해당 논문 링크 : https://ieeexplore.ieee.org/document/9739234
관련 논문(2019년도) 리뷰 : https://ufubbd.tistory.com/163
0. Abstract
복잡한 장면에서 사용자가 지정한 객체를 순차적으로 파악하자. 본 논문에서는 bin-picking에서 객체를 파악하지 위한 SGN(Sequantial Grasping Network)를 제안한다. 이는 크게 인스턴스 분할을 위한 Mask R-CNN, grasping evaluation을 위한 VPG(Visual Pushing Grasping) 네트워크로 구성된다. 세분화 네트워크의 경우 그립을 용이하게 하기 위해 대상 물체의 크기에 따른 mask의 neighborhood expansion method를 제안한다. grasping 네트워크의 경우 RGB-D heightmaps의 선형 조합을 입력으로 사용하는 접근법을 제시하여, grasping policy network의 크기를 줄여준다. 순차적 파악 작업의 경우, 우리는 dataset에 대해 제안한 SGN의 성능을 정량적으로 평가했다. SGN의 평균 완료율은 분리된 장면에서 93.3%, 가려진 장면에서 62.5%를 기록했다. 결과는 우리의 접근 방식이 순차적 파악 작업에서 놀라운 성능을 달성했음을 보여준다.
-> neighborhood expansion method란? 주로 컴퓨터 비전이나 이미지 처리 분야에서 영역 확장이나 객체 탐지와 관련된 기술을 의미한다. 일반적으로 객체의 경계나 영역을 정확하게 분리하고, 식별하는 데 사용된다. 특히 객체가 서로 다른 색상, 밝기, 질감 등을 가지는 영역으로 나뉘어진 이미지에서 유용하게 사용된다. [1] 시작점 선택, 픽셀 값이나 그라디언트 등을 기준으로 시작점을 선택하여 객체의 영역을 확장한다. [2] 이웃 픽셀 유사성 검사, 주변 픽셀들이 시작점과 유사한지 여부를 판단한다. [3] 이웃 픽셀 확장, 유사한 픽셀을 찾으면 해당 픽셀을 시작점과 같은 객체 영역으로 간주하고 이를 확장한다. 재귀적으로 확장이 이루어진다. [4] 픽셀 연결, 이웃 픽셀을 계속 확장해 나가면서 객체 영역을 점차적으로 확장한다. 이 과정에서 픽셀 간의 연결 관계를 분석하여 영역을 형성하고, [5] 반복, 위 과정을 여러 번 반복하여 최종 객체 영역을 마무리짓는다.
1. Introduction
다양한 물체를 신속하고 안전하게 파악하는 것은 오늘날 비정형 환경에서는 매우 까다로운 문제다. 연구자들이 일부 연구 부분에선 큰 성공을 거두었음에도 센서 노이즈, 부분적 관찰 가능성, 부정확한 제어, 하드웨어 한계 등으로 인한 미해결 문제들은 여전히 존재한다. 최근 새로운 물체를 파악하는 성공적인 접근 방식은 실제 세계에서 수집된 대규모 dataset을 사용한다. 이는 입력 이미지에서 파악 후보들의 출력으로 매핑하는 심층 신경망을 훈련하는 방식이다.

grasping task에서 point cloud, geometric attribute를 사용한 기존 연구들의 목적은 파악 순서를 고려하지 않고 모든 객체를 파악하는 것인데, 본 논문에서는 non-sequential grasping(비순차적 파악 작업)으로 정의된다. 그러나 물류 분류 및 상품 자동화 선택과 같은 일부 시나리오에서는 작업의 순서가 중요하다. 우리는 이러한 작업을 순차적 파악 작업으로 정의한다. 위 그림은 순차적 파악 작업과 비순차적 파악 작업 간의 차이를 보여준다. occlusion이 심한 복잡한 장면에서는 순차적으로 물체를 파악할 때 약간의 주의를 기울인다.
-> occlusion은 '가려짐'이나 '가려진 것'을 의미하는 단어다. 컴퓨터 비전 및 그래픽스 분야에서 occlusion은 한 객체나 물체가 다른 객체나 물체를 가리는 현상을 지칭한다. 주로 3D 공간에서 물체들이 서로 겹쳐져 있을 때 발생하며, 카메라나 관찰자의 시점에 따라서도 영향을 받는다.
우리 작업에서는 사용자가 지정한 목표 객체를 순차적으로 파악하는 작업을 처리하기 위해, Sequential Grasping Network(SGN)를 제안한다. 이 기술은 Mask R-CNN, 수정된 VPG(Visual Pushing Grasping) 네트워크로 구성된다. 아래는 우리의 주요 기여를 요약한 것들이다.
-> 사용자가 지정한 객체를 순차적으로 빠르게 파악하기 위한 목표 중심 SGN을 제안한다.
-> 객체 크기를 기반으로 마스크의 neiborhood expansion method를 제안하여 용이하게 객체 파악을 한다.
-> RGB-D heightmaps의 선형 조합을 grasp network의 입력으로 사용한 방법을 제시한다.
-> RGB-D height란? 다차원 데이터를 활용하여 환경의 고도 정보를 표현하는 방식으로, RGB는 Red Green Blue의 색상 채널 값을, D(Depth)는 깊이 정보를, Heightmaps는 고도 정보를 의미한다. 이는 RGB 이미지와 함께 카메라로부터 얻은 깊이 정보를 결합하여, 환경의 표면 높이를 표현하는 방식이다. 주로 3D 환경 모델링, 로봇의 자율 이동, 객체 탐지 및 추적 등 응용분야에서 사용된다.
2. Related Work
(1) Sequential Grasping
로봇이 다양하고 새로운 물체를 빠르고, 안정적으로 팡가하는 능력은 서비스 로봇 응용 분야에 도움이 된다. 이전의 많은 연구에서 좋은 결과를 얻었다. 목표는 영역 내 모든 물체를 제거하는 것이지만, 잡는 순서는 중요하지 않다. 순차적 파악 작업을 해결하기 위해, 한 가지 가능한 해결책은 object instance segmentation과 grasping evaluation method를 결합하는 것이다.
높은 수준의 순차적 결정 작업과 달리, 우리의 작업은 복잡한 장면에서 특정 객체 인스턴스를 파악하는 것이 목표인 인스턴스 파악의 맥락에서 이루어진다. 보다 구체적으로, 우리의 목표는 사용자가 지정한 대상 객체를 순차적으로 파악하는 작업을 다루고자 한다. 본 연구에서는 객체들이 서로 가려져 있는 장면을 자동으로 처리하는 심층 강화학습 방법을 사용한다.
(2) Instance Segmentation
인스턴스 분할은 이미지 내의 각 개별 객체(instance)를 픽셀 수준에서 식별하고, 분리하는 작업이다. 물체 탐지(Object Detection)와 시맨틱 분할(Semantic Segmentation)의 중간 개념으로 볼 수 있다. 시맨틱 분할은 이미지의 각 픽셀을 클래스 레이블로 할당하여 이미지 내의 물체나 영역을 식별하는 작업이다. 이와 달리, 인스턴스 분할은 같은 클래스에 속하는 여러 객체를 개별적으로 구분하여 인식한다.
예를 들어, 한 이미지에서 여러 대의 자동차가 있을 때, 각 자동차를 개별 객체로 식별하는 것이 인스턴스 분할의 목표다. 이는 객체의 경계를 정확하게 분리하여 각 객체를 픽셀 수준에서 구분하므로, 객체 간의 겹침이나 부분적 가려짐 상황에서도 객체를 정확하게 식별할 수 있다. 이를 위해 주로 CNN을 사용한 다양한 알고리즘이 개발되었다.
Mask R-CNN은 인스턴스 분할 방법 중 하나이며, robotic manipulation research에 사용되었다. 본 연구에서는 mask를 직접 사용하는 대신 RGB 이미지만을 사용하여 Mask R-CNN을 훈련하고, 객체 크기를 기반으로 mask의 이웃 확장 방법을 사용하여 파악을 용이하게 할 것이다.
-> 논문에서 이해 가지 않는 부분이 많아 일부분은 논문 외 자료들을 참고하여 작성하였습니다.
(3) Non-prehensile and Prehensile
non-prehensile(밀기) 및 prehensile(잡기) 동작은 잡기 성능을 향상시키는 데 도움이 된다. Pushing은 너무 복잡해서 잡을 수 없는 물체를 처리하는데 유용한 동작이다. 이전 연구에서는 오브젝트 파악에 도움이 되는 push 동작을 선택하는 제어 정책을 훈련했다. 훈련 때엔 수작업으로 만든 특징들을 사용하였고, 두 개의 객체만 있는 하나의 시나리오에서만 테스트하였다. Salganicoff 등은 로봇이 이미지 공간에서 연결된 물체를 밀 수 있는 조작 동작을 학습하기 위한 비지도 온라인 방법을 제안한다. 우리는 self-supervised deep Q-learning을 통해 밀기와 잡기 사이의 시너지 효과를 학습하기 위해 심층 정책 신경망을 훈련하는 최근 연구를 기반으로 한다. 그러나 RGB-D 하이트맵의 선형 조합은 거의 4G의 GPU memory만 필요하기 때문에, 미리 훈련된 4개의 고밀도 특징 추출기 네트워크 중 2개만 사용한다.
3. Problem Formulation
본 연구에서는 순차적 파악 작업(sequential grasping task)을 grasping sequence G에 의해 지정된 대상 객체를 파악하는 것으로 공식화한다. 아래 공식과 같다.
여기서 O는 object ID이고, i는 grasping 순서의 인덱스다. 이 챌린지의 목표는 복잡한 장면에서 G가 지정한 물체를 순서대로 잡는 것이다. 그리고 이것은 인스턴스 파악의 순차적 버전으로 생각할 수 있다. 또한 상태를 완전히 관찰할 수 없기 때문에 우리는 grasping part를 부분 관측 가능한 POMDP로 공식화한다. 우리는 색상이 다르고 크기가 다르지만 동일한 모양인 도형들은 같은 카테고리에 있고, 같은 object ID를 공유한다고 가정한다.
-> POMDP란? Partially Observable Markov Decision Process로, 불확실성이 있는 환경에서 의사 결정을 내리는 문제를 모델링하는 데 사용된다. Partially Observable이란 에이전트가 환경의 현재 상태를 정확하게 관찰하지 못한다는 것을 의미한다. 즉, 에이전트는 관찰을 통해 환경의 상태를 추정해야 한다.
4. Methods
(1) Grasping Definition
grasping policy network의 경우, RGB-D heightmaps의 선형 조합인 CH가 입력으로 주어지고, 출력은 robotic grasps를 위한 4차원 표현이 나온다. 물체 grasp 작업은 픽셀 단위의 라벨링 과제로 공식화되는데, 각 이미지 픽셀과 이미지 방향이 scene에서 해당 픽셀의 3D 위치에서 실행되는 특정 robot primitive에 해당된다. 그런 후 이 매개변수들은 로봇에 전송되어 해당 물체를 집어 들도록 한다. 이 표현은 로봇 좌표계에서 parallel plate gripper의 위치와 방향을 제공한다.

여기서 (x, y, z)는 그리퍼의 중심 위치이고, θ는 수직축 Z를 중심으로 한 수평축에 대한 그리퍼의 방향이다.
(2) Object Segmentation
우리는 VREP 시뮬레이션 환경에서 수집한 RGB 이미지 데이터를 사용하여 Mask R-CNN 네트워크를 세분화 네트워크로 훈련한다. Mask R-CNN의 출력은 masks M ∈ RH X W X c+ 이다. 이 M은 임계값 ϕ보다 큰 신뢰도를 가지는 객체의, 특정 클래스에 속하는 각 픽셀을 보여준다. grasping sequence G에서 목표 객체 인덱스 i에 따라 목표 객체 마스크 Mi를 직접 사용하는 대신, 우리는 객체 크기에 따라 마스크의 neighborhood expansion method를 제안한다. 객체의 확장 마스크 Mi'는 다음과 같이 정의된다.
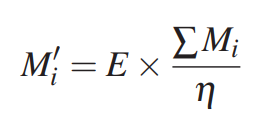
E는 이미지 처리에서 9제곱 그리드를 기반으로 하는 기본 확장 연산이다. ∑Mi는 이미지 공간에서 객체 사이즈를 추정하는 mask Mi의 합이고, η은 스케일링 계수다.
(3) Channel Fusion
대상 물체의 RGB-D 데이터는 높이 H, 너비 W의 장면에서 현재 상태 S를 관찰한 것이다. 각 에피소드의 시작에는 c 카테고리의 물체 m개와 배경 테이블이 있다. 여기선 m ≥ n이 성립하고, n은 그립 시퀀스 G의 길이다. grasping policy network에서는, 우리는 아래 공식처럼 정의된 RGB-D heightmaps CH의 선형 조합을 입력으로 사용한다.

여기서 i != j != k이고 i, j, k ∈ {R, G, B}이며, α는 rgb_d 비율이고, H는 하이트맵이다. 이 방법은 원래 VPG 네트워크의 크기를 줄여 2개의 사전 훈련된 고밀도 네트워크만 사용하여 높은 수준의 특징을 추출할 수 있다.
(4) Sequential Grasping Network

SGN은 인스턴스 분할을 위한 Mask R-CNN과, grasping 평가를 위한 수정된 VPG network로 구성된다. [1] 먼저 Mask R-CNN은 현재 상태 St의 RGB 이미지를 가져와서 오브젝트 마스크 M을 출력한다. [2] 그 다음 region extraction process는 확장된 마스크를 사용하여, 크롭된 RGB-D 데이터를 출력한다. 참고로 마스크는 그립 시퀀스 G에 따라 평가된 크기의 대상 물체를 기반으로 확장되었다. [3] 대상 데이터, 즉 크롭된 RGB-D 데이터는 수정된 VPG network의 입력으로 들어간다. 우리는 RGB-D heightmaps의 선형 조합을 사용하여 잡기 및 밀기 동작을 평가한다. 최대 Q값을 가진 동작을 선택한 후, 환경은 잡힌 오브젝트 ID를 반환하거나 아무것도 반환하지 않고 잡기 순서의 i 인덱스를 업데이트한다. [4] 최종 객체 O이 성공적으로 잡히거나, 비효율적인 잡기 시도가 10회 초과가 될 때까지 전체 프로세스는 작동하고, 그 후 종료된다.
아래는 각각 알고리즘과, SGN의 추론 과정을 설명하는 흐름도다.


Flow Diagram에서 왼쪽 파트는 instance segmentation flow이고, 오른쪽 파트는 수정된 VPG network다.
(5) Pixel-wise Q-Value
최근 연구에서 영감을 받아, 우리는 잡기 부분을 픽셀 단위의 라벨링 문제로 공식화한다. 그리고 이것은 에이전트가 최적의 정책을 학습하도록 훈련하는 데 효율적이다. 동작 공간은 end-effector 기반 동작 기본요소의 집합으로 단순화된다. 우리는 또한 동작 기본요소로 pushing(밀기), grasping(잡기)를 사용했다. 잡기 정책 네트워크는 2개의 CNN으로, 입력 관측값에서 행동으로 매핑한다. 정책 네트워크의 출력은 두 부분으로 구성되는데 [1] 하나는 부분 픽셀 단위 샘플링에 대한 잡기의 유용성을 추론한다. 이때 부분 픽셀 단위 샘플링은 엔드 이펙터의 방향과, 대상 오브젝트의 위치에서의 샘플링이다. [2] 다른 하나는 pushing 작업에 대해서도 동일한 작업을 수행한다.
(6) Pushing Strategy
우리 작업엔 두 가지 전략이 있다. 이들은 물체 간 우연히 발생하는 문제들을 해결한다. [1] 출력 마스크에 현재 대상 물체가 포함되지 않은 경우, 로봇은 Qp 네트워크의 출력을 직접 사용하여 물체의 현재 상태를 변경한다. [2] 로봇이 현재 목표 물체를 성공적으로 분할한 직후에는, 로봇을 직접 잡기가 어렵다. 이러한 경우, 정책 네트워크는 scene에서 해당 픽셀의 3D 위치에 push 동작을 출력한다. 그리고 환경의 상태를 변경한다. 이는 다음 세분화 부분에 유용하며, 향후 grasp에 활용된다.
5. Experiments

생략하겠습니다.
6. Conclusions and Future work
본 연구에서는 복잡한 환경에서의 순차적 gasping 작업을 해결하기 위해 목표 중심 SGN 네트워크를 제시하였다. 물체 크기에 따른 마스크의 neighborhood expansion 방법을 제안하여 그립을 용이하게 하였다. 또한 RGB-D heightmaps의 선형 조합을 사용하여 graspin 정책 네트워크의 크기를 줄였다. 시뮬레이션 결과, 이 방법이 훈련 과정에서 더 안정적이며, 기본 방법보다 뛰어난 성능을 달성하는 것으로 나타났다.
향후 작업으로는 RGB-D heightmaps의 다른 조합을 시도할 것이다. 예를 들어 빨간색과 파란색 채널을 결합하는 나머지 채널은 남겨두는 식으로 말이다. 물체의 다른 속성을 사전 지식으로 사용하여, 인스턴스 분할 네트워크에서 마스크를 확장하는 것도 흥미로울 것이다. 또한 복잡한 순차 작업을 수행하기 위해 고급 강화 학습 방법을 사용하는 것도 향후 연구의 중요한 주제다.



