory로부터 읽어서 cache에 write(한 block의 data를 모두 읽어와야 함), [3] memory address의 상위 bits를 사용하여 해당 cache block의 tag를 update, [4] 해당 cache block의 valid bit를 update, [5] processor가 memory(cache) access를 다시 시작하면서, pipeline이 다시 동작하도록 한다.
실제 cache에서 이루어지는 세부 동작은 여러 가지 policies에 따라 달라지며, write 시의 동작은 cache의 write policy에 따라 달라진다. Wirte policy는 2가지로 분류된다. [1] Write-through는 write data를 cache의 block과 lower-level memory의 block에 모두 write한다. cache과 lower-level memory가 일관되며, 비교적 cache 제어가 간단하다는 장점을 가진다. 한편 write가 오래 걸리며, 이로 인해 pipeline stall을 발생시킨다는 단점을 가지지만, write buffer를 통해 이를 해결할 수 있다. write buffer란 memory에 write할 data를 가지고 있는 data queue다. write buffer에 write data과 address를 쓰고 종료하는 process와 독립적으로, write buffer는 저장되어 있는 data를 memory에 write한다. 또한 pipeline stall을 피가히 위해 여러 개의 data entries를 가진다. [2] Write-back이란 write data를 cache의 block으로만 write하는 것이다. 내용이 변경된 cache block은 replace될 때에 lower-level memory로 write된다. Low bus utilization, Fast writes라는 장점을 가지는 반면에 Cache와 lower-level memory가 일관되지 않으며 cache 제어가 복잡하다는 단점을 가진다. write-back buffer는 cache miss penalty를 줄이기 위한 것으로, replace되는 block의 data를 저장하는 데 사용된다.
(5) Cache Performance
CPU time 측정을 2가지 성분으로 나눌 수 있다. [1] CPU execution clock cycles는 CPU가 program을 execution하는데 소요되는 clock cycles를 의미하며, hit에 대한 cache access에 소요되는 clock cycles로 포함한다. [2] Memory-stall clock cycles란 CPU가 memory system의 동작 완료를 기다리는데 소요되는 cycles이며, cache miss 때문에 발생한다.

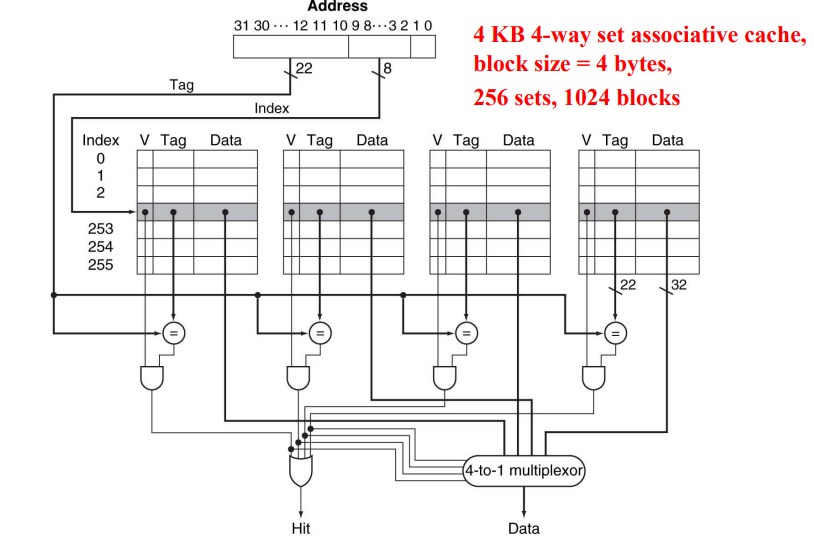
(6) Set-associative cache
Cache miss의 유형은 크게 3가지로 분류된다. [1] Compulsory misses란 특정 block을 처음으로 access할 때 발생하는 misses다. 이는 피할 수 없는 miss로 Cold start misses 또는 first reference misses라고도 한다. [2] Capacity misses란 cache가 program execution 동안 필요한 모든 block들을 저장할 수 없는 경우에 발생하는 misses다. 즉, cache의 크기 또는 용량 제한으로 인해 발생한다. 이는 cache size를 크게 함으로써 줄일 수 있다. [3] Conflict misses란 다른 block들이 비어있음에도 서로 같은 곳의 자리를 차지하려 해서 발생하는 misses다. Collision misses 또는 interference misses라고도 하며, Direct-mapped caches에서 가장 큰 문제가 된다. [3] 을 해결하기 위해서 cache size를 늘리는 비효율적인 방법도 존재하지만, 하나의 block이 mapping될 수 있는 cache block의 위치가 1개가 아닌 여러 개로 두는 방법도 존재한다.
Block Placement Policy란 앞서 말한 방법들 중 후자의 방법이다. [1] Direct-mapped는 각 data block이 mapping될 수 있는 cache block의 위치가 유일하다. way 수가 1개인 set-associative cache로 볼 수 있다. [2] Fully-associative는 data block이 mapping할 수 있는 cache block 위치가 정해져 있지 않다. 즉, 어디에든 위치할 수 있다 .Offset과 Tag만 있고, Index field는 존재하지 않는다. No conflict miss라는 장점을 가지지만, 많은 comparator가 요구되므로 현실적으로 block 수가 작은 cache에서만 사용 가능하다. set 수가 1개인 set-associative cache로 볼 수 있다. [3] Set-associative란 data block이 mapping할 수 있는 cache block의 위치가 2개 이상인 경우다. N개일 때, N-way set associative cache라고 한다. 단일 data block이 위치할 수 있는 cache blocks를 set이라 하며, 각 set은 N개의 blocks로 구정된다.

Set-associative 방법에 대해 더 자세히 알아보자. 이는 3개의 field로 나뉘며, [1] Index는 할당되는 cache set을 지정하는데 사용된다. (block이 아니라) set의 개수에 따라 결정된다. [2] Tag는 특정 cache block으로 할당될 수 있는 memory block들을 구분하기 위해 사용되며, block address 중 index를 제외한 bits에 해당한다. 대응하는 cache set에 있는 N개의 tags와 memory address의 tag를 서로 비교한다. [3] Offset은 cache 내에서 원하는 block을 찾은 후 그 block의 data 중 원하는 data를 지정하는데 사용되며, 전체 memory address 중에서 block address를 제외한 나머지 bits에 해당된다.
Cache size, block size, blocks, sets의 관계에 대해 알아보자. Cache size = C bytes, Block size = B bytes, Number of blocks = M, Number of sets = S라고 하자. N-way set-associative cache에 대해 다음의 관계가 성립한다.
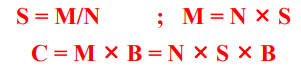
'KNU_study > 컴퓨터구조' 카테고리의 다른 글
| 컴퓨터구조(5) Processor : Pipelined Implementation (1) | 2023.12.22 |
|---|---|
| 컴퓨터구조(4) Single-Cycle Implementation (1) | 2023.12.22 |
| 컴퓨터구조(3) Computer Arithmetic (1) | 2023.12.22 |
| 컴퓨터구조(1) Software and hardware of computers (1) | 2023.10.26 |



