https://github.com/rickiepark/handson-ml/
GitHub - rickiepark/handson-ml: 도서 "핸즈온 머신러닝"의 예제와 연습문제를 담은 주피터 노트북입니다
도서 "핸즈온 머신러닝"의 예제와 연습문제를 담은 주피터 노트북입니다. Contribute to rickiepark/handson-ml development by creating an account on GitHub.
github.com
1. RNN image classification
MNIST 숫자 이미지 데이터셋을 분류하는 분류기를 구현할 것이다. 사실 이미지 데이터 학습은 이미지의 공간(spatial) 구조를 활용하는 CNN 모델이 더 적합하다. 그러나 인접한 영역의 픽셀은 서로 연관되어 있으므로 이를 시퀀스 데이터로 볼 수도 있다. 즉 MNIST 데이터 세트를 RNN 분류기로 처리하려면 이미지를 시퀀스로 변환하고, RNN 모델을 훈련하여 숫자 이미지를 인식하도록 해야 한다.
-> MNIST란? Modified National Institute of Standards and Technology의 약어로, '손으로 쓴 숫자 이미지 데이터 세트'를 의미한다. 0부터 9가지의 한 자릿수 숫자를 손으로 쓴 흑백 이미지를 포함하고 있으며, 각 이미지는 28X28 픽셀 크기의 흑백 이미지로 구성된다. 각 픽셀은 0부터 255까지의 값으로 표현되며, 보통 0과 1 사이의 값으로 정규화된다. 딥러닝 모델의 초기 학습 및 테스트에 많이 사용된다.
(1) BPTT(BackPropagation Through Time)
RNN은 기존 신경망의 역전파와는 달리, time step별로 네트워크를 펼친 후 역전파 알고리즘을 사용한다. 쉽게 말해 오차를 역전파하여 네트워크를 훈련하는 과정이다. 각 시간 스텝마다 RNN은 입력을 받고 출력을 생성하는데, 이러한 스텝 간에는 순환적인 연결이 존재한다. 따라서 시간 스텝 t에서의 오차를 계산하고, 이를 이전 시간 스텝으로 역전파하여 가중치를 업데이트한다.

(2) Truncated BPTT
RNN에서 학습 과정을 좀 더 안정화하기 위해 사용된다. 시간 스텝을 일부 제한하고, 제한된 시간 범위 내에서만 역전파를 수행한다. 예를 들어 시퀀스가 1000개의 시간 스텝으로 구성되어 있다면, Truncated BPTT를 적용할 시 각 학습 단게에서 100개의 연속적인 시간 스텝만 고려할 수 있다. 이렇게 하면 계산량과 메모리 사용량을 크게 줄일 수 있다.

(3) RNN을 이용한 분류기 구현
Tensorflow에서 제공하는 28x28 픽셀의 이미지인 MNIST 데이터를 사용해보자. 코드는 크게 두 부분으로 구성될 것이다. MNIST Data를 가져오는 것이 그 첫번째 부분이다.

두번째로, MNIST 데이터셋을 분류하는 RNN 모델을 만들어준다. 해당 모델은 28개의 타임 스텝(28 pixels)의 시퀀스를 입력받아 하나의 벡터를 출력하는 Sequence-to-Vector 모델이다.

2. RNN image classification code
import os
import numpy as np
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
# 일관된 출력을 위해 유사난수 초기화
def reset_graph(seed=42):
tf.reset_default_graph()
tf.set_random_seed(seed)
np.random.seed(seed)
import matplotlib.pyplot as plt
import pandas as pd
plt.show()
plt.rcParams['axes.labelsize'] = 14
plt.rcParams['xtick.labelsize'] = 12
plt.rcParams['ytick.labelsize'] = 12
# 한글출력
# matplotlib.rc('font', family='AppleGothic') # MacOS
plt.rc('font', family='Malgun Gothic') # linux
plt.rcParams['axes.unicode_minus'] = False
# Layer Params #
n_steps = 28
n_inputs = 28
n_neurons = 150
n_outputs = 10
(train_x, train_y), (test_x, test_y) = tf.keras.datasets.mnist.load_data()
# 이미지 데이터를 정규화하고 형태를 조정
train_x = train_x.astype(np.float32).reshape(-1, 28*28) / 255.0
test_x = test_x.astype(np.float32).reshape(-1, 28*28) / 255.0
train_y = train_y.astype(np.int32)
test_y = test_y.astype(np.int32)
# 검증 데이터 분리
valid_x, train_x = train_x[:5000], train_x[5000:]
valid_y, train_y = train_y[:5000], train_y[5000:]
test_x = test_x.reshape([-1, n_steps, n_inputs])
valid_x = valid_x.reshape([-1, n_steps, n_inputs])
print('train_x.shape :', train_x.shape)
print('valid_x.shape :', valid_x.shape)
print('test_x.shape :', test_x.shape)
# Mini-batch
def shuffle_batch(features, labels, batch_size):
rnd_idx = np.random.permutation(len(features))
n_batches = len(features) // batch_size
for batch_idx in np.array_split(rnd_idx, n_batches):
batch_x, batch_y = features[batch_idx], labels[batch_idx]
yield batch_x, batch_y
# Tensorflow graph
reset_graph()
inputs = tf.placeholder(tf.float32, [None, n_steps, n_inputs])
labels = tf.placeholder(tf.int32, [None])
# RNN Model
basic_cell = tf.nn.rnn_cell.BasicRNNCell(num_units=n_neurons)
outputs, states = tf.nn.dynamic_rnn(basic_cell, inputs, dtype=tf.float32)
# dense layer
logits = tf.layers.dense(states, n_outputs) # states = outputs[-1]
# loss
xentropy = tf.reduce_mean(
tf.nn.sparse_softmax_cross_entropy_with_logits(labels=labels, logits=logits))
# Train Params #
learning_rate = 0.001
n_epochs = 5
batch_size = 150
# optimizer
train_op = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(xentropy)
# metric
correct = tf.nn.in_top_k(logits, labels, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))
# Train
with tf.Session() as sess:
tf.global_variables_initializer().run()
for epoch in range(n_epochs):
for batch_x, batch_y in shuffle_batch(train_x, train_y, batch_size):
batch_x = batch_x.reshape([-1, n_steps, n_inputs])
sess.run(train_op,
feed_dict={inputs: batch_x, labels: batch_y})
acc_batch = accuracy.eval(feed_dict={inputs: batch_x, labels: batch_y})
acc_valid = accuracy.eval(feed_dict={inputs: valid_x, labels: valid_y})
loss_batch = xentropy.eval(feed_dict={inputs: batch_x, labels: batch_y})
print('epoch : {:03d}'.format(epoch),
'acc_batch : {:.4f}, acc_valid : {:.4f}'.format(acc_batch, acc_valid),
'loss_batch : {:.4f}'.format(loss_batch))
(1) 'import'문과 모듈 임포트
필요한 모듈을 임포트한다. 구버전의 문법을 사용하므로 tensorflow version 1을 활성화한다.
(2) reset_graph() 함수 정의
tensorflow 그래프를 재설정한다. 이전에 정의된 텐서와 연산을 제거하고 새로운 그래프를 생성한다.
난수 시드를 설정한다. 컴퓨터가 실제로 완전히 무작위한 숫자를 생성하기가 어려운 관계로, 난수 생성기가 시작값 또는 시드(seed)를 사용하여 난수를 생성한다. 예를 들어, 난수 시드를 22로 설정하면 항상 동일한 순서의 난수가 생성된다. 같은 코드를 여러 번 실행해도 항상 똑같은 결과를 얻는다는 점에서 무작위성을 제어, 결과의 일관성을 유지할 수 있다. 해당 함수에선 TensorFlow, NumPy의 난수 생성기의 시드를 각각 설정하였다. 이렇게 함으로써 우리는 재현 가능한 결과를 얻을 수 있다.
(3) 한글 출력 설정
Matplotlib을 사용하여 그래프의 축(label)에 사용되는 글꼴 크기를 14로, 그래프의 X축과 Y축 눈금 레이블에 사용되는 글꼴 크기를 12로 지정한다.
Matplotlib을 사용하여 한글 폰트, 그래프의 레이블 크기 등을 설정한다. 글꼴 패밀리를 한글을 지원하는 글꼴인 'Malgun Gothic'으로 설정한다. 한국어 텍스트를 그래프나 플롯에 사용할 때 유용하다. 그 다음 줄 코드는 마이너스 기호 역시 글꼴에 따라 제대로 표시되게 한다.
(4) Layer params 설정
RNN 모델 및 데이터에 필요한 하이퍼파라미터를 설정한다. n_steps는 RNN 스텝 수, n_inputs는 RNN 입력 크기, n_neurons는 RNN 뉴런 수, n_outputs는 출력 클래스 수(0에서 9까지의 숫자)를 나타내는 변수들이다. RNN 스텝 수와 RNN 입력 크기 변수들은 둘다 MNIST 이미지 크기 값이다.
(5) MNIST 데이터 로드 및 전처리
MNIST 데이터를 로드한다. 훈련 데이터와, 테스트 데이터를 가져온다. 각각의 데이터는 이미지와 레이블로 구성되어 있다.
이미지 데이터를 0에서 1 사이로 normalizing하고 형태를 조정한다. 훈련데이터와 테스트 데이터(train_x, test_x)를 32비트 부동 소수점 형식으로 변환한다. 그리고, 각 이미지 데이터는 28x28 픽셀의 2차원 배열로 되어 있는데 이를 1차원으로 변환하다. 마지막으로, 255.0을 나눔으로써 이미지를 0에서 1 사이의 값으로 정규화한다. 훈련 데이터와 테스트 데이터의 레이블(train_y, test_y)을 정수로 변환한다. MNIST 데이터의 레이블은 숫자 0부터 9까지를 나타내는데, 이들을 정수 형식으로 변환하여 사용하자.
학습, 검증 및 테스트 데이터 세트로 분할한다. 훈련 데이터 중 일부를 검증 데이터(valid_x, valid_y)로 분리한다. 처음 5000개의 샘플을 검증 데이터로 사용하고, 나머지는 훈련 데이터로 사용한다. 검증 데이터는 모델을 훈련하면서 모델의 성능을 평가하는 데 사용된다. 그런 후 RNN 모델에 입력으로 사용하기 위해 테스트 데이터와 검증 데이터의 형태를 조정한다. 시간 스텝(n_steps)과 입력 크기(n_inputs)를 고려하여 형태 조정.
-> 왜 부동 소수점 형식으로 변환하나? 기계 학습 모델의 입력 데이터 형식에 맞추기 위해. 대부분 기계 학습 및 신경망 모델은 입력 데이터를 부동 소수점 형식(float 32, or float 64)으로 요구한다. 부동 소수점 형식은 실수 값을 표현하기에 적합하며, 신경망은 이러한 형식의 데이터를 사용하여 가중치와 연산을 수행한다.
-> 왜 2차원 배열을 1차원으로 변환하나? 기계 학습 모델의 입력 데이터 형식에 맞추기 위해. 일부 기계 학습 모델 또는 신경망 모델은 1차원 벡터 형태의 입력을 원한다. 이런 단계들을 '전처리 단계'라고 부른다.
-> 데이터를 정규화하는 이유는? 모델의 학습이 안정화되고, 수렴 속도 향상을 위하여.
(6) shuffle_batch() 함수 정의
미니배치 학습을 위해 데이터셋을 무작위로 섞고 미니배치로 나눈다. 데이터셋의 인덱스를 무작위로 섞은 배열을 rnd_idx 변수에 저장한다. 얼마나 많은 미니배치가 생성될 수 있는지, 미니배치의 개수를 n_batches에 저장한다. for 루프를 사용하여 rnd_idx 배열을 n_batches 개수로 나눈 리스트를 반환한다. 각 요소는 무작위 인덱스도 포함한다. 그 인덱스를 사용하여 해당 미니배치의 입력 데이터(특성), 레이블 데이터(타겟)를 추출하여 batch_x,batch_y에 각각 저장한다.
이 함수는 generator(반복 가능한 객체)가 되어, 호출자에게 한 번에 하나씩 미니배치를 제공한다. 이는 메모리를 효율적으로 활용할 수 있게 해준다. 이 함수 덕분에 에포크(epoch)마다 데이터셋을 무작위로 섞고, 미니배치로 나누어 모델에 공급하는 작업이 편리해진다.
-> 에포크(epoch)란? 학습 데이터셋 전체를 한 번 훈련하는 과정을 의미한다. 기계 학습에서 모델을 훈련할 때 학습 데이터셋을 여러 번 반복적으로 사용하여 모델을 업데이트한다. 이 때 각 반복은 에포크라고 부른다.
(7) TensorFlow 그래프 생성
reset_graph()를 호출하여 새로운 Tensorflow 그래프를 생성한다.
입력과 레이블을 위한 플레이스홀더를 정의한다. tf.float32 데이터 타입을 가진 3D 텐서를 생성한다. 이 텐서(inputs)는 시퀀스 데이터를 나타내며, 각 시퀀스는 n_steps개의 시간 스텝과 n_inputs개의 특정을 가진다. 첫 번째 차원을 유동적으로 처리하도록 None으로 설정한다. tf.int32 데이터 타입을 가진 1D 텐서를 생성한다. 이 텐서(labels)는 각 시퀀스의 레이블을 나타내며, 역시나 유동적인 초기값 설정을 위해 None으로 설정한다.
BasicRNN 셀을 생성하고, RNN 모델을 정의한다.
출력 레이어를 추가하고, 크로스 엔트로피를 손실 함수로 사용한다. 밀집(dense) 레이어를 추가하여 최종 출력을 생성한다. states는 RNN의 마지막 시간 스텝에서의 상태이고, 이를 입력으로 사용한다. 크로스 엔트로피 손실 함수를 계산하여 실제 레이블(labels)과 모델의 출력(logits)를 비교한다. reduce_man 함수를 사용하여 모든 미니배치의 손실 값을 평균내어 최종 손실 값인 xentropy를 얻는다.
-> 밀집(dense) 레이어란? 모든 입력 뉴런과 출력 뉴런 간의 연결이 완전히 존재하는 층이다. 이는 각 입력과 출력 사이의 가중치(weight)가 존재하고, 모든 입력이 모든 출력에 영향을 주는 것을 의미한다. 이로 인해 인출력 간의 복잡한 비선형 관게를 학습할 수 있다.
(8) 학습 params 설정
학습률, 에포크 수, 미니배치 크기 등의 하이퍼파라미터를 설정한다. 학습률이 너무 크면 수렴하지 않을 수 있고 너무 작으면 수렴이 느려질 수 있다. 따라서 일반적으로 사용되는 0.001의 학습률을 사용한다. 에포크의 수는 5다. 미니배치의 크기는 150으로, 한 번에 모델에 입력되는 데이터 크기라고 생각하면 된다.
(9) 옵티마이저와 메트릭 설정
Adam 옵티마이저를 설정하고, 모델의 정확도 계산을 위한 메트릭을 정의한다. Adam 옵티마이저를 설정하고, 그 옵티마이저를 사용하여 손실 함수(xentropy)를 최소화하는 학습 연산(train_op)을 정의한다.
모델의 예측(logits)과 실제 레이블(labels)을 비교하여 각 예측이 가장 높은 확률을 가진 클래스 중 하나인지를 판단한다. tf.nn.in_top_k 함수는 각 예측이 상위 K개 중에 포함되는지 여부를 검사하며, K=1로 설정하여 가장 높은 확률을 가진 클래스와 실제 레이블을 비교한다. correct에서 얻은 불리언 값(True or False)을 부동 소수점 형식으로 변환 후, 이의 평균값을 계산하여 정확도(accuracy)를 구한다. 이 정확도는 모델의 예측이 실제 레이블과 얼마나 일치하는지를 나타내며, 모델의 성능 평가에 사용된다.
(10) 모델 학습
Tensofrlow 세션을 열고, 그래프를 초기화한다. 에포크를 반복하면서 미니배치 학습을 수행하고, 정확도와 손실을 출력한다. 이 코드는 모델을 훈련하고 훈련 과정 동안 정확도와 손실을 모니터링하는 부분이다. TensorFlow 세션을 생성하고 sess 변수에 할당한다. 참고로 with 문을 사용하면 세션을 자동으로 정리하고 리소스를 해제한다. 모든 전역 변수를 초기화하는 tf 연산을 실행 후 에포크 수만큼 반복하는 루프를 시작한다.
이 for문 내에서 모델이 학습된다. 미니배치 단위로 데이터를 모델에 입력하고, 모델을 훈련하는 핵심 단계!
마지막으로 현재 에포크에서의 훈련 정확도(acc_batch), 검증 정확도(acc_valid), 미니배치 손실(loss_batch) 값을 출력하여 훈련 과정을 모니터링한다.
3. Result
이 코드는 RNN을 사용하여 MNIST 데이터 세트의 이미지를 학습하는 모델을 구현한 것이다. 다시 말해 이 모델은 MNIST 숫자 이미지를 입력받아 이미지에 포함된 숫자를 인식하고 분류한다. 이미지를 순차적으로 처리하기 위해 이미지를 시간 단계별로 입력받는다. 구체적으로 코드에서는 RNN셀로 Basic RNN 셀을 사용하고, MNIST 이미지를 28x28 크기의 픽셀 시퀀스로 간주하여 입력한다. 그다음 RNN 모델은 이미지 시퀀스를 처리하고 출력 레이어로 이동하여 숫자 분류를 수행한다. 이 과정에서 모델은 이미지에 나타난 숫자를 예측하고 학습한다.

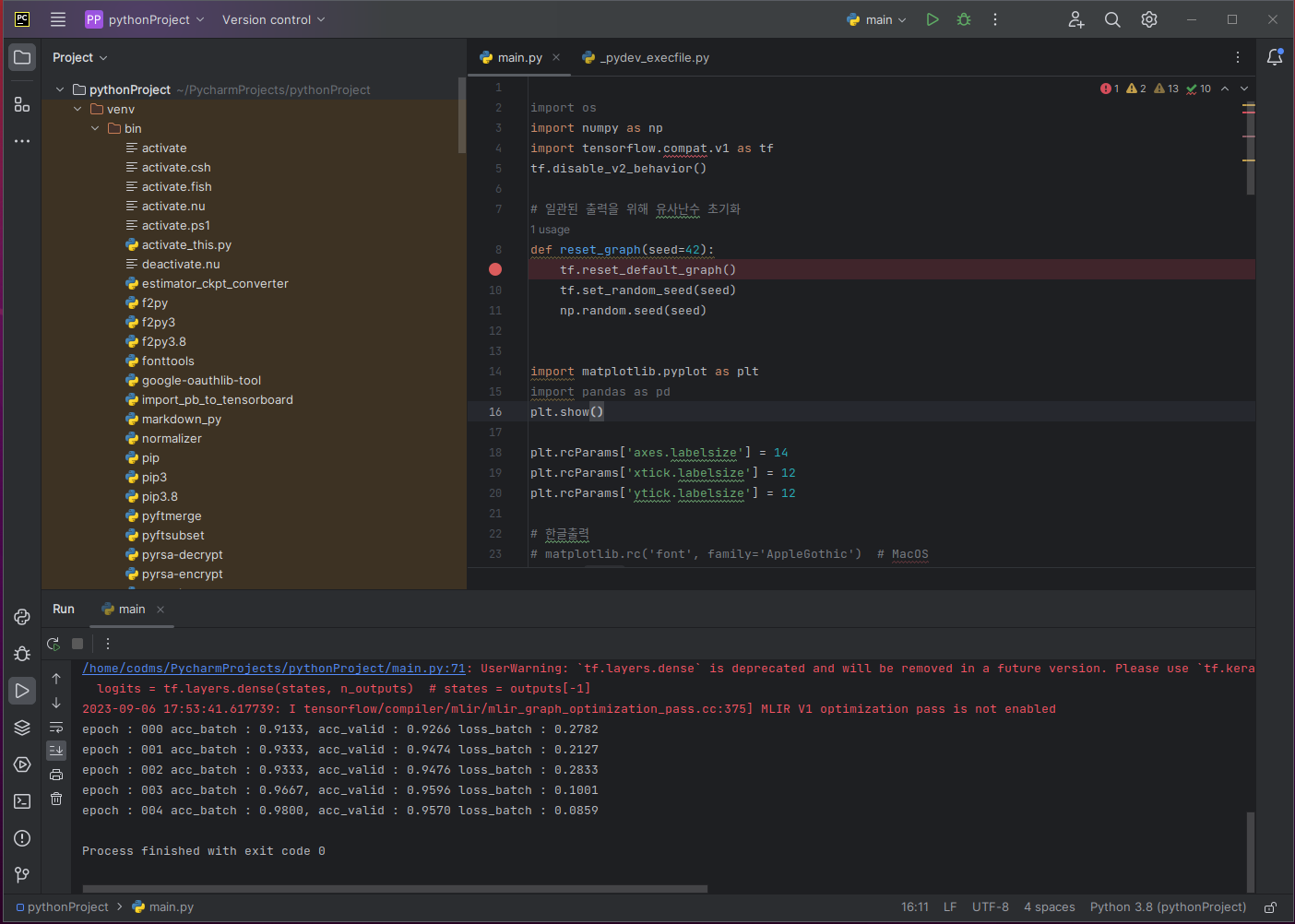
빨간줄과 별개로 결과값이 잘 나옴을 알 수 있다.
https://www.codeit.kr/community/questions/UXVlc3Rpb246NjFmMTQyOTkzMWQ3ZjU3MTM5MTQ3ZWJj
and this : https://excelsior-cjh.tistory.com/184
'LAB > AI' 카테고리의 다른 글
| 딥러닝(3) 파이썬, 텐서플로 : 코드 위주 (0) | 2024.01.17 |
|---|---|
| 딥러닝(2) 인공신경망의 구조와 연산 : 이론 위주 (0) | 2024.01.17 |
| 딥러닝(1) 인공지능의 분류, 지도 학습 구현 기법 (2) | 2024.01.17 |
| 딥러닝(5) 실습: LSTM 코드 (0) | 2023.09.04 |
| 딥러닝(4) ANN, DNN, CNN, RNN 개념과 차이 (0) | 2023.08.18 |



