1. Pipelining
(1) Introduction
세탁을 예로 들어보자. 4명이 각기 세탁물을 가지고 있다. 세탁 과정은 [1] 세탁기를 이용한 빨래(30분), [2] 건조기를 이용한 건조(30분), [3] 세탁물 개기(30분), [4] 세탁물 치우기(30분)의 4가지 과정으로 이루어진다.
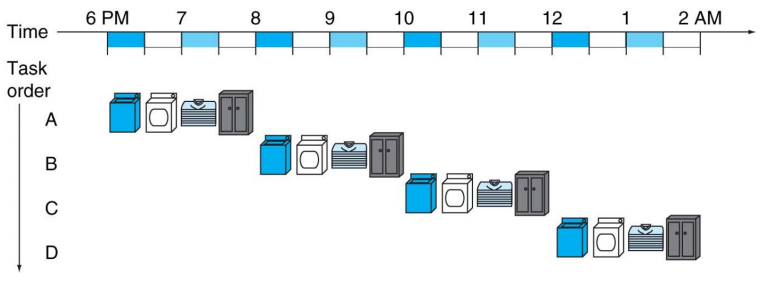
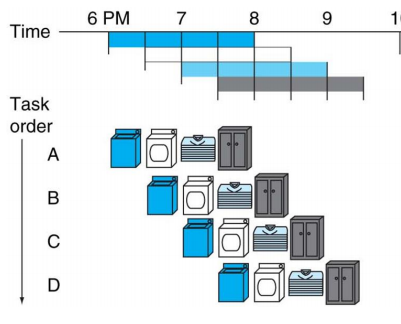
이때 빨래, 건조, 개기, 치우기 각각을 pipeline stage라고 한다. MIPS 프로세서의 경우, 5개의 steps를 가지며, 총 5개의 stage가 존재한다.
| Instruction class | |||||
| R-type | Instruction memory |
Register file | ALU | Register file | |
| Load word | Instruction memory |
Register file | ALU | Data memory | Register file |
| Store word | Instruction memory |
Register file | ALU | Data memory | |
| Branch | Instruction memory |
Register file | ALU | ||
| Jump | Instruction memory |
Pipelined processor의 5 stages는 아래와 같다. 참고로 1 stage는 1 clock cycle에 해당한다.
| Stage | |
| IF | Fetch instruction from memory (메모리로부터 명령어 패치) |
| ID | Read registers while dacoding the instruction (레지스터 읽기) |
| EX | Execute the operation or calculate an address (operation 실행 혹은 주소 계산) |
| MEM | Access an operand in data memory (데이터 메모리로 접근) |
| WB | Wrtie the result into a register (레지스터 쓰기) |
Latency는 특정 작업(task)을 수행하는데 걸리는 시간을 의미하고, Throughput은 단위 시간당 수행하는 작업의 양을 의미한다. 또한 Issue는 명령어가 첫 번째 pipeline stage로 돌아가는 것이며, Commit는 명령어가 마지막 pipeline stage를 나오는 것이다. 즉, Commit는 명령어 수행이 끝난 상황이다.
Pipelining은 명령어들 사이의 병렬성(parallelism)을 이용하여 여러 개의 명령어들을 서로 다른 stage에서 동시에 수행한다. 물론 동시에 수행되고 있는 명령어들은 서로 다른 fuctional units(= hardware resource)를 사용한다. Pipelining은 단일 명령어의 latency를 감소시키는 것이 아니라, issue rate(= commit rate)를 증가시킴으로써 instruction throughput을 향상시킨다. 결과적으로 전체 program의 latency를 감소시킨다.
(2) Single-Cycle vs Pipelined Performance
| Instruction class | Instruction fetch | Register read | ALU operation | Data access | Register write | Total time |
| lw | 200ps | 100ps | 200ps | 200ps | 100ps | 800ps |
| sw | 200ps | 100ps | 200ps | 200ps | 700ps | |
| add, sub,and, or, slt (R format) |
200ps | 100ps | 200ps | 100ps | 600ps | |
| beg | 200ps | 100ps | 200ps | 500ps |
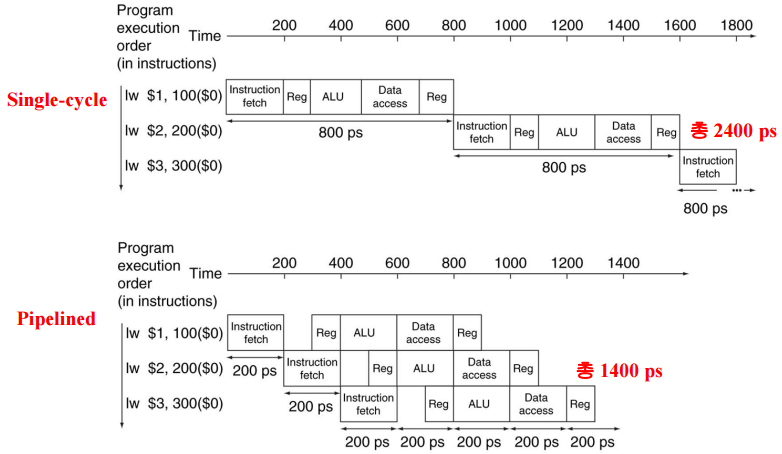
위와 같은 예시에서 Single-cycle design의 clock cycle은 가장 오래 걸리는 명령어의 실행 시간을 기준으로 하므로 800ps이고, Pipelined design의 clock cycle은 Stage delay 중에 가장 큰 것에 맞추어야 하므로 200ps다.
(3) Speedup by pipelining
이상적인 경우는 아래와 같다. (2)의 예시를 적용해보면 pipelined processor의 clock cycle time이 160ps가 되어야 하는데, 실제로는 200ps다. 그렇다면 아래의 두번째 식은 적용이 되나? (2)의 예시를 적용해보면 4개(800ps/ 200ps)의 성능 향상이 있어야 하는데, 앞 예에서는 2400ps에서 1400ps로 향상된 것에 불과하다.


왜 ideal한 경우와 실제 결과가 다를까? [1] Pipeline을 채우고(fill) 비우는(drain) 과정으로 인한 speedup 감소가 원인이 된다. 채우는 초기 상황과, 비우는 마지막 상황 동안에는 pipeline stage들이 완전히 채워져 있지 않게 되고, 이로 인한 speedup 감소가 있다. 이것은 instruction의 수과 몇 개 안될 경우 더 영향이 크며, instruction의 수가 큰 경우에는 거의 영향이 없다. [2] Pipeline hazards로 인한 speedup 감소가 원인이 된다. ㅈㅈㅈ
2. Pipelined datatpath
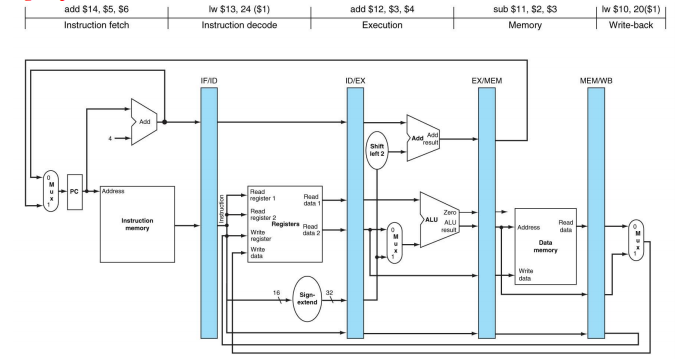
Single-cycle datapath를 5 부분으로 나누자. 5 stages는 datapath를 5개로 나누어야 함을 의미하기 때문이다. 참고로 Data는 (write-back 제외) 왼쪽에서 오른쪽으로 이동한다. 또한 Jump 명령어는 고려하지 않는다.
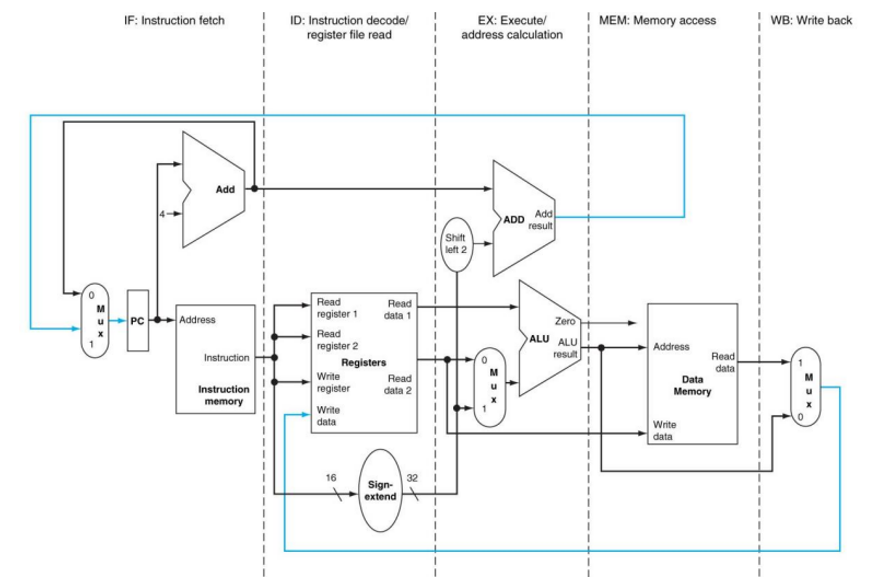
(1) Pipeline Register
Pipelined datapath는 아래 그림처럼, 나누어진 5개의 구역 사이에 register를 넣어서 만들어진다.
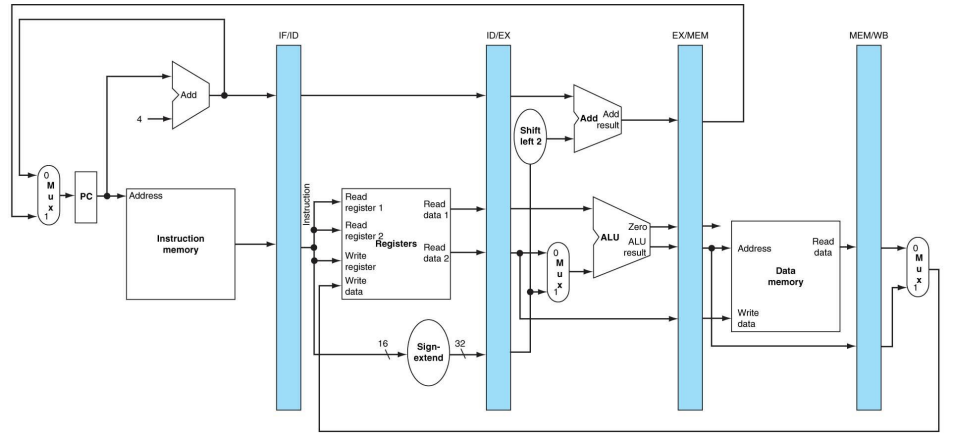
Pipeline register는 각 stage에서 만들어진 data 중에서 다음 stages에서 필요한 data를 보관하는 용도로 사용된다. register의 이름은 해당 레지스터의 양쪽에 위치한 2개의 stages의 이름을 따서 짓기로 한다. 따라서 IF/ID, ID/EX, EX/MEM, MEM/WB와 같이 이름이 지어진다. (WB stage의 끝에는 레지스터가 불필요하므로 생략.) PC도 IF stage의 동작을 위한 pipeline register로 볼 수 있지만, 다른 레지스터들과 다르게 visible register라는 특징을 가진다. 이들의 특정 field를 지정할 때는 .을 사용한다. 예를 들어 IF stage에서 fetch한 instruction은 IF/ID.IR에 저장된다.
(2) Load Instruction
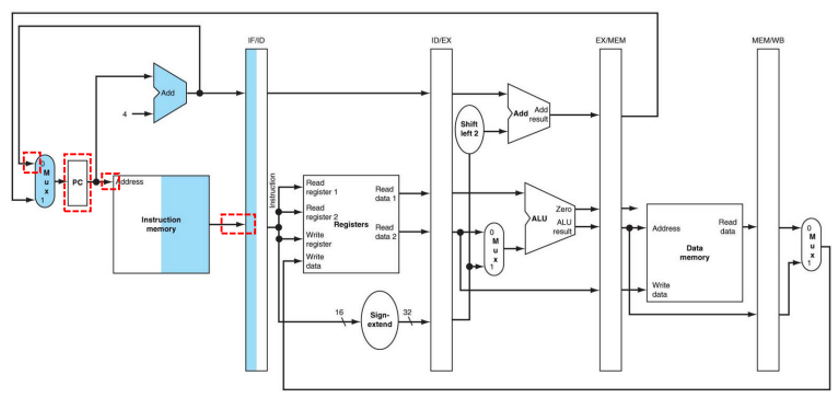
그림에서 하이라이트된 부분은 active한 datapath portion을 의미한다. 또한 Memory, register, register file이 read되는 경우에는 오른쪽인 하이라이트되고, write되는 경우에는 왼쪽이 highlight된다.
| IF stage | IF/ID.IR <= IMEMORY[PC]; |
| IF stage | PC <= PC + 4; |
| ID stage | ID/EX.A <= Reg[IF/ID.IR[25:21]]; |
| ID stage | ID/EX.IMM <= sing-extend(IF/ID.IR[15:0]); |
| ID stage | ID/EX.RT <= IF/ID.IR[20:16]; (for rt) |
| EX stage | EX/MEM.AR <= ID/EX.A + ID/EX.IMM; |
| EX stage | EX/MEM.RD <= ID.EX.RT; (for rt) |
| MEM stage | MEM/WB.LR <= DMEMORY[EX/MEM.AR]; |
| MEM stage | MEM/WB.RD <= EX/MEM.RD; (for rt) |
| WB stage | Reg[MEM/WB.RD] <= MEM/WB.LR; (no rt) |
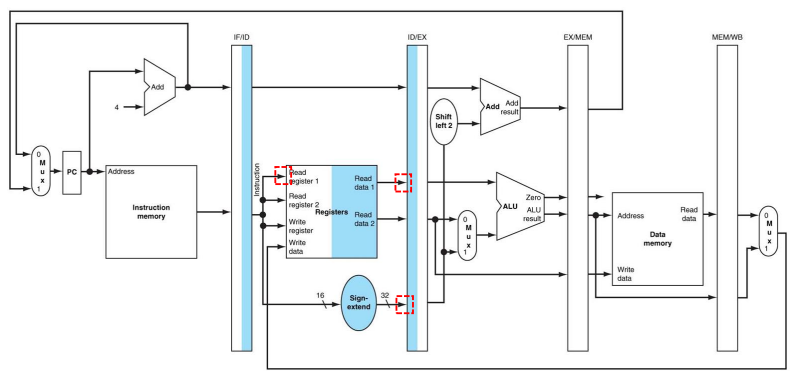
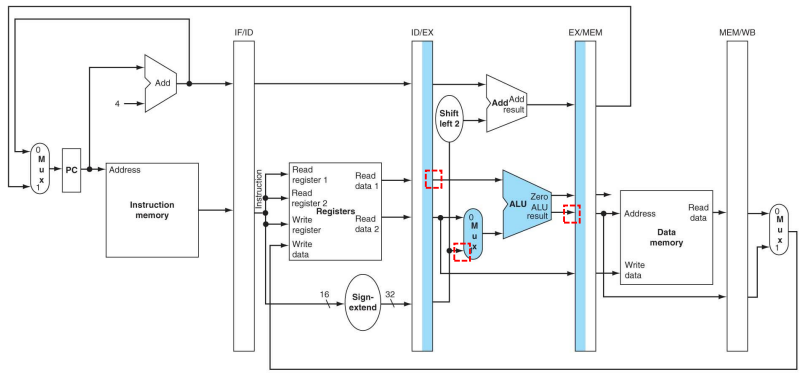
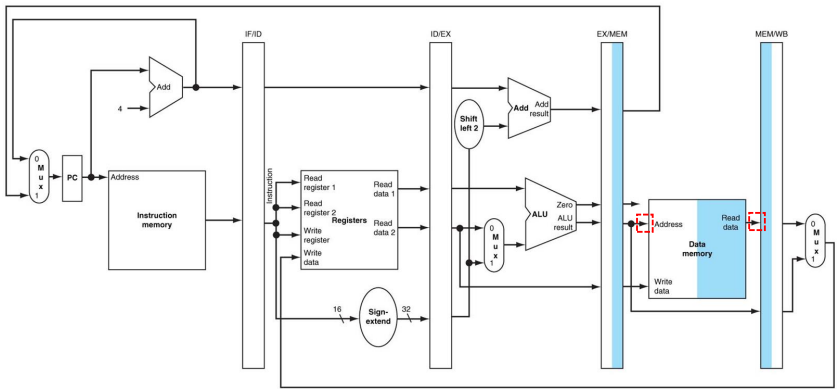
참고로 Reg[rt] <= MEM/WB.LR; (WB stage)라고 작성할 경우 Bug를 발견할 수 있다. 해당 RTL식에서 rt는 어디서 나오는지 알기 위해 Bug Fix를 수행할 필요가 있다. 바뀐 동작들은 표에 나타나있다.
(3) Store Instruction
| IF stage | IF/ID.IR <= IMEMORY[PC]; |
| IF stage | PC <= PC + 4; |
| ID stage | ID/EX.A <= Reg[IF/ID.IR[25:21]]; |
| ID stage | ID/EX.B <= IF/ID.IR[20:16]; |
| ID stage | ID/EX.IMM <= sing-extend(IF/ID.IR[15:0]); |
| EX stage | EX/MEM.AR <= ID/EX.A + ID/EX.IMM; |
| EX stage | EX/MEM.B <= ID.EX.B; |
| MEM stage | MEMORY[EX/MEM.AR] <= EX/MEM.B; |
| WB stage | No operation, 그러나 해당 stage는 거쳐서 끝난다. |


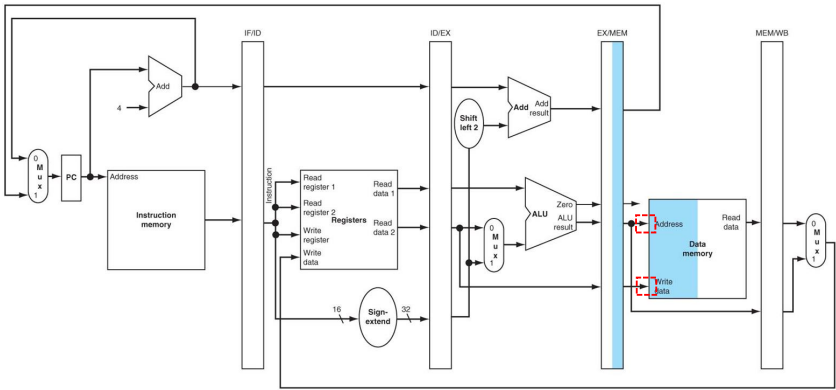
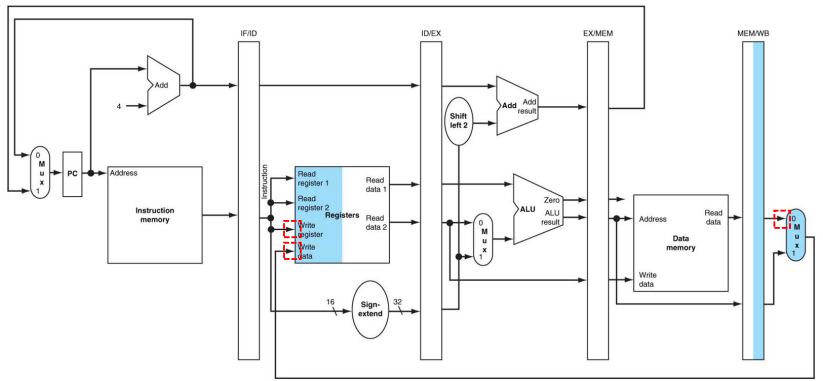
(4) R-Type Instruction
| IF stage | IF/ID.IR <= IMEMORY[PC]; |
| IF stage | PC <= PC + 4; |
| ID stage | ID/EX.A <= Reg[IF/ID.IR[25:21]]; |
| ID stage | ID/EX.B <= IF/ID.IR[20:16]; |
| ID stage | ID/EX.RD <= IF/ID.IR[15:11]; |
| EX stage | EX/MEM.AR <= ID/EX.A op ID/EX.B; |
| EX stage | EX/MEM.RD <= ID.EX.RD; |
| MEM stage | MEM/WB.AR <= EX/MEM.AR; |
| MEM stage | MEM/WB.RD <= EX/MEM.RD; |
| WB stage | Reg[MEM/WB.RD] <= MEM/WB.AR; |
(5) Branch Instruction
| IF stage | IF/ID.IR <= IMEMORY[PC]; |
| IF stage | PC <= PC + 4; |
| IF stage | IF/ID.PC <= PC (before increment) + 4; |
| ID stage | ID/EX.A <= Reg[IF/ID.IR[25:21]]; |
| ID stage | ID/EX.B <= IF/ID.IR[20:16]; |
| ID stage | ID/EX.RD <= IF/ID.IR[15:11]; |
| ID stage | ID/EX.PC <= IF/ID.PC; |
| EX stage | EX/MEM.PC < = ID/EX.PC + (ID/EX.IMM << 2); |
| EX stage | EX/MEM.Z <= Zero output of ALU operation (ID/EX.A – ID/EX.B); |
| MEM stage | if (EX/MEM.Z == 1) PC <= EX/MEM.PC; |
| WB stage | No operation, 그러나 해당 stage는 거쳐서 끝난다. |
(6) Pipeline Registers의 fields


(7) Pipeline diagrams
Pipeline에서의 operation을 표현하는 2가지 종류의 pipeline diagrams가 있다. [1] Multiple-Clock-Cycle Pipeline diagram은 각 stage에서 사용되는 physical resources를 사용한 표현과 각 stage의 name을 사용한 표현이 있다. 아래 그림과 같다.
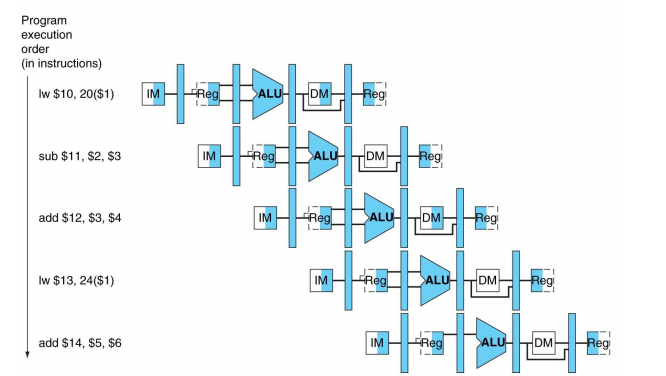
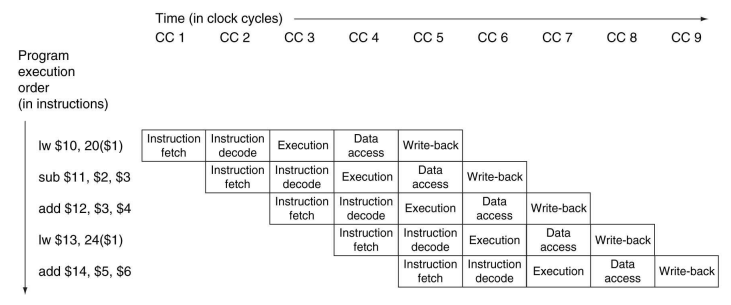
[2] Single-Clock-Cycle Pipeline Diagram은 단일 clock에서의 전체 datapath의 상태를 보여준다. 즉, 단일 clock 동안의 상세 정보를 나타낸다. 아래의 경우 CC 5를 보여준 것이고, 여러 cycles 동안의 operation을 보이기 위해 보통 여러 개의 diagrams로 이루어진 group으로 제시된다.
3. Pipelined control
(1) Pipelined Datapath with Control Signals
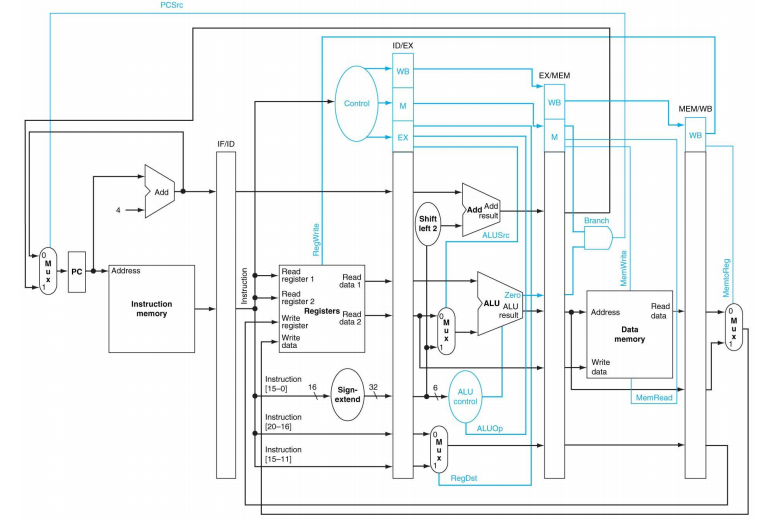
single-cycle processor의 컨트롤 신호를 기반으로 pipelined control signal들을 구성한다. 일반 single-cycle datapath와 pipelined datapath와의 가장 큰 차이점은 pipeline register가 존재한다는 것이다. 따라서 pipeline register에 대한 control (write enable)을 확인해야 한다. 그러나 pipeline register는 매 clock cycle에 write되므로 wirte enable signal이 필요 없다. PC에 대한 write enable도 필요 없다.
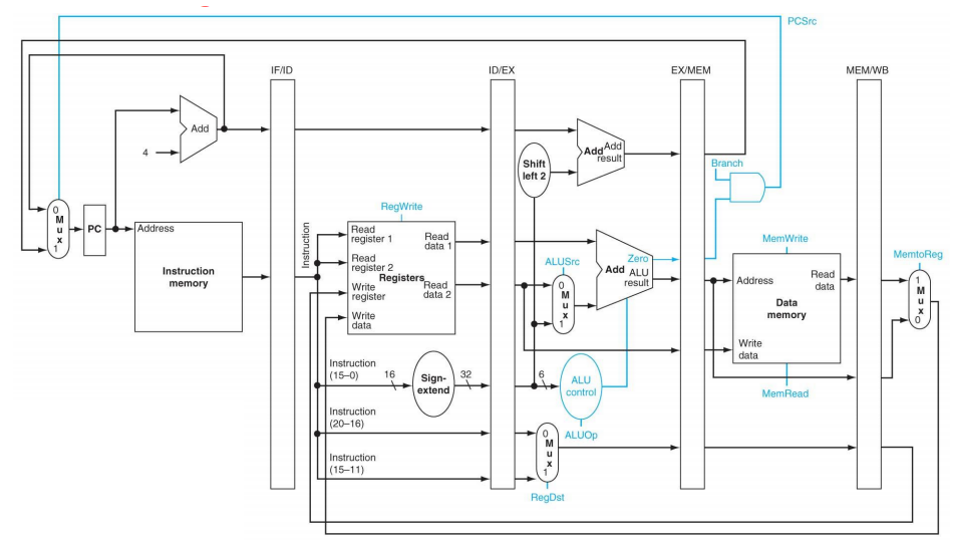
pipelined datapath에서 사용되는 control signal들은 해당 제어 신호가 사용되는 pipeline stage에 따라 분류될 수 있다. [1] ALU control signals는 single-cycle datapath와 동일하게 생성된다. 단, funct field 대신에 ID/EX.IMM[5:0]을 사용한다. ALUOp는 opcode를 이용하여 main control에서 생성되며, instruction class를 구분하는 역할을 그대로 수행한다. [2] Main control signals의 경우, 기본적으로 같은 구조를 사용하나 pipelining으로 인해 control signals의 의미가 조금씩 다르다. 아래 표를 참고하자 !
| Main control | deasserted( = 0 ) | asserted( =1 ) |
| RegDst | EX/MEM.RD <= ID/EX.RT | EX/MEM.RD <= ID/EX.RD |
| ALUSrc | 2nd ALU operand = ID/EX.B | 2nd ALU operand = ID/EX.IMM |
| PCSrc | Next PC = current PC + 4 | Next PC = EX/MAM.PC (branch target) |
| MemRead | None | EX/MEM.AR에 의해서 지정된 DMEMORY location의 data를 read함 |
| MemWrite | None | Memory write data (EX/MEM.B) 를 EX/MEM.AR에 의해서 지정된 DMEMORY location에 write함 |
| MemtoReg | Register write data = ALU output | Register write data = MEM/WB.LR |
| RegWrite | None | Reg[MEM/WB.RD] <= register write data |
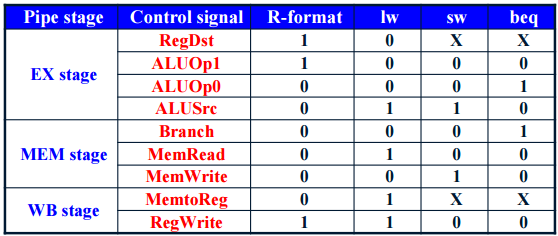
참고로 single-cycle datapath에서 PCSrc는 control unit에 의해서 만들어지는 control signals가 아니라, branch라는 control signal과 ALU의 zero output에 의해서 값이 설정되는 control signal이다. pipelined processor의 경우, 역시나 PCSrc는 Branch와 EX/MEM.Z에 의해서 결정되는 값이다. 또한 ALUOp는 instruction class를 구분하는 역할을 한다.
(2) Main Control의 구현
ID stage에서 9개의 control signals를 모두 발생시킨다. 발생된 control signals를 pipeline register를 이용해 instruction의 각 stage로 전달한다. 참고로 특정 stage에서 사용된 control signals는 다음 pipeline register에 저장할 필요가 없다.
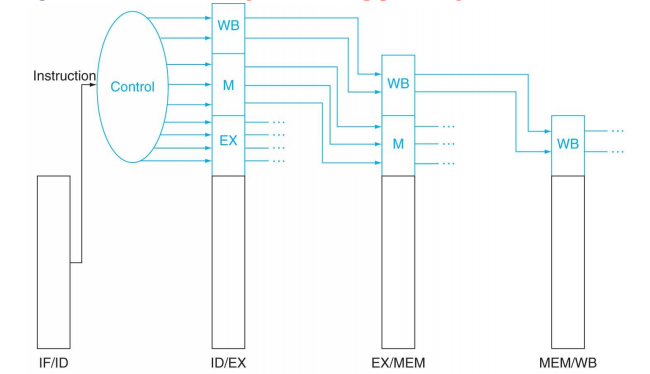
Pipelined Datapath with the control unit의 최종 그림은 아래와 같다.
4. Pipeline hazards
pipelining에도 제약이 존재한다. pipeline hazards는 instruction이 적당한 clock cycle에 실행될 수 없게 하는 사건들을 말하며, [1] Structural hazards, [2] Data hazards, [3] Control hazards로 분류된다.
(1) Structural hazards
하드웨어 자원의 부족으로 인해 명령어들을 같은 clock cycle에 실행할 수 없는 경우 발생한다. 세탁을 예로 들면 혼자서 세탁을 하는 경우 '개기'과 '치우기'를 동시에 할 수 없으며, 일체형 세탁-건조기를 사용하는 경우 '세탁'과 '건조'를 동시에 할 수 없다. 이를 MIPS pipelined processor에서도 살펴보면 2개의 memoery(명령어 메모리와 데이터 메모리)가 아닌 1개의 memory만을 사용한다면, load 명령어가 MEM stage에서 memory를 읽는 동안 insturcion fetch를 수행할 수 없을 것이다.
단순히 하드웨어 자원을 더 둠으로써 해결이 가능하다. (돈은 더 들 것이다.) (1)의 경우는 잘 일어나진 않는다.
(2) Data hazards
명령어 수행을 위해서 필요한 데이터가 준비되지 않은 이유로 명령어를 수행할 수 없는 경우를 말한다. 예를 들어, 아래의 경우 2번째 명령어에서 register $2의 값을 제대로 읽을 수 있을까? 52쪽 예제를 공부하자 ~

Data forwarding이란 필요한 data가 레지스터 또는 메모리에 write되지 않은 경우, write될 때까지 기다리지 않고 그 data를 internal buffers로부터 읽어서 data hazard를 해결하는 방법이다. Data by passing이라고도 하며, internal buffers는 pipeline register에 해당한다. (Pipeline register에 존재하는 AR, LR field가 명령어의 실행 결과를 저장한다.)
Data forwarding을 위해서는 data hazard의 존재를 판단하는 Data hazard detection을 수행하여야 한다. Data forwarding의 조건은 3가지로 [1] Register number과의 비교, 우선 RS field를 ID/EX에 추가한다. 그후 EX/MEM.RD == ID/EX.RS, EX/MEM.RD == ID/EX.RT, MEM/WB.RD == ID/EX.RS, MEM/WB.RD == ID/EX.RS를 각각 비교한다. [2] Register $0은 forwarding을 하면 안된다. 즉 EX/MEM.RD != 0 또는 MEM/WB.RD != 0이다. [3] 앞선 명령어가 이 register에 write하는 명령어여야 한다. 즉 EX/MEM.RegWrite asserted 또는 MEM/WB.RegWrite asserted여야 한다.
Data forwarding을 위해서는 data hazard detection을 바탕으로 적당한 data를 forward할 수 있어야 한다. 아래 그림과 같이 ALU의 input에 mux를 두고, 적당한 control signals를 만들어야 한다.
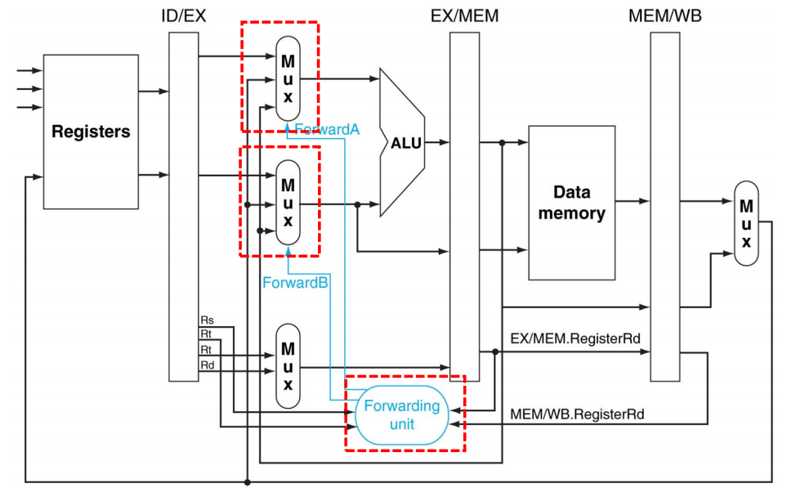
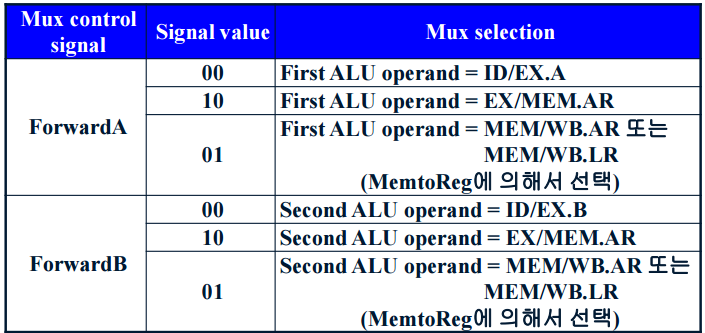
Load-Use Data Hazard란 Load 명령어 바로 다음에 오는 명령어가 load 명령어의 결과를 요구하는 경우에 발생하는 data hazard를 의미한다. 이 경우, 그 명령어 포함 이후에 있는 명령어는 모두 stall되어야 한다. stall이란 명령어가 pipeline stage에서 진행하지 않고 멈추는 것을 말하며, (pipeline) bubble이라고도 한다. stall의 방법으로는 [1] hazard가 있는 명령어를 ID stage에서 1cycle stall한다. [2] IF/ID register 및 PC의 변경을 막는다. [3] ID/EX register에 nop(stage change가 없는 명령어)를 삽입한다. 9개의 모든 control signal을 0으로 한다. 자세한 내용은 나중에 ~~
(3) Branch Hazards
주어진 cycle에 실행될 명령어가 그 cycle에 fetch되지 못해서, 실행되지 못하는 경우를 말한다.
5. Exceptions in a pipelined processor
내용
'KNU_study > 컴퓨터구조' 카테고리의 다른 글
| 컴퓨터구조(6) Processor : Pipelined Implementation (1) | 2023.12.30 |
|---|---|
| 컴퓨터구조(4) Single-Cycle Implementation (1) | 2023.12.22 |
| 컴퓨터구조(3) Computer Arithmetic (1) | 2023.12.22 |
| 컴퓨터구조(1) Software and hardware of computers (1) | 2023.10.26 |



